
在计算机的世界里,我们看到的所有内容 —— 无论是文字、符号还是表情 —— 本质上都是一串串由0和1组成的二进制数字
那么一个我们能看懂的、有意义的符号,是如何被计算机存储,又是如何被准确无误地显示出来的呢?
这个过程就是我们今天要讲述的关于“字符”的完整故事
基础概念:字符、字形、字节与字
要理解后续的一切,我们必须先精确区分几个最基本的概念:
- 抽象的语义单位 —— 字符(Character)
- 具象的视觉单位 —— 字形(Glyph)
- 计算机的物理存储单位 —— 字节(Byte)
- 以及容易混淆的“字”——计算机的字(Word) 与 人类语言的字
字符(Character)
字符,是一个抽象的、信息的基本语义单元,是我们用来表达意义的最小符号
-
英文字母
A、b、c是字符 -
数字
1、2、3是字符 -
标点符号
.、?、!是字符 -
汉字
中、国、人是字符 -
表情符号
😂、👍也是字符!
在这个层面,字符是无形的,它只关乎“是什么”,而不关乎“长什么样”或“如何存储”
字形(Glyph)
字形,是字符的具体视觉表现形式,是我们真正在屏幕上看到的那个“形状”
一个字符可以有多种不同的字形:
- 字符“拉丁字母A”可以有
A(正常),A(粗斜体),𝔸(空心) 等多种字形 - 同一个汉字“骨”,在宋体、楷体、草书中的字形也完全不同。
反过来,多个字符也可能组合成一个字形(这被称为“合字”或“连字”,Ligature):
- 在某些英文字体中,字符
f和i相邻时,会合并成一个单独的fi字形,以避免f的钩与i的点碰撞。
简单说:字符是“骨”,字形是“皮肉”。我们操作和存储的是字符,而最终渲染出来给人看的是字形。
字节(Byte)
字节,是计算机中数据存储和处理的基本单位
- 一个字节由8个比特(bit)组成,每个比特非0即1
- 一个字节能表示2⁸=256种不同的状态(0-255)
字(Word)
计算机的“字”与人类的“字”毫无必然联系
计算机中的“字”(Word)
在计算机科学中,字(Word)是CPU处理数据的自然单位,是计算机一次性读取、处理或传输的最小数据块
字的大小依赖于计算机架构:
- 16 位系统的一个字是 2 个字节(16 位)
- 32 位系统的一个字是 4 个字节(32 位)
- 64 位系统的一个字是 8 个字节(64 位)
在汇编语言和系统底层编程中,“字”是非常重要的基本数据宽度概念
人类语言中的“字”
在人类语言里,“字”指的是一个书写符号单位:
- 在中文里,“字”通常是一个汉字,例如
中、国 - 在英文里,没有严格对应的“字”概念,通常用
letter(字母)或word(单词)描述 - 在日语里,一个“字”可能是汉字、平假名、片假名中的任意一个符号
在大多数情况下,人类语言里的“字”可以看作是一个字符,但它们并不是严格等同的概念
我们可以认为一个英语单词是一个“字”,但它却是多个“字符”的组合
那么此时,矛盾就出现了:
世界上有成千上万个抽象的“字符”,而计算机的基本存储单元“字节”一次只能表示256种状态!
这就需要建立一套完整的映射体系,才能让所有字符都能在计算机上显示
字符集
为了让计算机能够处理字符,人们首先需要做一件事:
把世界上所有的字符收集起来,排个队,给每个字符分配一个独一无二的编号
字符集,就是这样一个“字符的集合”以及“字符与编号的对应表”。可以把它想象成一本为全世界所有字符编写的巨大“字典”,而对应的编号,我们称之为码点
字符集本身只是一套标准、一个“名册”,它只规定了“哪个字符对应哪个数字”,但还没有规定这个数字具体应该如何在计算机中用字节来存储
字符集的历史演进与兼容性问题
ASCII时代
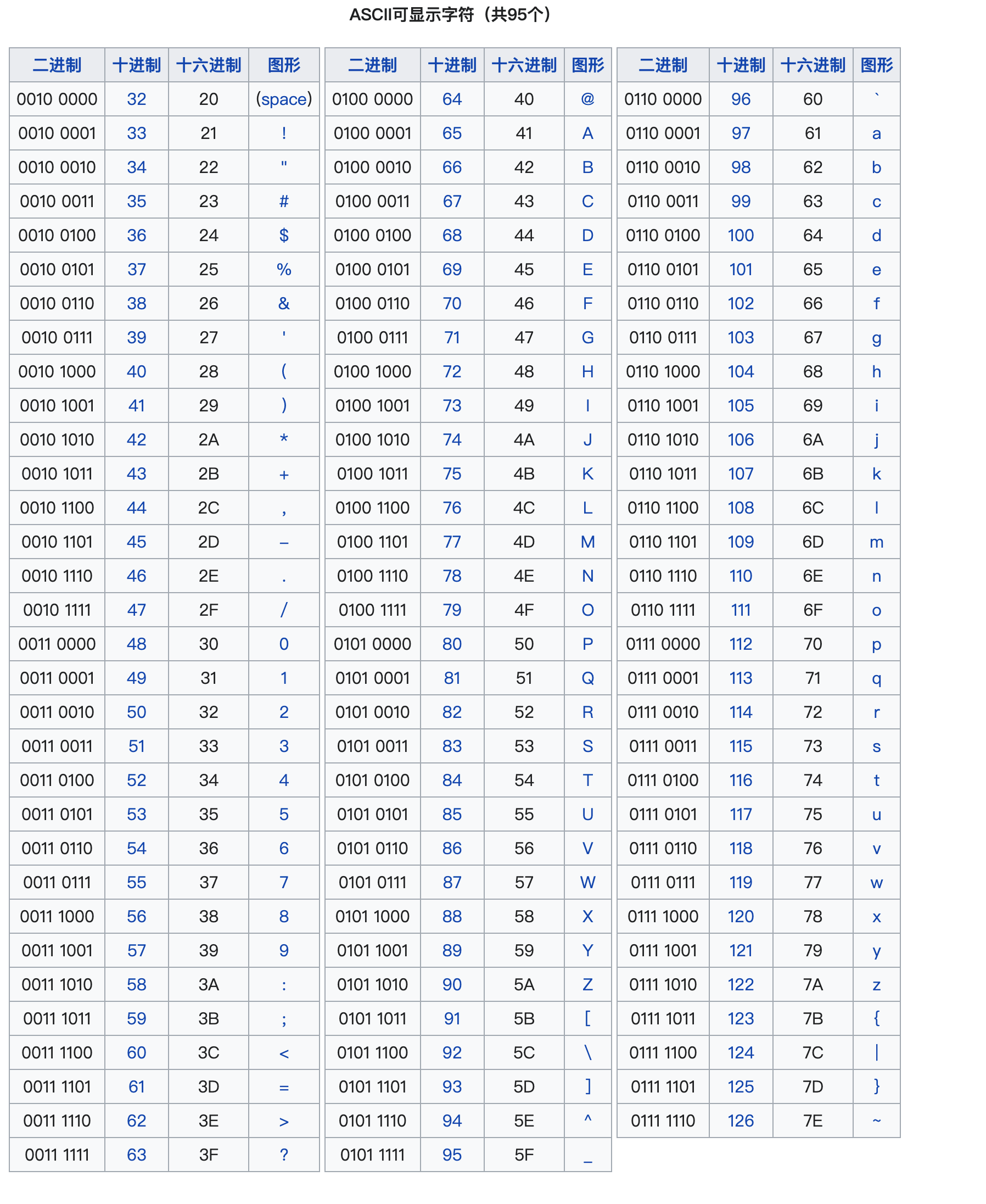
计算机诞生于美国,最早的ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)字符集是为英语环境量身定做的
它收录了128个最常用的字符,包括:
-
95个可打印字符:大小写英文字母(
A-Z,a-z)、数字(0-9)、以及各种标点和符号(!,@,#等) -
33个不可打印的控制字符:如回车(
CR)、换行(LF)、制表符(Tab)等,用于控制打印机等设备 -
它的码点范围是0到127,所以用一个字节(0-255)来存储一个ASCII 字符绰绰有余
实际上,ASCII码只用到了一个字节(8个比特)中的低7位,最高位始终为0
例如,字符
'A'的码点是 65,其二进制表示为01000001这个“最高位为0”的特性,为后来的扩展埋下了伏笔
ASCII码现在依然在被广泛使用,你可以在很多编程语言里面见到它,而且可以说它是现代字符编码体系的根基
地区性字符集时代
当计算机走向世界,问题出现了:
欧洲需要 é, ü,中国需要汉字,日本需要假名,单一的 ASCII 远远不够用!
于是,世界各地纷纷利用ASCII留下的“遗产”—— 那个未被使用的最高位比特0,来扩展自己的字符集
当一个字节的最高位是0时,它仍然表示一个标准的ASCII字符
当最高位是1时,它就进入了各个地区自定义的“扩展区”(码点范围 128-255)
下面是一些比较有代表性的编码方案吗,我们后面还会详细说明:
-
ISO-8859-1 (Latin-1)
面向西欧,它利用了128-255的码点来表示带音标的字母,如
é、ü、©等 -
GB2312/GBK
面向中国大陆,由于汉字数量远超128个,它采用双字节编码方案
当检测到一个字节的最高位是1时,就认为它和紧随其后的下一个字节共同表示一个汉字
GBK是GB2312的扩展,收录了更多汉字 -
BIG5
面向中国台湾地区,同样是双字节方案,用于表示繁体字
-
Shift_JIS
面向日本,是一个更复杂的变长编码方案,用于表示日文汉字和假名
虽然这样方便了各个地区的用户,但也是之后乱码问题出现的罪魁祸首
Unicode时代
为了终结大家各用各的这种混乱,Unicode应运而生
它的目标是“天下书同文”,它不是要创造又一个与其它标准竞争的字符集,而是要统一和包容所有字符!
也就是说,它要为地球上每一种语言的每一个字符都分配一个全球唯一的码点!
这一伟大的工程应该造福了全人类·,所以我们也叫他统一码/万国码
Unicode码点的标准表示方法是用U+十六进制数字来表示:
- 汉字
中的Unicode码点是U+4E2D - 表情
😂的Unicode码点是U+1F602
你也可能看到另一种方法:\u+十六进制数字,这是编程语言中的转义字符表示法:
- 汉字
中的Unicode转义字符是\u4E2D - 表情
😂的Unicode转义字符是\u1F602
如何存储如此庞大的字符量呢?
Unicode标准码点范围是从U+0000到U+10FFFF,共计约1,114,112个码点
这些码点被划分成17 个平面(Planes),每个平面包含65536(即 2¹⁶)个码点:
-
基本多文种平面(BMP, Plane 0)
包含了从
U+0000到U+FFFF的码点,涵盖了世界上绝大多数常用字符,包括常用汉字 -
辅助平面(Supplementary Planes, Plane 1–16)
包含了从
U+010000到U+10FFFF的码点,用于表示生僻字、古代文字以及各种符号,比如Emoji表情
从此,无论在哪个国家、哪个平台,U+4E2D永远只代表中这一个字符
字符集标准组织
制定这些标准的是一些国际组织,其中最重要的是:
-
Unicode联盟(Unicode Consortium)
一个非营利组织,其成员包括苹果、谷歌、微软、Adobe等各大科技巨头。它负责开发、维护和推广Unicode标准,包括我们日常使用的Emoji表情的标准化
-
国际标准化组织(ISO)
它也发布了与Unicode对应的 ISO/IEC 10646 标准,基本上可以认为Unicode和 ISO/IEC 10646 是同一个字符集标准的不同名称
至此,我们通过字符集,成功地将所有抽象的字符转化为了全球统一的数字(码点)
一个极其重要的问题:
Unicode本身只定义了码点,它并没有规定这个号码在计算机中应该如何用字节来存储!
编码
现在我们有了“字符”和“码点”的对应关系(字符集),但还有一个最关键、最实际的问题没有解决:
如何将这些码点(数字),特别是那些大于 255 的庞大数字,高效地用计算机唯一懂的语言来表示?
答案是编码 —— 将字符的码点(数字)翻译成字节序列(物理存储)的具体规则
如果说字符集是字典,那编码就是语法规则,它教我们如何用字节来书写字典里的每一个页码(码点)
编码格式
在编程领域,为了处理非ASCII字符,历史上形成了两种截然不同的解决思路
多字节字符集 (MBCS - Multi-byte Character Set)
这是一种“让程序变聪明”的编码层面解决方案
字符串在内存中仍然以char数组的形式存放,但程序在处理时,必须“意识到”这个字节序列采用了某种特定编码(如 GBK)
比如,对于C语言字符串 "你好",在GBK编码下,它占4个字节
strlen("你好")会返回4,因为它只认识字节- 而一个特殊的、能识别多字节的函数
mbstrlen("你好")则会返回2,因为它知道两个字节才构成一个汉字
这种方式处理起来非常复杂且极易出错,因为我们不能再想当然地通过str[i]来访问第i个字符 —— str[i]可能只是一个汉字的前半部分!字符串的截取、遍历和修改都变得困难了!
宽字符 (Wide Character)
这是一种“让数据类型变强大”的数据类型层面解决方案
它不再让程序去适应复杂的字节流,而是定义了一个新的、足够宽的数据类型,这个类型通常是2或4个字节
比如我们在C++中定义一个这样的宽字符wchar_t类型:
wchar_t* wide_str = L"你好";
wide_str数组的每个元素都能完整地存放一个字符的码点,而L前缀告诉编译器,这个字符串用宽字符存储,不是普通的char字符串
wide_str[0]就是字符你,wide_str[1]就是字符好,数组长度为2
这让字符串的索引和遍历恢复了简单
他也有不少缺点:
-
空间浪费
即使是存储纯英文 “hello”,每个字符也要占用2或4个字节,造成空间浪费
-
跨平台困难
虽然很难以置信,但
wchar_t的具体大小在不同主流操作系统上并不统一!在 Windows 上它通常是 2 字节(对应 UTF-16),而在 Linux 和 macOS 上它通常是 4 字节(对应 UTF-32),这使得依赖
wchar_t的代码难以跨平台移植!
+++
正是因为这两种早期方案都有明显的缺陷,现代编程实践大多推荐直接使用UTF-8编码的普通char字符串,并配合专门、可靠的库(如 ICU)来处理复杂的字符串操作
至于什么是UTF-8编码,我们接着往下看
编码方式
ASCII编码
最简单的编码,码点值就是字节值
字符'A'的码点是 65,其编码就是一个值为 65 的字节
GBK编码
GBK的全称是国标扩展码拼音“Guóbiāo Kuòzhǎn”的缩写
这是一种典型的多字节编码(MBCS),解码时检查一个字节的最高位:
- 如果为
0(0-127),则它本身就是一个单字节的ASCII字符 - 如果为
1(128-255),则它必须和紧随其后的下一个字节共同组成一个双字节的汉字
UTF-8编码(现代标准)
这是现代互联网的基石,它是一种针对Unicode的、可变长度的字符编码,其设计堪称精妙绝伦
它兼容ASCII编码:对英文字母和数字用1个字节编码,与ASCII完全一样,这意味着一个纯英文的ASCII文件,本身就是一个合法的UTF-8文件,无需任何转换
它对不同字符有不同字节规定:对拉丁文、希腊文用2字节;对常用汉字用3字节;对罕见字符和表情用4字节
UTF-8通过每个字节开头的几个比特来标记这个字符的长度:
0xxxxxxx: 单字节,表示U+0000到U+007F(ASCII)110xxxxx 10xxxxxx: 双字节,由一个110开头的字节和个10开头的字节组成1110xxxx 10xxxxxx 10xxxxxx: 三字节,由一个1110开头的字节和两个10开头的字节组成11110xxx 10xxxxxx 10xxxxxx 10xxxxxx: 四字节
具体对应关系如下:
| Unicode 范围 (十六进制) | UTF-8 字节序列 (二进制) | 字节数 | 常见语言/用途举例 |
|---|---|---|---|
U+0000 - U+007F |
0xxxxxxx |
1 | 英语(基本拉丁字母)、数字、ASCII 标点、控制字符 |
U+0080 - U+07FF |
110xxxxx 10xxxxxx |
2 | 拉丁文扩展(é ñ 等)、希腊文、俄语西里尔字母、希伯来文、阿拉伯文 |
U+0800 - U+FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
3 | 东亚文字(中文、日文假名、韩文音节)、越南文、泰文、天城文(印地语等)、大部分表情符号 |
U+10000 - U+10FFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
4 | 罕见/扩展字符(CJK 扩展汉字、古代文字、乐谱符号、更多表情符号) |
这些x是实际用来填充字符码点二进制位的地方,从右向左、从低位到高位填充
eg:汉字“中” (U+4E2D)
- Unicode 码点:
U+4E2D - 范围:
4E2D在U+0800-U+FFFF之间,所以需要 3 个字节 - 二进制表示:
4E2D的二进制是0100 1110 0010 1101(16位) - 匹配模板:三字节模板是
1110xxxx 10xxxxxx 10xxxxxx。这个模板共有4+6+6=16个x,正好容纳16位 - 填充
- 最右边的6个
x填入最低的6位:001101 - 中间的6个
x填入接下来的6位:111000 - 最左边的4个
x填入最高的4位:0100
- 最右边的6个
- 得到字节序列
1110 0100->E410 111000->B810 001101->AD
- 结果:汉字“中”的UTF-8编码是**
E4 B8 AD**
这种设计确保了程序在任何位置开始读取字节流,都能准确判断出一个字符的起始和结束边界
UTF-16 编码
UTF-16也是一种用于编码Unicode字符的格式
它通常使用2个字节(对于BMP内的字符)或4个字节(对于辅助平面的字符)来表示一个字符
由于其大部分情况下定长的特性,便于程序内部进行索引,因此被广泛用作许多系统和语言的内部内存表示,例如Windows操作系统内核、Java语言的String类型
UTF-32 编码
类似UTF-16,它也是定长的,为每一个字符分配固定的4个字节(32位)来存储其Unicode码点值
它和UTF-16一样,在文件存储和网络传输方面不如UTF-8流行,一个主要原因就是接下来要讲的字节序问题
字节序
当一个字符需要用多个字节来表示时,就必须面对一个问题:
这些字节应该按什么顺序存储?就像写数字258,是从左到右写 2, 5, 8,还是从右到左写8, 5, 2?
这也就是所谓的字节序 —— 多字节数据在内存或文件中按字节排列的顺序
UTF-8的编码规则中,字节内部的位顺序是固定的,没有所谓“高字节”和“低字节”的问题;而UTF-16和UTF-32是定长的,而且字节内部可以交换顺序,所以会有字节序区别
常见的两种字节序:
-
大端序 (Big-Endian, BE):高位的有效字节存放在内存的低地址(大头在前)
这符合人类的阅读习惯
-
小端序 (Little-Endian, LE):低位的有效字节存放在内存的低地址(小头在前)
这在 x86 架构的计算机(我们日常使用的大多数 PC)中更为常见
比如,字符 中的UTF-16编码 (U+4E2D) 是两个字节4E和2D:
- 在大端序系统上,内存中存储为:
... [地址1000]: 4E, [地址1001]: 2D ... - 在小端序系统上,内存中存储为:
... [地址1000]: 2D, [地址1001]: 4E ...
如果搞错了字节序,解码就会出错!
为了解决这个问题,人们发明了BOM(Byte Order Mark),它是一个放在文件开头的、不可见的特殊暗号字符(码点为 U+FEFF)
通过读取文件开头的几个字节,以BOM为参考,程序就可以判断文件的字节序和编码:
- 如果文件开头是
FE FF,说明是UTF-16 大端序 - 如果文件开头是
FF FE,说明是UTF-16 小端序 - 如果文件开头是
EF BB BF,说明是UTF-8
正如前面所说,UTF-8本身没有字节序问题,它的BOM只是用来表明这是一个UTF-8文件
然而,在Web开发和类Unix系统中,普遍推荐使用不带 BOM 的 UTF-8(UTF-8 without BOM),因为某些旧的脚本和工具可能不认识 BOM,并将其作为垃圾内容输出,导致页面顶部出现空行或其他问题
理解了前面的字符集和编码,乱码的产生原因就非常清晰了
乱码
乱码的唯一根源在于:用 A 编码方式存储的字节序列,却被当作 B 编码方式去解码和显示。
这就像你拿到一份用中文密码本加密的信息,却错误地拿了一本俄文密码本去解密,结果自然是一堆谁也看不懂的天书
字节本身是无辜的,它们只是一串0和1,真正的罪魁祸首是解码时错误的假设
错误的翻译 —— GBK打开UTF-8文件
这是最常见的场景:我们用国际标准的UTF-8创建了文件,但它被一个只认识本地编码的旧程序打开了
我们用 Python 写入一句话“你好,世界”,并明确使用utf-8编码保存,查看它UTF-8编码字节
text = "你好,世界"
utf8_bytes = text.encode('utf-8')
with open("utf8.txt", "wb") as f:
f.write(utf8_bytes)
print(utf8_bytes.hex().upper())
输出:
E4BDA0E5A5BDEFBC8CE4B896E7958C
我们再模拟一个旧程序用gbk编码去读取这个hello_utf8.txt文件:
with open("utf8.txt", "rb") as f:
byte_data = f.read()
#errors='replace' 表示遇到无法解码的字节时,用 '' 替换
garbled_text = byte_data.decode('gbk', errors='replace')
print(garbled_text)
输出:
浣犲ソ锛屼笘鐣�
这就是典型的乱码,因为utf-8下的E4BDA0...这串字节在GBK的字典里恰好对应了另一组完全不同的汉字
“锟斤拷”
这个著名的乱码组合,就是源于将UTF-8编码的汉字,错误地用 GBK 或其他本地编码来显示
它的成因非常特殊,它源于对“错误”本身的再次错误解读
替换字符
这个故事的主角,是一个特殊的Unicode字符 —— 替换字符
当一个程序在解码字节流时,如果遇到了一个不符合当前编码规则的、无法识别的无效字节序列,该怎么办?
一个设计良好的程序不会崩溃,而是会遵循Unicode标准,在那个出错的位置插入一个官方的替换字符,也就是**U+FFFD**,它在屏幕上通常显示为一个黑色的菱形中间带一个问号
错误的诞生
现在,让我们用代码来模拟它的产生过程:
假设一个程序(比如数据库、文本编辑器等)在处理数据时,遇到了它无法理解的字节,作为安全措施,程序在内存中生成了两个Unicode替换字符,我们在Python中可以直接用它的码点 \uFFFD 来表示:
error_text = "\uFFFD\uFFFD"
接下来,程序将包含这两个替换字符的字符串,以标准的UTF-8格式写入文件,一个U+FFFD的UTF-8编码是 3个字节:EF BF BD
utf8_error = error_text.encode('utf-8')
现在,另一个程序(或用户)错误地使用 GBK 编码来读取这串字节,注意这里必须用 gbk 编码,如果用 gb2312会因字符不全而报错:
text = utf8_error.decode('gbk')
print(f"GBK解码结果: '{text}'")
结果:
锟斤拷
其中过程是怎么样的?
- 程序读取
EF BF BD EF BF BD这6个字节 - GBK 解码器按两个字节一组来处理,因为它认为最高位是
1的字节都是双字节字符的一部分:- 读到**
EF BF,去查GB码表,这对字节恰好对应了汉字锟** - 接着读到**
BD EF,再次去查GBK码表,这对字节也恰好有对应汉字斤** - 最后读到**
BF BD,第三次去查GBK码表,这对字节同样对应了一个汉字拷**
- 读到**
- 就这样,原本代表解码错误的、在UTF-8下有明确含义的字节序列,在 GBK解码器的一系列巧合误解之下,被翻译成了我们在座各位都无比熟悉的三个汉字——
锟斤拷
锟斤拷是传播比较广泛的乱码,真正的乱码形式多种多样,网上有人整理了常见的乱码对照表:
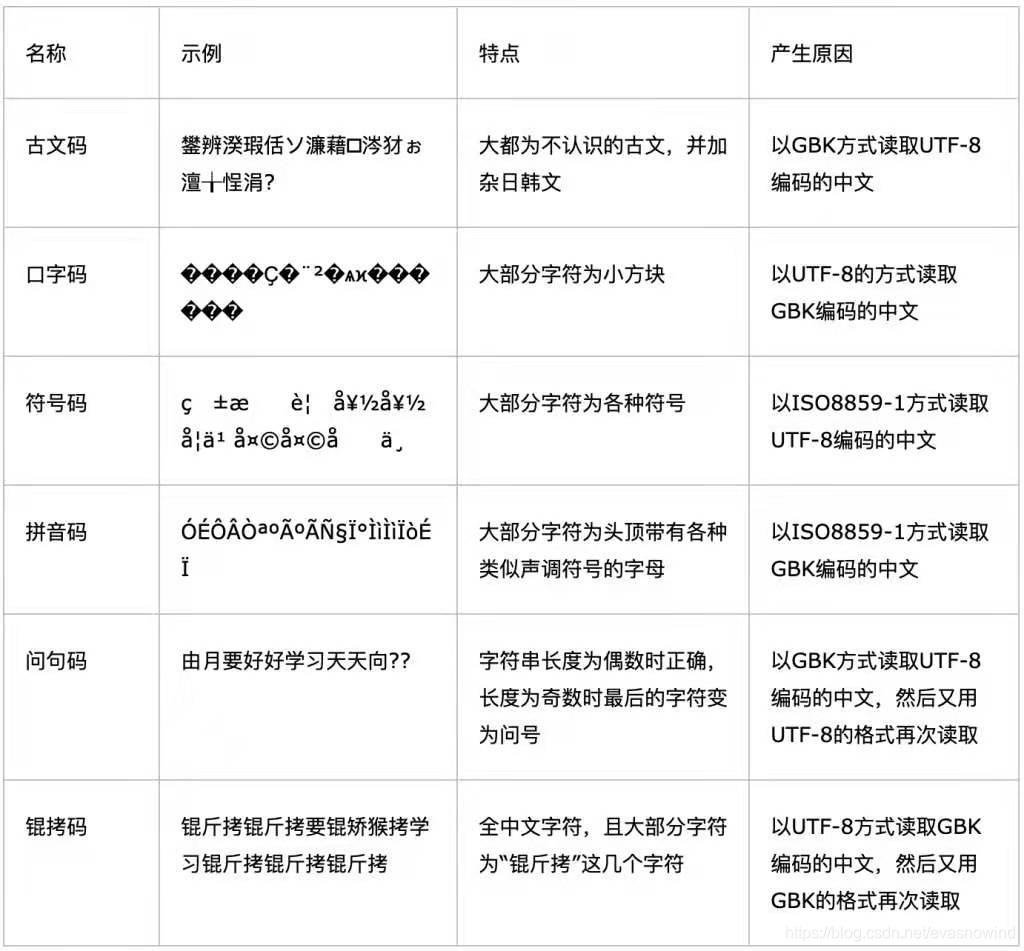
如果你不记得什么是ISO-8859-1:地区性字符集时代
表里面提到锟拷码是gbk读取两次的结果,其实就是utf-8 ->错误字符 -> 替换字符 -> 锟斤拷
无能的编码检测
既然乱码是因编码不匹配产生的,那程序能自动检测文件的编码吗?
答案是可以,但永远不可靠
编码检测本质上是一种启发式猜测,线索极少
程序会读取一部分字节,然后用各种常见编码的规则去试,并根据以下线索进行打分:
-
BOM (Byte Order Mark)
这是最可靠的线索,如果文件开头有
EF BB BF,那几乎可以100%确定是UTF-8但我们上面也说过了,绝大多数文件(特别是网页)为了兼容性,并不带BOM
-
无效字节序列
编码有其严格的字节组合规则,如果在尝试用GBK解码时,出现了大量不符合其双字节规则的序列(像上面例子中的单个
0xAA),那么程序就会认为这可能不是GBK -
统计学特征
分析字节的分布规律,例如,一段英文文本如果用UTF-8编码,大部分字节都会在0-127范围内。而一段中文GBK文本,则会出现大量连续成对的大于127的字节
然而,这种方法是不可靠的:
-
对于短文本,样本太少,统计学方法完全失效
-
巧合时有发生,有些字节序列在多种编码下恰好都是“合法”的,只是代表的意义不同
在早期的windows版本中,如果使用写字板打开txt文件,输入“联通”两个字,此时是以GBK形式保存,但由于他们的编码恰好和utf-8的双字节格式相同(比如“联”是
C1AA,即1100000110101010),阅读器错误的使用utf-8解码它们,就会导致乱码还有一个著名的例子就是短语
Bush hid the facts,这也是一个在中文Windows系统上曾广为人知的文本显示乱码,当它以ASCII/UTF-8保存后,如果被程序错误地当作UTF-16LE来打开,会显示出几个汉字联 আরি或类似乱码
所以,永远不要依赖自动检测!
与其让接收方去费力猜测,不如让发送方在明确标注语言,现代协议和格式都会提供这种明确指定编码的机制
例如:
HTTP响应头:服务器在返回网页时,通过这个头信息告诉浏览器用什么编码来解析
Content-Type: text/html; charset=utf-8
HTML文件头:在HTML文件内部,通过meta标签再次声明编码,作为服务器未发送上述头信息时的备用方案
<meta charset="UTF-8">
XML文件头:XML文件在第一行就声明自己的编码
<?xml version="1.0" encoding="UTF-8"?>
说完了基础的,我们来说点高级的 —— 其实,Unicode远比“一个码点一个字”要复杂
除了我们看得见的字符,还存在一套系统,用于处理字符的等价性问题、组合显示以及控制文本的复杂行为
字符的变形
同形异义
同一个看起来一样的字符,在Unicode中可能有多种表示方式,这在计算机看来就是完全不同的东西
比如一个带扬抑符的字母é,它就有两种表示方式:
-
方式1 —— 预组合
直接使用单个码点
U+00E9(é),就像一个现成的汉字一样 -
方式2 —— 组合
使用普通字母
e(U+0065),后面紧跟一个“组合扬抑符”´(U+0301)这就像汉字的一个偏旁部首,会自动“贴”到前一个字母的身上,组合成需要的样子
这两种方式渲染出来的字形完全一样,但在计算机内部,它们的身份是完全不同的
如果你在一个文本中搜索 U+00E9,将无法匹配到由U+0065 + U+0301组成的那个é
历史渊源
你可能会奇怪为什么它会以两种方式存在,这其实和Unicode在设计时要兼顾的两个目标有关:
-
兼容性 在 Unicode 出现之前,许多老字符集(如 Latin-1)已经有
é这种“预组合”的单个字符为了兼容旧标准,Unicode 直接收录了这些单字符形式(U+00E9)
-
可组合性 Unicode 希望支持所有语言的所有字符变化(比如加不同的重音、附加符号、数学标记等),但如果每种变化都单独收一个码点,字符集会无限膨胀
所以,Unicode 定义了组合字符(Combining Characters)机制,允许用一个基本字母 + 一个或多个附加符号来动态组合成新字形(比如
U+0065+U+0301)
归一化标准
为了解决这个问题,Unicode 定义了四种归一化标准,用于将“看起来一样但编码不同”的字符串转换为统一的、规范的表示形式
-
NFC (Normalization Form C – Composition):组合
先将字符分解,再尽可能组合为预组合形式(比如
e+´→é)这是 W3C 推荐在网页存储和传输中使用的标准,能够保证跨平台一致性
-
NFD (Normalization Form D – Decomposition):分解
将字符尽可能分解为基本字符和组合标记(比如
é→e+´)这种形式常用于需要分析字符结构或对附加符号单独处理的场景
-
NFKC (Normalization Form KC – Compatibility Composition):兼容性组合
在NFC的基础上,先进行兼容性分解(把全角字符、特殊样式字符等转换为标准字符),再尽可能组合
例如,
Hello(全角)会被转成Hello适合搜索、匹配、用户输入标准化等场景
-
NFKD (Normalization Form KD – Compatibility Decomposition):兼容性分解
在NFD的基础上,额外进行兼容性分解,将外观差异但语义等价的字符统一为标准形式,并保持分解状态
例如,罗马数字
Ⅳ会被分解为I+V常用于文本分析、去除装饰性差异等任务
前两种是比较常用的归一化方式
特殊字符
Unicode中包含很多“看不见”但有特殊功能的字符,我们上面提到的用作BOM的就是其中一种
零宽字符
看不见的字符
它们不占用任何宽度,肉眼不可见,但能产生特殊效果
-
零宽空格 (ZWSP, U+200B)
它用于在长单词或 URL 的中间建议一个“可以换行”的位置,而不会产生一个可见的空格
例如,在 URL
thisisaverylongurlthatmightoverflow中间插入 ZWSP,当容器宽度不够时,浏览器就可以在这里优雅地换行,而不会破坏链接 -
零宽连字 (ZWJ, U+200D)
它用于“粘合”两个独立的字符,告诉渲染引擎将它们显示为一个组合的字形
最著名的应用就是 Emoji 的组合:
👨(男人) +ZWJ+👩(女人) +ZWJ+👧(女孩) +ZWJ+👦(男孩) =👨👩👧👦(家庭)(零宽连字) 本身不可见,但它像胶水一样把前后四个独立的 Emoji 粘合成了一个新的 Emoji -
零宽非连字 (ZWNJ, U+200C)
与 ZWJ 相反,它用于“切断”本应自动连接的字符
例如,在波斯语中,某些字母会自动与后面的字母连接,插入 ZWNJ 可以强制它们断开,以显示其非连接形式
-
从左到右标记 (LRM, U+200E)
一个不可见字符,用来强制后续字符以从左到右显示
常用于混合方向文本中,确保英文或数字按正常方向显示。例如,在阿拉伯语句子中插入 LRM 可以保证英文单词正常显示。
-
从右到左标记 (RLM, U+200F)
类似 LRM,但强制后续字符以从右到左方向显示
常用于拉丁字母或数字出现在阿拉伯语或希伯来语文本时,保证它们正确的右到左排列
-
从左到右嵌入 (LRE, U+202A)
它开始一段左到右的文本嵌入,后续字符强制从左到右显示,直到遇到对应的结束符
在主要是阿拉伯语的文本中插入LRE和PDF,可让一段英文保持左到右排列
-
从右到左嵌入 (RLE, U+202B)
它开始一段右到左的文本嵌入,后续字符强制从右到左显示,直到遇到结束符
在主要为英文的文本中插入RLE和PDF,使其中一段希伯来语正常右到左排列
-
弹出方向格式 (PDF, U+202C)
它用来结束先前的方向嵌入(LRE或RLE),恢复之前的文本方向
例如:文本中出现LRE…PDF或RLE…PDF包裹的区域,PDF结束该嵌入状态
-
从左到右覆盖 (LRO, U+202D)
它强制后续字符全部以从左到右方向显示,覆盖其默认方向,直到遇到PDF
例如:在包含阿拉伯语或希伯来语的混合文本中,强制某一部分以从左到右显示
-
从右到左覆盖 (RLO, U+202E)
与LRO相反,强制后续字符全部以从右到左方向显示,覆盖默认方向,直到遇到PDF
这在恶意文本或混淆攻击中经常被用来制造视觉欺骗,因它会反转文字显示方向
-
不可见乘号 (INVISIBLE TIMES, U+2062)
表示数学隐式乘法操作,但不显示任何符号,常用于数学公式排版,变量间的隐式相乘
-
不可见分隔符 (INVISIBLE SEPARATOR, U+2063)
用作文本逻辑分隔符,但不显示任何空白或符号,方便文本内部逻辑处理
-
零宽不间断空格 (ZWNBSP, U+FEFF)
既是零宽的不可换行空格,也常用于Unicode文档的字节顺序标记(BOM)
在文件开头可标识文本编码,但不应随意插入文本中,以免引起显示问题
QQ的反转id
相信不少人都看见过qq群里有些人的id后面会跟着一个“喵”之类的恶搞字符
当你@他时,这个字符竟然脱离了id,出现在了我们输入的话后面!这怎么回事?
其实这就是使用了上面我们提到的零宽字符的两种:
U+202E:从右至左覆盖U+202D:从左至右覆盖
比如,我有一个id是这样的:
快来艾特我\u202E喵~\u202D
因为是不可见字符,在别人眼里是看不见的(需要使用对应的编码工具,比如:unicode编码转换 ):
快来艾特我喵~
当别人@我发言的时候(比如说“你好”,显示应该是@快来艾特我喵 你好),文字显示默认从左向右
我们使用[]代表当前输入光标的位置,左右箭头代表输入方向:
[]→
@[]→
@快[]→
@快来[]→
@快来艾[]→
@快来艾特[]→
@快来艾特我[]→
读取到这里的时候,文本框看见了控制字符U+202E,它立刻变成了从左向右输入:
@快来艾特我←[]
@快来艾特我←[]喵
输入“喵”后,他又看见了控制字符U+202D,又变回了从右向左输入:
@快来艾特我[]→喵
@快来艾特我你[]→喵
@快来艾特我你好[]→喵
输入完成之后最终效果:
@快来艾特我你好喵
这就让别人喵喵叫啦
零宽字符隐写
这种零宽字符还诞生了一种隐写方式 —— 零宽字符隐写(Zero-Width Character Steganography)
隐写技术通过在正常文本的字符间插入零宽字符,或者利用不同零宽字符的组合,来编码隐藏信息
例如,用零宽空格代表二进制的0,零宽非连接符代表1,或者通过插入或不插入零宽字符表示二进制位
这样,隐藏的信息不会被普通阅读者察觉,因为文本外观没有变化
你可以使用linux的vim编辑器打开,观察到\u这样的隐写痕迹
常用的隐写工具:
https://330k.github.io/misc_tools/unicode_steganography.html
https://yuanfux.github.io/zero-width-web/
变体选择符
变体选择符是一类特殊的Unicode码点,通常紧跟在另一个字符后面,作用是“建议”或“指定”该字符的具体显示样式(字形变体),以保证不同平台或字体能正确显示
常见变体选择符:
U+FE0E(VS15,Variation Selector-15)表示文本形式,提示字符以普通文本风格显示U+FE0F(VS16,Variation Selector-16)表示表情符号形式,提示字符以彩色Emoji风格显示
比如,Unicode字符U+2764是一个“心形”符号 ❤:
- 单独使用:
U+2764,显示可能是黑白符号,也可能是彩色Emoji,这依赖平台和字体 - 加上变体选择符:
U+2764 U+FE0F,强制显示为彩色Emoji❤️ - 加上变体选择符:
U+2764 U+FE0E,强制显示为黑白文本 ❤︎
讲了这么多,终于到实践的部分了
到目前为止,我们讨论的都是计算机如何“理解”和“存储”字符
现在,我们来看看在实际操作中,人类是如何与这个复杂的字符系统进行交互的
工具与应用
输入法(Input Method Editor, IME)
输入法并非一个普通的应用程序,而是一个专为文本输入设计的、集成在操作系统中的系统级服务或中间件
它的位置恰好位于物理键盘和当前聚焦的应用程序之间,为了让输入法能够“拦截”和“处理”按键,所有现代操作系统都提供了专门的框架来管理和集成它们:
-
Windows: 文本服务框架 (Text Services Framework, TSF)
这是一个先进的框架,允许输入法、手写识别、语音识别等多种文本服务以统一的方式与应用程序交互
在早期,Windows使用的是一个较老的系统,名为输入法管理器 (Input Method Manager, IMM)
-
macOS: Input Method Kit
这是苹果为开发者提供的、用于构建输入法的官方框架
-
Linux: IBus (Intelligent Input Bus) & Fcitx (Flexible Context-aware Input Tool for X)
它们都采用了一种“总线”式的架构,输入法作为服务挂载在总线上,为所有应用程序提供输入服务
这些框架的核心作用,就是建立一套标准的通信协议,确保任何应用程序(只要它支持该框架)都能与任何输入法进行顺畅的对话,而无需关心对方的具体实现
当我们在键盘上敲下字母到最终输入文字,经历了什么?
我们以输入“你好”为例,一步一步看看它的过程:
步骤一:事件拦截
-
物理按键触发
当我们按下
n键时,键盘硬件会将该按键对应的扫描码(Scan Code) 通过键盘控制器发送到计算机这只是一个硬件级的信号,还不知道“n”是什么意思
-
操作系统接收与封装事件
操作系统的输入子系统(如 Windows 的 Keyboard Class Driver、Linux 的 evdev)接收到扫描码,将其转换成虚拟键码
这一阶段还只是“按下了哪个键”的信息,不涉及语言文字
-
IME 输入法拦截
在操作系统将键盘事件传递给当前活动应用程序(比如聊天窗口)之前,事件会先经过输入法框架
如果当前有 IME 处于激活状态,它会拦截并消费这个按键事件 —— 这意味着这个按键不会直接传给应用,而是先进入输入法的内部处理逻辑
-
建立输入上下文
IME会根据当前的焦点控件(例如一个可编辑文本框)建立一个输入上下文,用来记录本轮输入的状态:
- 已输入的编码(例如拼音串
nihao) - 光标位置
- 候选词列表
- 用户选择历史
这一步相当于输入法开了一个“草稿本”,专门记录你正在打的这段文字
- 已输入的编码(例如拼音串
-
生成组合字符串
输入法会将已输入的编码(如
n→ni→nih→nihao)显示在屏幕上这段带虚线或高亮的临时文字被称为组合字符串,它不是应用程序缓冲区里的正式文本,而是由输入法通过IME接口直接绘制到光标位置上的
在这个阶段,应用程序并不知道这些字母是什么 —— 它只知道光标处有一个正在编辑的输入会话
步骤二:转换引擎
这是输入法最核心的部分,转换引擎根据缓冲区中的nihao,开始计算所有可能的候选结果
转换引擎主要依赖两个东西 —— 词库和语言模型:
1.词库
存储大量词语及其拼音(或其他编码)对应关系的数据集合
-
静态词库
输入法出厂时内置的、包含数百万词条的巨大数据库。它定义了拼音与汉字、词语之间的基础对应关系
-
动态/用户词库
记录你个人常用词汇的词典。你输入过的名字、昵称、专业术语都会被添加进来,下次输入时就会优先显示
-
云端词库
现代输入法的“联网大脑”。它能实时从互联网上抓取最新的流行语、新闻热点、人名地名,让你的输入法永远“与时俱进”
2.语言模型
如果说词典是认字,那么语言模型就是理解语法和语境,它负责从众多同音词中,猜出你最想要的那一个
-
N-gram 模型
这是统计学模型,它通过分析海量文本数据,计算出词语组合的概率
例如,它知道
P(好 | 你)(在“你”之后出现“好”的概率)要远远大于P(耗 | 你),因此,你好的排序会非常靠前 -
更先进的模型(HMM, CRF, AI)
现代输入法普遍采用更复杂的统计模型,甚至是深度学习神经网络(如 RNN/LSTM)
这些模型不仅看前一个词,还会综合分析整个句子的结构和语义,从而做出惊人准确的预测
例如,当你输入
jintianwanshangwomenyiqiqu时,它能直接预测出今天晚上我们一起去,而不是一堆不相关的单字
步骤三:候选界面
-
生成列表
转换引擎将计算出的结果,按照概率从高到低排序,生成一个候选列表
-
渲染窗口
输入法的界面模块(UI)获取这个列表,然后在屏幕上绘制出我们熟悉的候选窗口
这个窗口是一个独立的、悬浮在所有应用之上的图层,由输入法完全控制
步骤四:文本提交
-
用户选择
用户通过按空格、数字键或鼠标点击,在候选窗口中选择了
你好 -
发送指令
输入法收到用户的选择后,会向操作系统的文本服务框架发送一个提交文本的指令
-
内容交付
这个指令里装的,就是最终确定的字符串
你好更底层地看,是这两个字符的Unicode 码点序列 (
U+4F60,U+597D) -
应用接收
应用程序的文本框接收到这个指令,就像接收到用户用剪贴板粘贴进来一段文本一样
它将这两个字符插入到自己的文本缓冲区中
-
最终渲染
应用程序调用系统的字体渲染引擎,根据当前设置的字体,将
U+4F60和U+597D对应的字形绘制到屏幕上
至此,输入法绘制的临时草稿(带下划线的nihao和候选窗口)消失,你好这两个字被正式地写入了应用程序,整个输入流程完成
编码转换工具和库
在处理来自不同年代、不同地区、不同系统的数据时,编码不一致是家常便饭:
-
我们可能需要将一个使用GBK编码的旧网站数据库,迁移到新的、使用UTF-8的系统中
-
用户可能会上传各种奇奇怪怪编码的文本文件,我们的程序需要有能力正确识别和处理它们
-
我们调用的某个古老API接口,可能只接受GBK编码的请求
因此,编码转换很重要
iconv
iconv是一个乎所有类Unix系统都自带的跨平台命令行工具和编程库,专门用于字符编码的转换
格式:
iconv -f <源编码> -t <目标编码> <输入文件> -o <输出文件>
常用参数:
| 参数 | 作用说明 |
|---|---|
| -f 或 –from-code | 指定输入文本的字符编码格式 |
| -t 或 –to-code | 指定输出文本的字符编码格式 |
| -l 或 –list | 列出支持的所有编码格式 |
| -o 或 –output | 指定输出文件(否则输出到标准输出) |
| -c | 忽略非法输入字符(转换时跳过错误字符) |
| –verbose | 显示详细的转换过程信息 |
eg:将一个GBK编码的文件转换为UTF-8编码的格式
iconv -f GBK -t UTF-8 gbk.txt -o utf8.txt
ICU
ICU(International Components for Unicode,Unicode国际组件)是一个由IBM(International Business Machines Corporation,国际商业机器公司)开发和维护的、功能极其强大的C/C++和Java库,后来交由了Unicode联盟管理
其他语言也可以通过绑定或封装调用ICU库来使用大部分核心功能,但可能需要额外安装或配置
ICU不止是一个编码转换工具,还是一套全方位的国际化解决方案
它提供比iconv更强大、更健壮的编码转换功能,支持超过200种编码,还有以下功能:
-
字符归一化
可以轻松地将字符串转换为NFC或NFD等范式
-
排序
它能实现真正符合语言习惯的排序
例如,简单的按字节排序会将
b排在á前面,但ICU知道在西班牙语中它们应该如何正确排序对于中文,它可以实现按拼音、部首或笔画排序
-
日期、时间、数字、货币格式化
它可以根据不同国家/地区(Locale)的习惯,将同一个日期
2025-08-13格式化为8/13/2025(美国)或13/08/2025(英国) -
文本边界分析
它能准确地识别出单词、句子、段落的边界,这对于文本处理和搜索引擎至关重要
编程语言
现代主流编程语言都内置了强大的字符串和编码处理能力,通常足以应对日常的转换需求
比如python内部使用unicode表示字符串,并提供了.encode()和.decode()方法,之前的示例中我们也使用过
eg1:将GBK字节流转换为unicode字符串
gbk = b'\xc4\xe3\xba\xc3' # "你好" 的 GBK 字节
unicode= gbk.decode('gbk')
eg2:接上一例,将unicode字符串编码为UTF-8字节流
utf8 = unicode.encode('utf-8')
Java, JavaScript, Go, Rust 等也都提供了类似的API,使得我们可以方便地在代码层面处理编码问题
到这里,一切的一切也就结束了
这篇文章诞生原因其实是在学linux命令的时候时常涉及字符、字等等东西,再加上以前看过不少相关文章视频,兴趣使然才写下了这些文字
编码的世界远比我想象的复杂,本文也只是冰山一角、抛砖引玉之作,系统的学习还要综合网上的资料才行
不管怎么样,希望能对你有所帮助