
嗯对就是一些磁盘相关的东西
物理盘(Physical Disk,PD)
是实际存在的硬件存储设备,如HDD(Hard Disk Drive,机械硬盘)、SSD(Solid State Drive,固态硬盘)
HDD是依靠旋转的磁盘和机械磁头读写数据的传统硬盘,有真实的机械运动,因此读写速度受机械臂移动和盘片旋转限制,随机访问慢,并且不耐摔,但大容量成本低,所以通常用作大容量备份或冷存储
SSD则完全没有机械部件,数据存储在电子闪存中,读写几乎即时,随机访问和顺序访问速度都很快,是耐摔王,但价格高,写入次数有限,需要通过固件和控制器管理寿命,通常作系统盘和高速应用
虚拟盘(Virtual Disk ,VD )
是通过软件技术模拟出来的磁盘存储设备,没有物理结构,但在系统层面像真实磁盘
常见以下几类:
本地虚拟盘
在单台计算机上由操作系统或软件创建的虚拟盘,例如VHD、VMDK之类的,用于虚拟机
网络存储虚拟盘
通过网络提供的虚拟盘,可以被多台设备访问,比如:
NAS(Network Attached Storage)
文件级存储,通过网络共享文件,常用于家庭或企业文件共享
SAN(Storage Area Network)
块级存储,通过高速网络提供虚拟磁盘给服务器使用,多用于企业数据库或虚拟机存储
云存储虚拟盘
云服务商提供的块存储或对象存储虚拟盘,把我们的文件放在远程服务器上,这些服务器内部可能是HDD 或SSD,经过虚拟化后提供我们一个虚拟盘,通过网络访问就像访问本地盘一样,例如百度网盘
网络存储虚拟盘更像企业内部自建硬盘,使用局域网(LAN)
而云存储虚拟盘是互联网远程虚拟盘,使用互联网(WAN),用户只是远程使用而已
磁盘组(Disk Group)
是将多块物理盘组合成一个组,比如RAID阵列就是磁盘组
扇区(Sector)
物理扇区
是硬盘硬件上可以独立寻址和进行读写操作的最小物理区域
由于物理层面的原因,没有硬盘能做到一个bit一个bit对数据进行操作
对于机械硬盘,它指的是盘片上磁道的一个特定弧段,硬盘的磁头在执行一次读写命令时,至少要处理这么大一块物理区域
对于固态硬盘,它对应于NAND闪存芯片中的一个物理页或块的一部分,是SSD主控能够操作的最小数据单元
一个物理扇区并不完全用来存储用户数据,它还包含了其余内容,用于确保数据能被准确定位和可靠读写:
- 间隙:用于分隔不同的扇区
- 同步标记:帮助磁头在高速旋转中同步数据读取的时机
- 地址标记:记录这个扇区的唯一物理地址(哪个磁头、哪个柱面、哪个扇区)
- 纠错码(ECC):这是一段根据数据内容计算出来的校验码,在读取数据时,硬盘会重新计算ECC并与存储的ECC进行比对,以发现并纠位错误
这样方便了管理,也产生了空间开销
随着硬盘容量的急剧增大,使用512字节的物理扇区变得越来越低效,现在很多硬盘物理扇区扩大到了4096字节(4KB),被称为先进格式化(Advanced Format,AF),相当于把8个小扇区的管理开销合并为1个大扇区的开销,空间利用率显著提高,并且更大的扇区意味着可以分配更多的空间给ECC码,从而设计出更好的纠错算法
糟糕的问题
当我们要写入HDD的数据不足512B的时候,硬盘也会先把包含目标字节的整个扇区512B读入缓存,在缓存中修改要写入的那些字节,之后重新计算ECC,最后把整个512B扇区写回磁盘
也就是说,硬盘把所有不是512B整数倍的写过程,都变成了读-改-写的过程!这会造成性能的浪费!
而对于SSD,这个情况更加严重:
SSD最小写单元是页,通常是4KB,但它最小的可擦除单元却是按照块计算,通常是128KB
NAND闪存写入页之前页必须是干净的,也就是所有位都是1,不能直接覆盖,而擦除必须整块擦除
如果把块设置成和页一样大,可擦除最小单位变成4KB,坏块产生概率更高,还会加速磨损
如果把页设置成和块一样大,写入最小单位变成128KB,小文件写入会严重浪费,性能下降
所以现在的设置是理论最优喔
当写入数据不是4KB的整数倍的时候会变成读-改-写,这还好,如果要写的页已经写过,无法覆盖,那就必须擦除,而擦除所带来的改就是整个块的改动,有几百KB,甚至达到MB的级别!
这就是所谓的“写放大”问题,而它几乎是不可避免的
逻辑扇区
类似逻辑地址,逻辑扇区是一个抽象概念,是硬盘让操作系统和用户看到的假设出来的东西
操作系统使用一种名为逻辑块地址 (Logical Block Addressing, LBA) 的方式来访问硬盘
在这种模式下,整个硬盘被看作一个从0开始编号的、连续线性的逻辑扇区数组,操作系统无需关心数据具体存放在哪个盘片、哪个磁头、哪个柱面上,只需要关心线性的LBA地址就可以了,这极大地简化了软件开发
比如,当操作系统需要读取数据时,它只用发出简单的指令:给我LBA地址为12345的数据,就会自动取出第12346个扇区(注意扇区编号从0开始的)
并且,这还保证了新硬件能够兼容旧的操作系统,比如从HDD变为SSD,或改变内部存储结构,只要硬盘的固件能够正确地将操作系统发来的LBA地址请求翻译成对内部物理存储单元的操作即可
逻辑扇区大小可以与物理扇区不同,接着往下看
硬盘扇区格式标准
512n(512 Native,512原生)
最传统的标准,即硬盘的物理扇区大小和逻辑扇区大小都是512字节
所见即所得,操作系统看到的逻辑结构与硬盘的物理结构完全一致,不存在转换和模拟
512e(512 Emulation,512模拟)
这是当前最主流的标准,硬盘的物理扇区大小是4096字节 (4KB),但它对外伪装成512字节的逻辑扇区与操作系统沟通,来保证对旧软件和操作系统的向后兼容性
在windows的cmd,使用下面的命令可以查看C盘扇区大小:
fsutil fsinfo ntfsinfo C:

但这样也会导致问题:当操作系统尝试写入一个未与底层4KB物理扇区边界对齐的512字节逻辑扇区时,就会触发一次之前说过的读-改-写操作,这被称为未对齐写入,也会导致性能下降
4Kn(4K Native,4K原生)
最现代的标准,硬盘的物理扇区大小和逻辑扇区大小都是4096字节
逻辑盘(Logical Disk ,LD)/ 分区 (Partition)
逻辑盘是在物理盘上通过软件划分出来的具有逻辑结构的存储区域,依赖物理盘,也叫做分区
一个物理盘可划分为多个逻辑盘,如Windows的C、D盘,Linux的/dev/sda1、/dev/sda2分区
为什么要分区?
-
隔离数据
可以将操作系统文件与用户数据分开放置。如果系统分区损坏需要重装,用户数据分区可以不受影响
-
使用不同文件系统
可以在同一块硬盘上为不同的分区创建不同的文件系统,以满足不同需求
例如,一个ext4分区给Linux用,一个NTFS分区用于和Windows共享数据
-
专用空间
创建专门的分区用作交换空间,作为物理内存的补充
将频繁读写的文件(如日志)放在独立分区,可以减少磁盘碎片,方便备份和管理
分区格式
分区格式又叫做分区表格式、分区方案,定义了整块硬盘如何被分割
分区格式总被存储在硬盘的开头,决定着以下内容:
| 功能 | 说明 |
|---|---|
| 分区数量与位置 | 告诉操作系统磁盘上有哪些分区、每个分区从哪开始到哪结束 |
| 启动信息 | 存放系统启动代码(例如 MBR 的引导加载器) |
| 磁盘寻址方式 | 定义用扇区号还是 LBA 地址来访问磁盘数据 |
| 兼容性与容量上限 | 决定磁盘支持的最大容量、最大分区数、支持哪些系统 |
| 冗余与校验机制 | GPT 具备备份表与 CRC 校验,MBR 则没有 |
如果没有分区格式,一般就被称作RAW,下面是一些常见的分区格式:
MBR (Master Boot Record,主引导记录)
这是一种较老的分区方案,限制一块MBR硬盘最多只能有4个主分区
为了突破4个分区的限制,可以将其中一个主分区设置为扩展分区,然后在扩展分区内部可以创建多个逻辑分区
因此,分区编号1到4总是留给主分区或扩展分区,逻辑分区的编号则从5开始
所以,如果我们看到一块硬盘的分区是/dev/sda1、/dev/sda2、/dev/sda5,这通常意味着sda1和sda2是主分区,而sda5是扩展分区里的第一个逻辑分区:
MBR分区表 (最多4个条目)
+---------+---------+---------+-----------+
| 主分区1 | 主分区2 | 主分区3 | 扩展分区 |
+---------+---------+---------+-----------+
扩展分区内部 (逻辑分区链表)
+-----------+-----------+-----------+
| 逻辑分区5 | 逻辑分区6 | 逻辑分区7 |
+-----------+-----------+-----------+
扩展分区不是独立的分区,它是一个链表容器,存储在磁盘上的EBR(Extended Boot Record)
每个逻辑分区都有自己的EBR,用来指向下一个逻辑分区 ,操作系统通过EBR链表来识别逻辑分区
GPT (GUID Partition Table,GUID分区表)
这是一种更现代、更灵活的分区方案,是当前的主流标准,理论上支持无限个分区(但操作系统通常限制为128个)
没有主分区、扩展分区、逻辑分区的复杂概念,所有分区地位平等
分区编号就是简单地从1开始连续递增,如/dev/sda1、/dev/sda2、/dev/sda3…
APM (Apple Partition Map,苹果分区图)
这是一种较老的分区方案,是苹果公司在从PowerPC架构迁移到Intel架构(约2006年)之前,为其PowerPC 架构的Mac电脑所使用的默认分区方案
它同样会记录磁盘上的分区信息,包括为当时的Mac OS(现macOS)存储特定的启动信息和驱动程序
在现代的Intel和Apple Silicon Mac上,已经全面被GPT取代
文件系统
当我们有了一个分区后,它还只是一片空白的存储空间,我们还需要一种规则来组织和管理将要存入其中的数据,这种规则就是文件系统,文件系统本质上是操作系统的一部分
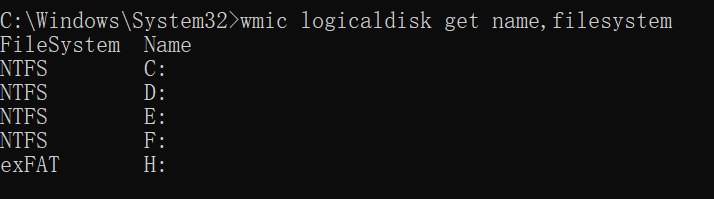
在windows的cmd下,可以使用下面命令查看所有卷的文件系统:
wmic logicaldisk get name,filesystem
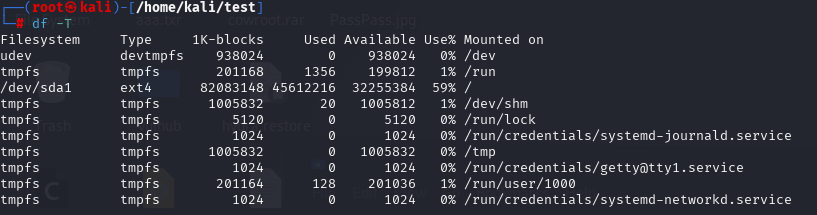
在linux则可以使用下面的命令:
df -T
分区的格式化
在一个分区上创建文件系统的过程,就叫做格式化(Format)
从技术上讲,格式化的核心就是在指定的分区上创建一套全新空白的文件系统,就像拿到一本空白的笔记本,在第一页画好目录的表格,为之后写内容做好组织规划
不过为什么我们日常的体验是“格式化=擦除数据”呢?
这完全取决于我们执行的是哪一种格式化,格式化主要分为两种:快速格式化和完全格式化
快速格式化
操作系统只会擦除文件系统的索引区域,然后写入一套新的空白的索引,不会处理真正存储内容的数据区域
对操作系统来说,既然目录已经是空白的了,那它就认为这个分区上没有任何文件,因此硬盘看起来是空的
但实际上,之前的所有数据都还原封不动地在磁盘上,只是失去了能够找到它们的索引信息
也正因如此,数据恢复可能性非常高,数据恢复软件会跳过被删除的目录,直接扫描整个硬盘的数据区域,根据文件头信息和数据结构来重建出原始文件
完全格式化
既删除目录,也擦除所有内容
执行完全格式化,操作系统会做两件事:
- 执行一次快速格式化,创建新的空白文件系统。
- 从头到尾扫描整个分区,并向每一个扇区的每一个bit写入0
这样一来,所有旧数据都会被毫无意义的0数据彻底覆盖掉。硬盘被真正地清空了,完全不能恢复
常见的文件系统类型
FAT
全称File Allocation Table,文件分配表
结构简单,兼容性极佳,几乎所有主流操作系统和电子设备都支持,常用于U盘、SD卡、移动硬盘,作为跨平台数据交换的媒介
FAT文件系统关键结构就是FAT,即文件分配表,作用就是记录磁盘上每个簇的使用情况和文件存储位置,簇是磁盘上最小的数据分配单位,由若干扇区组成
FAT的分区大小=最大簇数×每簇大小,最大簇数由每个簇编号占用的位数决定,通常写在名字里,比如FAT12就是每个簇用12位表示,最大簇数2¹²=4096个,而每簇大小不太固定
FAT16
非常早期的版本,在DOS和Windows 95时代流行,已经基本被淘汰
最大仅支持2GB的分区(在某些系统中可达4GB)
FAT32
是FAT16的改进版本,但它依旧无法管理大于4GB的单个文件,并且最大分区支持也有限(Windows上限制为32GB,理论上可达2TB)
exFAT (Extended File Allocation Table)
由微软推出,专为解决FAT32的缺点
它打破了4GB单文件和分区大小的限制,同时针对闪存介质的特性进行了优化,减少了不必要的写入操作
NTFS
全称New Technology File System,新技术文件系统
是Windows系统的标准文件系统,支持大文件和大分区,并提供文件权限管理、加密、日志、压缩等强大功能,可靠性和安全性高
感兴趣可以看看我的另一篇博客:NTFS系统
ReFS
全称Resilient File System,弹性文件系统
是微软为Windows Server系统推出的、旨在替代NTFS的新一代文件系统,但它的核心设计目标不是替代桌面版的NTFS,而是为数据中心和大规模存储提供更高的数据完整性和可用性
它通过对元数据和可选的用户数据进行校验和来主动检测和修复数据损坏,其写入时复制(Copy-on-Write)机制确保了在写入过程中发生意外时,旧数据不会被破坏,极大地增强了数据恢复能力
常用于Windows Server的存储空间和Hyper-V虚拟化场景
ext
全称Extended File System,扩展文件系统
Linux系统的标准文件系统,用于几乎所有的Linux发行版,从桌面到服务器,以及安卓手机的内部存储
ext2
经典的早期版本,性能良好,但与FAT类似,缺少日志功能,在服务器等场景下可靠性不足
ext3
它在ext2的基础上加入了日志功能,在不改变底层结构的情况下,极大地提升了文件系统的可靠性,成为了许多Linux发行版的长期默认选项
ext4
当前的主流标准,它在前代基础上引入了多项重要改进,如Extents(优化大文件的存储方式,减少碎片并提升性能)、支持更大的文件和卷、更快的自检速度等,使其更现代化、性能更强
Btrfs
全称B-tree File System
是Linux的新一代文件系统,旨在替代ext系列文件系统,尤其适合企业级存储和虚拟化环境
Btrfs内置了快照、校验和、数据压缩、写时复制以及多磁盘管理等功能,它非常灵活,允许动态地添加、删除设备和调整卷大小,目前已成为一些Linux发行版(如Fedora, openSUSE)的默认文件系统
XFS
全称Extended Filesystem X,扩展文件系统X
是一种高性能日志文件系统,最初由硅谷图形公司SGI为其IRIX操作系统开发,后来被Linux采用
XFS的结构设计使其在文件数量和大小增长时,性能下降幅度很小,特别适合处理大文件和高并发读写场景
因其稳定性和高吞吐量的特性,XFS成为了许多企业级Linux发行版(如Red Hat Enterprise Linux及其衍生版CentOS)的默认文件系统,尤其适用于数据库、媒体服务器和科学计算等场景
tmpfs
全称Temporary File System,临时文件系统
是Linux下的一种虚拟文件系统,完全驻留在内存中,用于存放临时文件
数据不持久,重启后丢失,支持动态调整大小,常用于/tmp、/run等目录
devtmpfs
全称Device Temporary File System,设备临时文件系统
是Linux内核专门为/dev目录提供的虚拟文件系统,用于管理设备节点
在内存中动态生成,不占用硬盘,系统启动早期即可挂载,方便设备驱动初始化
HFS+ 与 APFS
HFS+全称Hierarchical File System Plus,分层文件系统增强版
APFS全称Apple File System,苹果文件系统
他们都是苹果macOS系统的文件系统,HFS+是长期的标准,而APFS(Apple File System)是从2017年开始推出的新一代文件系统,专门为固态硬盘和闪存优化,性能和可靠性更强
卷(Volume)
卷是将分区格式化后, 创建了文件系统, 能够被系统所识别和访问的存储区域
在最简单的情况下,一个卷和一个分区是一一对应的,比如在一块硬盘上划分了C、D两个分区,那么就有两个对应的卷
但一个卷也可以跨越多个分区,甚至多块物理硬盘,例如RAID阵列,在操作系统看来就是一个跨越了多块物理盘的巨大逻辑卷
Windows物理磁盘的管理模式
基础磁盘 (Basic Disk)
这是Windows系统默认的磁盘类型,当我们初始化一块新硬盘时,系统默认会将其设置为基础磁盘
它使用我们之前讨论过的传统分区表(MBR或GPT)来组织磁盘
基础磁盘上的一个分区(或简单卷)不能跨越到多个物理磁盘上,每个分区都完全包含在一块物理硬盘的内部
动态磁盘 (Dynamic Disk)
这是Windows提供的一种更高级的磁盘管理模式,它提供了基础磁盘所不具备的许多高级功能
动态磁盘不使用传统的分区表来定义卷,而是使用一个逻辑磁盘管理器(LDM,Logical Disk Manager)的数据库来跟踪所有动态卷的信息,这个数据库会被复制到系统中每一个动态磁盘上,以实现冗余
动态磁盘允许创建跨越多个物理硬盘的卷(这实际上就是一种软件RAID的实现)
-
简单卷
功能上等同于基础磁盘上的一个分区,但它只能在动态磁盘上创建
-
跨区卷
将来自多个物理磁盘上的未分配空间合并成一个巨大的卷
数据会先写满第一块盘的空间,然后再接着写到下一块盘,类似JBOD(Just a Bunch of Disks)概念
-
带区卷
将数据条带化地同时写入到多个物理磁盘上,以提高读写性能,等同于软件RAID0
-
镜像卷
将数据完全一致地写入到两块物理磁盘上,实现数据冗余,等同于软件RAID1
-
RAID-5 卷
将数据和奇偶校验信息条带化地分布到三个或更多的物理磁盘上,等同于软件RAID5
它无需昂贵的硬件RAID卡,就能在操作系统层面实现RAID功能,管理非常灵活
但不好的是兼容性差,因为这是微软的专有技术,Linux和macOS系统通常无法原生识别动态磁盘卷
此外,从动态磁盘转换回基础磁盘,需要删除磁盘上的所有卷,会导致数据丢失
驱动器(Drive)
驱动器是指可以存储和访问数据的存储单元,它可以是分区、卷或者磁盘
物理驱动器:真实存在的硬盘或固态盘
逻辑驱动器:操作系统识别后的分区或者卷
虚拟驱动器:通过工具在内存中创建的模拟磁盘,操作系统可像对待真实磁盘一样访问
Windows驱动器
每一个驱动器都会有一个驱动器号,是Windows系统为方便用户访问而给卷分配的标识符,例如C:、D:
我们完整看到的驱动器号过程应该是这样的:
物理硬盘 → 分区 → 文件系统 → 卷 → 挂载 → 驱动器
比如我们插入U盘,系统会识别分区,然后作为卷挂载,它是实打实的新的硬盘空间
而当用FTKImager这样的工具挂载镜像时,软件会在内存中创建一个虚拟磁盘,Windows会识别其中的卷,并给它分配一个驱动器号,之后就能在“我的电脑”里看到一个新盘符,空间来源就是镜像文件
Linux驱动器
驱动器不会用盘符标识,而是通过设备文件和挂载点来管理,比如/dev/sda1挂载到/home
挂载(Mount)
挂载是将存储设备(磁盘、分区、镜像、容器等)接入文件系统,从而让用户和程序能够访问其内容的过程
挂载前,设备的内容是孤立的,操作系统无法通过普通路径访问
挂载后,就可以通过某个路径访问设备里的数据了
挂载点
是操作系统用来访问挂载设备的路径或位置
在Linux通常是一个空目录,比如 /mnt/usb、/media/cdrom
而Windows默认挂载方式是分配驱动器号,也可以挂载到空目录
windows挂载
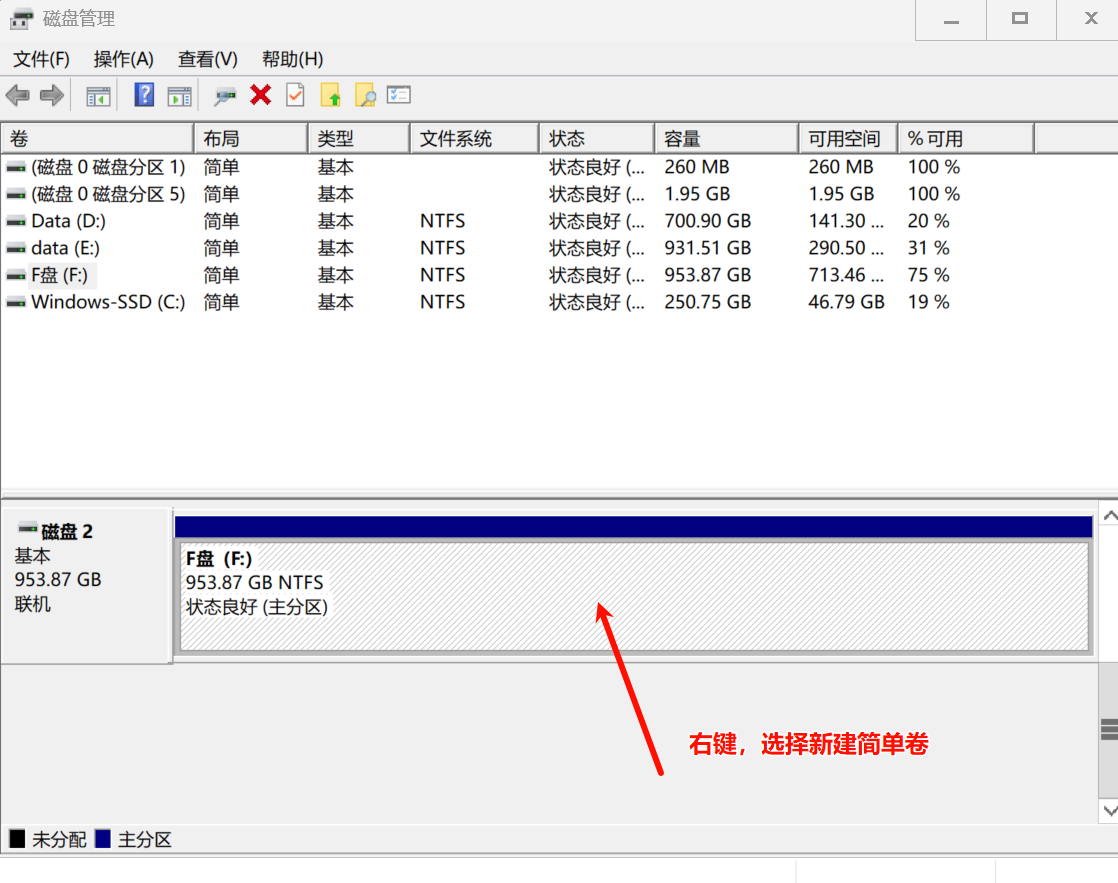
插入U盘、使用软件挂载镜像应该都很熟悉了,这里正好借着我添加移动硬盘的过程来说一下:
首先win+x组合键调出功能栏,打开磁盘管理

新的硬盘会显示未分配空间,是灰色的(我的分配好了),在这上面右键,选择新建简单卷:
一直下一步默认,其中会让你选择驱动器符号和填写磁盘名称,按自己的喜好来就行
Linux挂载
命令行挂载:
mount /dev/sdb1 /mnt/usb
/dev/sdb1是要挂载的目标,/mnt/usb是挂载点
查看挂载信息:
mount # 查看当前所有挂载
df -h # 查看挂载的设备及占用空间
卸载设备:
umount /mnt/usb # 或 umount /dev/sdb1
Linux的文件系统是树结构,所有挂载都是挂在这个树上
Windows系统的物理盘与逻辑盘表示
设备命名规则
Windows的设备命名体现在不同的管理层级中
物理磁盘层
这是Windows磁盘管理工具对整块物理硬盘的标识,是系统能识别到的最底层的物理存储单元
命名方式:
磁盘 <X>
<X>表示物理磁盘的编号,从0开始,由系统按检测顺序(通常是主板接口顺序)分配
eg:
磁盘 0:通常是系统启动盘磁盘 1:表示第二块物理硬盘
分区/卷层
物理磁盘上的划分区域
在磁盘管理中,它们被显示为图形化的数据块,位于对应的磁盘X行上

驱动器号层
这是Windows为用户提供的访问方式,它是一个快捷方式或挂载点,指向一个已格式化并激活的卷
命名方式:
<X>:
<X>表示一个字母(从A到Z)
eg:
C::通常指向操作系统所在的活动主分区E::可能指向一个数据分区,也可能指向一个U盘或光驱
GUID卷路径
这是系统在后台真正用来识别卷的方式,它不受26个字母的限制
一个卷可以没有驱动器号,而是被挂载到一个NTFS文件系统中的空目录上,此时系统就是通过这个GUID路径来访问它的
命名方式:
\\?\Volume{xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx}\
eg:
\\?\Volume{4d582b1a-0000-0000-0000-100000000000}\
实例
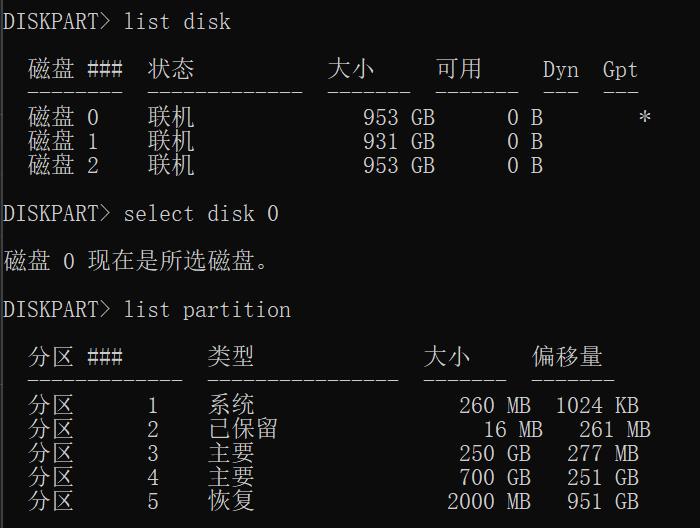
在Windows中,diskpart是一个命令行工具,可以清晰地展示磁盘和分区的层级关系
以下操作都需要管理员模式
启动diskpart后,使用list disk查看所有物理磁盘,再使用select disk <X>选择一块磁盘,用list partition查看其上的分区:
diskpart
list disk
select disk 0
list partition
使用mountvol命令能查看卷的GUID路径:
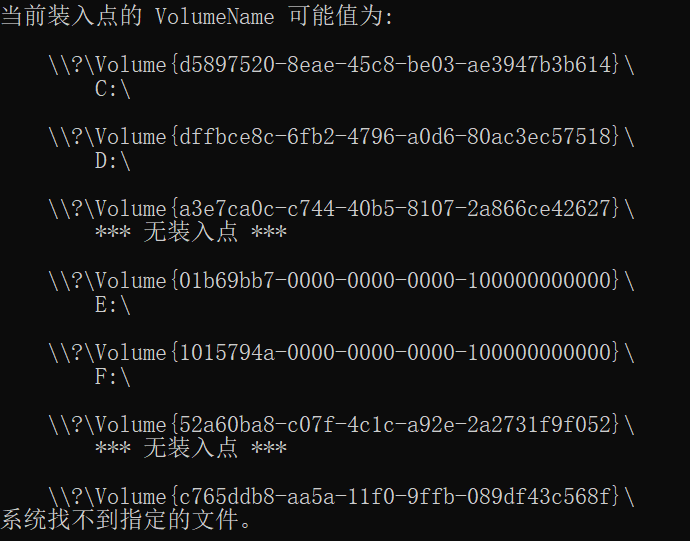
也可以使用powershell命令:
Get-CimInstance -ClassName Win32_Volume | Select-Object DeviceID, DriveLetter, Label, Capacity | Format-Table -AutoSize

Linux系统的物理盘与逻辑盘表示
在Linux的设计哲学中,有一个核心思想是“一切皆文件”,这意味着硬件设备,如硬盘、键盘、鼠标等,都会在文件系统中以一个特殊文件的形式存在
这些设备文件都集中存放在/dev目录(也就是device的意思)下,通过读写这些文件,就可以与对应的硬件设备进行交互
设备命名规则
一般格式:
/dev/[设备类型][磁盘序号][分区号]
sd (通用硬盘)
这是最常见的前缀,源于 “SCSI disk”
它被广泛用于表示几乎所有类型的现代硬盘,包括SATA硬盘、SAS硬盘,甚至U盘和通过USB连接的移动硬盘
其命名方式为:
/dev/sd<X><N>
<X>:表示磁盘序号的字母 (a,b,c…),按内核检测到的顺序分配<N>:表示该磁盘上的分区号 (1,2,3…),此部分是可选的,没有则代表整块硬盘
eg:
/dev/sda:表示系统中第一块被识别的sd类型物理硬盘/dev/sdb2:表示第二块sd类型硬盘上的第2个分区
hd(IDE硬盘)
是"Hard disk"的缩写,这是早期用于表示IDE/PATA接口硬盘的前缀,在现代系统中已非常少见
其命名方式基本和sd相同:
/dev/hd<X><N>
<X>:表示磁盘序号的字母 (a,b,c…),按内核检测到的顺序分配<N>:表示该磁盘上的分区号 (1,2,3…),此部分是可选的,没有则代表整块硬盘
eg:
/dev/hda:表示第一块IDE硬盘/dev/hdb2:表示第二块IDE硬盘上的第2个分区
vd(虚拟化硬盘)
是"Virtual disk"的缩写,常见于KVM等虚拟化环境中,代表分配给虚拟机的虚拟硬盘
其命名方式也和sd大差不差:
/dev/vd<X><N>
<X>:表示磁盘序号的字母 (a,b,c…),按内核检测到的顺序分配<N>:表示该磁盘上的分区号 (1,2,3…),此部分是可选的,没有则代表整块硬盘
eg:
/dev/vda:表示分配给当前虚拟机的第一块虚拟硬盘/dev/vdb1:表示第二块虚拟硬盘上的第1个分区
nvme(NVMe固态硬盘)
表示通过**NVMe (Non-Volatile Memory Express,非易失性存储器快速通道)**协议连接的高速固态硬盘
其命名方式有些特殊:
/dev/nvme<X>n<Y>p<Z>
<X>:表示NVMe控制器的序号,从0开始n<Y>:表示控制器下的命名空间(可以理解为磁盘),从1开始p<Z>:表示该磁盘上的分区号,从1开始
eg:
/dev/nvme0n1:表示第0个控制器上的第1块NVMe磁盘/dev/nvme1n2p2:表示第1个控制器上的第2块NVMe磁盘上的第2个分区
mmcblk(eMMC / SD卡)
用于表示嵌入式设备中的存储,如eMMC闪存或SD/TF卡
其命名方式也有点不同:
/dev/mmcblk<X>p<Y>
<X>:表示eMMC/SD卡设备的序号,从0开始p<Y>:表示该设备上的分区号,从1开始
示例:
/dev/mmcblk0:表示系统中第一张被识别的SD卡或eMMC芯片/dev/mmcblk1p1:表第二张卡上的第1个分区
实例
在linux里使用lsblk (list block devices,列出块设备) 命令可以清晰地看到系统中的磁盘和分区结构
假设一台Linux服务器有两块SATA硬盘,lsblk的输出如下(我现有的linux机分盘都很少,杜撰一个吧):
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 238.5G 0 disk // 第一块物理硬盘,总容量为238.5G
├─sda1 8:1 0 512M 0 part /boot/efi // sda上的第一个分区,512M,被挂载到了/boot/efi目录
└─sda2 8:2 0 238G 0 part / // sda上的第二个分区,大小为238G,被挂载为根目录/
sdb 8:16 0 931.5G 0 disk // 第二块物理硬盘,总容量为931.5G
└─sdb1 8:17 0 931.5G 0 part /data // sdb上的第一个分区,931.5G,被挂载到了/data目录
| 列名 | 含义 |
|---|---|
| NAME | 设备名,例如sda,sda1等 |
| MAJ:MIN | 主设备号:次设备号,用于Linux内核识别设备 |
| RM | 是否为可移动设备(1是可移动,如U盘或光驱,0是固定磁盘) |
| SIZE | 设备或分区的大小 |
| RO | 是否为只读(1是只读,0是可读写) |
| TYPE | 设备类型 |
| MOUNTPOINT | 当前挂载点路径,没有挂载则为空 |
LVM(Logical Volume Manager)
在传统的磁盘管理中,一个分区的大小在创建时就已固定,如果未来空间不足,调整起来会非常麻烦
为了解决这个问题,Linux引入了新的磁盘管理机制——LVM(Logical Volume Manager,逻辑卷管理器)
LVM的核心思想是引入一个抽象层,不再让操作系统直接使用固定的物理分区,而是通过LVM这个中间层来灵活地组织和分配存储空间,整个操作就像搭积木一样,可增可减
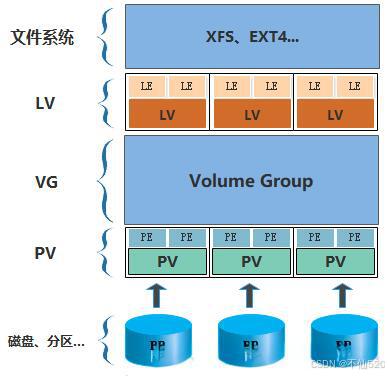
LVM的核心组件
要理解LVM,我们需要先了解它的三个基本概念,这三个概念是自底向上构建起来的
物理卷 (Physical Volume, PV)
这是LVM的最底层组件,是LVM用来构建存储池的原材料
通常是一个完整的物理硬盘(如/dev/sdb)或一个物理分区(如/dev/sdb1)
需要使用pvcreate命令将一个分区初始化或标记为物理卷,才能让LVM识别它
**eg:**将/dev/sdb1和/dev/sdc1两个分区标记为PV:
pvcreate /dev/sdb1
pvcreate /dev/sdc1
卷组 (Volume Group, VG)
这是一个巨大的存储池,由一个或多个PV组合而成
使用vgcreate命令创建一个卷组,将多个PV捆绑在一起
例如,我们可以将两个1TB的PV合并成一个2TB的VG
**eg:**创建一个名为my_vg的卷组,它由/dev/sdb1和/dev/sdc1组成
vgcreate my_vg /dev/sdb1 /dev/sdc1
逻辑卷 (Logical Volume, LV)
这是最终交付给操作系统使用的分区,也就是我们最终会格式化并挂载的设备
LVM从VG这个大存储池中切割出来的一块空间
使用lvcreate命令从VG中按需创建任意大小的逻辑卷
**eg:**从my_vg卷组中,创建一个名为data_lv、大小为50G的逻辑卷
lvcreate -n data_lv -L 50G my_vg
物理扩展块 (Physical Extent, PE)
PE是LVM中可以分配的最小存储单元,可以理解为LVM用来构建逻辑卷的积木
当一个PV被添加到一个VG中时,这个PV就会在内部被分割成许多大小相等的PE块
PE的大小在创建卷组时确定,默认为4MB,并且同一个卷组中所有PE的大小都必须一致
这个机制就是LVM灵活性的来源!
一个VG的总容量,就是其下所有物理卷PV提供的PE的总和
一个LV的大小,就是分配给它的PE的数量
扩容一个LV,本质上就是从VG的空闲PE池中再拿几块拼上去,缩容就是把还几块回去
逻辑扩展块 (Logical Extent, LE)
LE是构成LV的最小存储单元,是逻辑卷层面的积木
LE的大小与PE的大小在同一个VG中是完全相同的,如果一个VG的PE大小被设为4MB,那么该VG中所有LV的LE大小也必须是4MB
LVM的本质工作,就是建立一个LE到PE的映射表
当创建一个逻辑卷时,LVM会分配给它一定数量的LE,然后LVM会在元数据中记录下这100个LE分别对应到哪个物理卷PV上的哪100个PE
eg:
data_lv的LE 1-> 映射到 ->sda2的PE 50data_lv的LE 2-> 映射到 ->sdb1的PE 108(这就是跨盘的实现)
LVM设备命名
传统的路径是:
物理硬盘 → 分区 (/dev/sda1) → 格式化 → 挂载
而使用LVM后的路径是:
物理硬盘 → 分区 (/dev/sda1) → PV → VG → LV → 格式化 → 挂载
LVM创建的LV设备名通常位于/dev/目录下,并以其所属的VG命名:
/dev/<VG_Name>/<LV_Name>
eg:
/dev/my_vg/data_lv:表示从my_vg卷组中切分出来的,名为data_lv的逻辑卷/dev/ubuntu_vg/root:这很可能是一个Ubuntu系统安装在LVM上的根分区
这种路径实际上是一个方便访问的符号链接,它真正指向的设备路径位于/dev/mapper/下,例如/dev/mapper/my_vg-data_lv
LVM信息查看
查看磁盘类型
LVM结构同样可以在lsblk命令中清晰地看到,它会显示为一种lvm类型:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 100G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 99G 0 part // sda2被标记为PV
└─my_vg-data_lv 253:0 0 50G 0 lvm /data // 从my_vg中切分的data_lv
└─my_vg-web_lv 253:1 0 49G 0 lvm /var/www // 从my_vg中切分的web_lv
sdb 8:16 0 200G 0 disk
└─sdb1 8:17 0 200G 0 part // sdb1也被标记为PV
└─my_vg-data_lv 253:0 0 50G 0 lvm /data // 注意:data_lv跨越了sda2和sdb1
总览lvm各层
LVM还提供了一套专属命令来查看状态:
-
pvs:列出所有物理卷PV VG Fmt Attr PSize PFree /dev/sda2 my_vg lvm2 a-- 99.00g 0 /dev/sdb1 my_vg lvm2 a-- 200.00g 100.00g -
vgs:列出所有卷组VG #PV #LV #SN Attr VSize VFree my_vg 2 2 0 wz--n 299.00g 100.00g -
lvs:列出所有逻辑卷LV VG Attr LSize Pool Origin Data% Meta% data_lv my_vg -wi-a----- 50.00g web_lv my_vg -wi-a----- 49.00g
查看PV信息
此命令用于显示物理卷(PV)的详细属性
pvdisplay /dev/sda2
输出:
--- Physical volume ---
PV Name /dev/sda2
VG Name my_vg
PV Size 99.00 GiB / not usable 0
Allocatable yes
PE Size 4.00 MiB
Total PE 25343
Free PE 12543
Allocated PE 12800
PV UUID 7AjK3x-yB97-6aZB-v2i4-3pzv-vRSS-kPFSv4
| 字段 | 含义 |
|---|---|
| PV Name | 物理卷设备路径(如 /dev/sda3) |
| VG Name | 该 PV 所属的卷组(如 pve) |
| PV Size | 物理卷总大小 |
| Allocatable | 是否可用于分配给 LV |
| PE Size | 每个物理扩展块(PE)的大小,通常是 4 MB |
| Total PE | 总共有多少个 PE(相当于总块数) |
| Free PE | 未分配的 PE 数 |
| Allocated PE | 已被 LV 使用的 PE 数 |
| PV UUID | 每个 PV 的唯一标识符 |
附带-m参数,可以查看一个PV所属VG、有多少PE、每个PE分配到了哪个LV,又对应哪个LE:
--- Physical volume ---
PV Name /dev/sda2
VG Name pve
PV Size 100.00 GiB / not usable 4.00 MiB
Allocatable yes (but full)
PE Size 4.00 MiB
Total PE 25599
Free PE 0
Allocated PE 25599
--- Physical Segments ---
Physical extent 0 to 5119:
Logical volume /dev/pve/root
Logical extents 0 to 5119
Physical extent 5120 to 10239:
Logical volume /dev/pve/data
Logical extents 0 to 5119
Physical extent 10240 to 25599:
Logical volume /dev/pve/swap
Logical extents 0 to 15359
-
Physical extent 0 to 5119表示当前PV上的PE编号是0–5119
-
Logical volume /dev/pve/root这些PE目前被逻辑卷
/dev/pve/root使用 -
Logical extents 0 to 5119逻辑卷
/dev/pve/root中的LE编号0–5119映射到的PE编号为0–5119
查看VG信息
显示卷组(VG)的详细属性:
vgdisplay my_vg
输出:
--- Volume group ---
VG Name my_vg
System ID
Format lvm2
Metadata Areas 2
Metadata Sectors 2
Status resizable
MAX LV 0
Cur LV 2
Open LV 2
MAX PV 0
Cur PV 2
Act PV 2
VG Size 299.00 GiB
PE Size 4.00 MiB // <--- 核心:PE的大小
Total PE 76543 // <--- 核心:PE总数
Alloc PE / Size 50943 / 199.00 GiB
Free PE / Size 25600 / 100.00 GiB // <--- 核心:整个VG的空闲PE
VG UUID cM893Z-px8A-2Cxq-yq89-v9yO-TYIx-pCcAhQ
| 字段 | 含义 |
|---|---|
| VG Name | 卷组名(如 pve) |
| Format | LVM 版本(通常是 lvm2) |
| Cur LV | 当前卷组中包含的逻辑卷数量 |
| Cur PV | 卷组包含的物理卷数量 |
| VG Size | 卷组总大小 |
| PE Size | 每个 PE 的大小(与 PV 相同) |
| Total PE | 卷组中 PE 总数 |
| Alloc PE / Size | 已分配给 LV 的 PE 数及其总大小 |
| Free PE / Size | 剩余可用 PE 数及其大小 |
| VG UUID | 卷组唯一标识符 |
附带-m参数,可以查看一个VG内部包含的PV和LV,以及他们之间的PE/LE映射:
--- Volume group ---
VG Name pve
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 12
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 3
Open LV 3
Max PV 0
Cur PV 1
Act PV 1
VG Size 100.00 GiB
PE Size 4.00 MiB
Total PE 25599
Alloc PE / Size 25599 / 100.00 GiB
Free PE / Size 0 / 0
VG UUID 2Fb4-Xt4n-7xjM-J0b9-5b11-9n8m-3cA8p1
--- Logical volume mapping ---
LV Name /dev/pve/root
LE 0 to 5119 mapped to /dev/sda2: 0-5119
LV Name /dev/pve/data
LE 0 to 5119 mapped to /dev/sda2: 5120-10239
LV Name /dev/pve/swap
LE 0 to 15359 mapped to /dev/sda2: 10240-25599
-
LV Name /dev/pve/root该LV的名字是
/dev/pve/root,它属于卷组pve,通常挂载为系统根分区/ -
LE 0 to 5119 mapped to /dev/sda2: 0-5119这个LV的LE编号从0到5119,总共有5120个LE,映射到物理卷
/dev/sda2上的PE编号为0到5119
查看LV信息
显示逻辑卷(LV)的详细属性:
lvdisplay /dev/my_vg/data_lv
输出:
--- Logical volume ---
LV Path /dev/my_vg/data_lv
LV Name data_lv
VG Name my_vg
LV UUID aBcDeF-....
LV Write Access read/write
LV Creation host, time hostname, 2025-10-21 ...
LV Status available
# open 1
LV Size 50.00 GiB
Current LE 12800 // <--- 核心:这个LV由12800个LE组成
Segments 2 // <--- 核心:这个LV由2个段落组成(跨盘了)
Allocation inherit
Read ahead sectors auto
- currently set to 8192
Block device 253:0
| 字段 | 含义 |
|---|---|
| LV Path | 逻辑卷的设备路径 |
| LV Name | 逻辑卷的名称 |
| VG Name | 此逻辑卷所属的 VG |
| LV Status | 状态(available表示可用) |
| # open | 当前被打开(挂载)的次数 |
| LV Size | 逻辑卷的总大小 |
| Current LE | 此逻辑卷由多少个LE组成 |
| Segments | 此逻辑卷由多少个物理段落组成 如果值>1,通常意味着它跨越了多块物理硬盘 |
附带-m参数,可以查看一个LV是如何映射到LE和PE上的
lvdisplay -m /dev/my_vg/data_lv
输出:
--- Logical volume ---
LV Path /dev/my_vg/data_lv
VG Name my_vg
... (其他信息) ...
--- Segments ---
Segment 1
Logical extent 0 to 12799:
Type linear
Physical volume /dev/sda2
Physical extents 0 to 12799
Segment 2
Logical extent 12800 to 25599:
Type linear
Physical volume /dev/sdb1
Physical extents 10240 to 22039
-
--- Segments ---这表示
data_lv这个逻辑卷由两个段组成(因为它跨越了两块盘) -
Segment 1:
Logical extent 0 to 12799:表示这个LV的第0到12799号LEPhysical volume /dev/sda2:这部分数据**存储在/dev/sda2**这个PV上Physical extents 0 to 12799:它对应着/dev/sda2上的第0到12799号PE
-
Segment 2:
-
Logical extent 12800 to 25599:表示这个LV的第12800到25599号LE -
Physical volume /dev/sdb1:这部分数据**存储在/dev/sdb1**这个PV上 -
Physical extents 10240 to 22039:它对应着/dev/sdb1上的第10240到22039号PE注意,这里的PE编号是相对于PV的,不一定从0开始,取决于这个PV的PE使用情况
-
LVM元数据的存储位置
LVM元数据绝大部分都是以人类可读的明文形式直接记录在磁盘上
这些信息被存储在LVM的一个专属区域中,位于每一个PV的头部
一个PV的头部结构大致如下:
-
LVM 标签
这是一个二进制的数据块,有魔数,也记录了元数据区的偏移量和大小
-
**LVM元数据区 **
它包含一个头部信息(描述元数据本身)和紧随其后纯文本配置块
-
数据区
紧跟在元数据区之后,是真正存储用户数据的区域,被划分成一个个PE
具体位置在网上没找到统一的说法,如果无法使用命令查看,就磁盘搜索metadata、VG名称之类的标志性字段吧