早就想学了,正好学校选修了这门课,跟着老师的进度记录一下
体系结构
x86 与 x64
x86(focus:IA-32)
一个基于Intel8086处理器,向后兼容的指令集体系结构(ISA,Instruction Set Architecture)的总称
我们通常所说的x86逆向,主要指的是其32位版本,即IA-32(Intel Architecture, 32-bit)
IA-32架构有三种主要操作模式:
-
实模式
16位运行环境,是早期MS-DOS等操作系统使用的模式
-
保护模式
现代操作系统所采用的模式,支持虚拟内存、分页等高级特性,为程序提供了独立的、受保护的内存空间
-
系统管理模式
用于执行固件中的特殊系统管理代码
x64
也称为x86-64,是x86体系结构的64位扩展,它完全兼容IA-32,意味着32位程序可以在64位系统上运行
字节序
字节序定义了多字节数据(如一个4字节的整数)在内存中是如何排列的
小端序
数据的低位字节存储在内存的低地址处
这是Intel x86/x64架构使用的模式,因其电路设计和数据处理效率较高
大端序
数据的高位字节存储在内存的低地址处
这种方式更符合人类的阅读习惯,常见于一些RISC架构的处理器
一个例子
现在需要存储一个4字节的整数0x12345678
| 内存地址 | 大端序存储 | 小端序存储 |
|---|---|---|
| 低地址 | 12 |
78 |
| ↓ | 34 |
56 |
| ↓ | 56 |
34 |
| 高地址 | 78 |
12 |
在逆向分析中,内存二进制地址方向是从上至下,从左至右增大
因此,当我们在内存窗口看到78 56 34 12时,须将其理解为0x12345678
IA-32 内存
内存模型
平面内存模型
现代操作系统普遍采用的模型
程序的所有部分(代码、数据、栈)都位于一个连续统一的线性地址空间中

分段内存模型
程序被划分为多个独立的段,比如有代码段、数据段、栈段等
一个逻辑地址由段选择器和段内偏移两部分组成:
逻辑地址 = 段寄存器中的段选择器/段选择子 + 段内偏移量
段选择子是一个16位的值,它存放在段寄存器里,二进制结构如下:
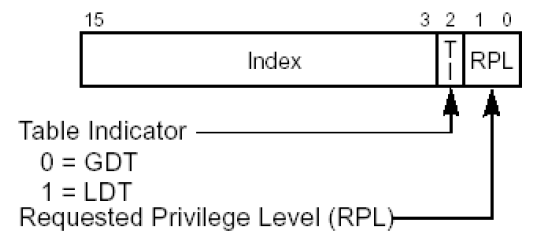
| 位段 | 名称 | 含义 |
|---|---|---|
| Index | 描述符索引 | 表示该段描述符在描述符表中的序号 |
| TI | 表标志 | 指示去哪个描述符表查段描述符(0是GDT,1是LDT) |
| RPL | 请求特权级 | 用于访问权限控制(0最高,3最低) |
而汇编代码里一般只写偏移量,段选择器是隐含的,CPU自动知道用哪个段寄存器
比如mov EAX, [0x0010],就相当于是mov EAX, DS:[0x0010]
| 汇编语句类型 | 默认段寄存器 |
|---|---|
mov eax, [offset] |
DS |
mov [offset], eax |
DS |
栈操作(push / pop) |
SS |
| 代码取指令 | CS |
分段内存模型的内存管理
对于分段内存模型,不同操作模式(实模式/保护模式)下,内存管理方式和寻址模式存在差异
实模式下的内存管理
管理方式
实模式的内存管理方式非常简单,可以看作是一种特殊的分段模型
-
有20位地址总线,CPU能够访问的物理内存上限为1MB的地址空间
-
内存被划分为一系列64KB大小的段
程序使用的地址由两部分组成:
一个16位的段选择器和一个16位的偏移地址
通过将段选择器的值左移4位,相当于乘以16(因为地址线是20位),加上16位的偏移地址得到物理地址
物理地址 (20-bit) = 段选择器 (16-bit)*16 + 偏移量 (16-bit)

示例
假设段寄存器DS的值为0x1000,指令要访问的偏移地址是0x0123
- CPU取出段选择器的值:
0x1000 - 将其左移4位:
0x10000 - 加上偏移地址:
0x10000 + 0x0123 - 最终得到的物理地址是
0x10123
实模式没有内存保护机制,任何程序都可以访问全部1MB的内存空间,一个程序的错误可能会导致整个系统崩溃,也不支持虚拟内存等现代操作系统的核心功能
保护模式下的内存管理
总体流程
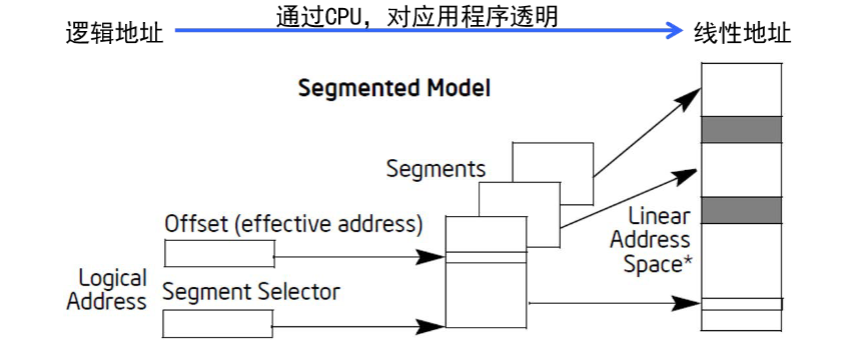
在保护模式下,我们代码中使用的地址(逻辑地址)需要经过CPU的转换才能访问到真正的物理内存
这个过程对程序是透明的
保护模式的地址管理必须使用分段,另外也可以选择使用分页
下图是完整的地址访问流程:
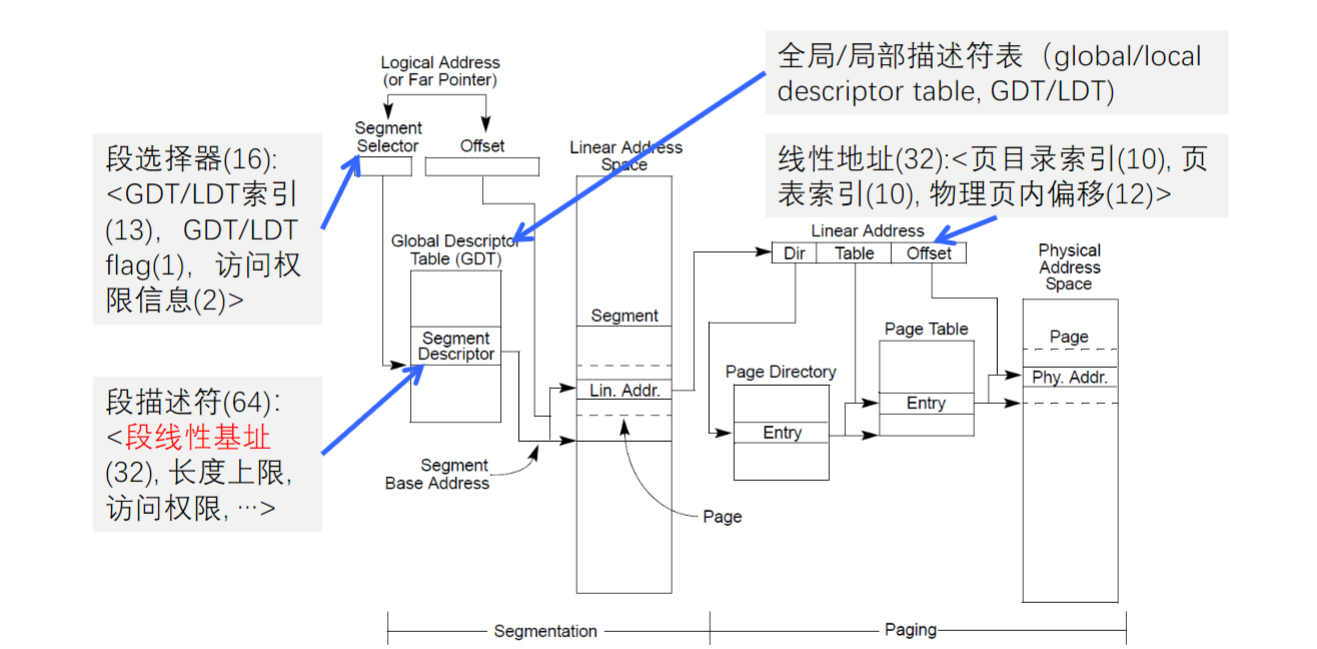
逻辑地址 → 线性地址
逻辑地址的段选择器告诉CPU该去哪一个描述符表(GDT/LDT)查询得到段描述符
段描述符里存有段基址、段界限、访问权限等内容
线性地址 = 段基址 + 偏移量
线性地址 → 物理地址
如果没有开启分页机制**,那么:
物理地址 = 线性地址
但是现代操作系统一般都启用了分页,CPU的内存管理单元 (MMU) 会进行下一步转换
MMU将32位的线性地址拆分为三部分:页目录索引 (10位) + 页表索引 (10位) + 页内偏移 (12位)
- 页目录表:有1024个表项,每项4B,共4KB,每项指向一个页表
- 页表:也有1024个表项,每项4B,共4KB,每项指向一个物理页框
- 页框:大小固定为4KB
先查页目录,再查页表,最终找到数据所在的物理内存页,加上页内偏移,就得到了最终的物理地址
物理地址 = 物理页框基址 + 页内偏移
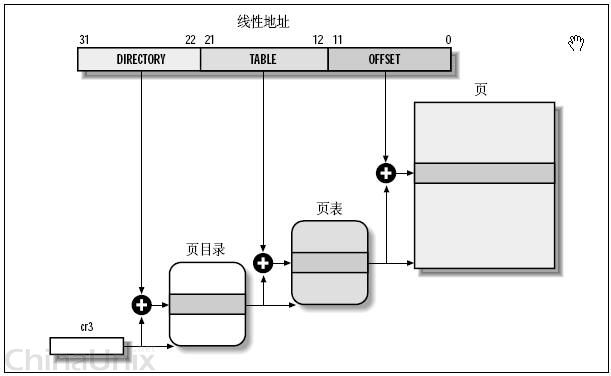
示例
我们现在运行在一个 32位保护模式的系统中,分页功能已经开启,程序中有这样一条指令:
mov eax, [0x1234]
这条指令的意思是把内存中地址DS:0x1234处的数据读到EAX寄存器中,也就是说,这里访问的逻辑地址是:
逻辑地址 = DS : 0x1234
假设段寄存器DS的内容是0x0008,二进制表示:
0000 0000 0000 1000b
| 字段 | 位 | 值 | 含义 |
|---|---|---|---|
| Index | 15:3 | 1 | 第1个描述符 |
| TI | 2 | 0 | 从GDT中查 |
| RPL | 1–0 | 0 | 当前访问特权级 0 |
假设GDT[1]这个描述符里存的段信息是:
| 字段 | 值 |
|---|---|
| 段基址 | 0x00400000 |
| 段界限 | 0x000FFFFF |
| 访问属性 | 可读可写数据段 |
于是:
段基址 = 0x00400000
线性地址 = 段基址 + 偏移量 = 0x00400000 + 0x00001234 = 0x00401234
现在系统开启了分页,假设页目录基址寄存器CR3的值是0x00100000,即页目录表在物理内存0x00100000处
把线性地址0x00401234拆成三段,二进制表示:
0000 0000 0100 0000 0001 0010 0011 0100
| 部分 | 位数 | 值(二进制) | 十进制 |
|---|---|---|---|
| 页目录索引 | 10 位 | 0000000001 | 1 |
| 页表索引 | 10 位 | 0000000010 | 2 |
| 页内偏移 | 12 位 | 001101000100 | 0x234 |
页目录表起始于0x00100000,每个表项占4字节,页目录索引是1,所以要读的表项地址:
0x00100000 + 1 * 4 = 0x00100004
假设这个页目录项内容是0x00200003
- 高20位:页表的物理基址,是
0x00200000 - 低12位:标志位(Present=1, RW=1, US=0)
页表基址0x00200000,页表索引是2,所以要读的表项地址:
0x00200000 + 2 * 4 = 0x00200008
假设这个页表项内容是0x00A00003
- 高20位:物理页框基址,是
0x00A00000
最终得到物理地址:
物理地址 = 页框基址 + 页内偏移 = 0x00A00000 + 0x00000234 = 0x00A00234
IA-32核心寄存器
通用寄存器 (GPR)
IA-32架构有8个32位通用寄存器
| 32位 | 16位 | 8位高/低 | 主要功能 |
|---|---|---|---|
| EAX | AX | AH / AL | 累加器(Accumulator) 用于算术运算和函数返回值 |
| EBX | BX | BH / BL | 基址寄存器(Base) 用于在内存中寻址 |
| ECX | CX | CH / CL | 计数器(Counter) 用于循环和字符串操作的计数,是无符号计数器 |
| EDX | DX | DH / DL | 数据寄存器(Data) 配合EAX进行乘除法运算或存放I/O指针 |
| ESI | SI | - | 源变址寄存器(Source Index) 字符串和内存操作的源地址 |
| EDI | DI | - | 目的变址寄存器(Destination Index) 字符串和内存操作的目的地址 |
| ESP | SP | - | 栈指针(Stack Pointer) 永远指向当前栈的栈顶 |
| EBP | BP | - | 基址指针(Base Pointer) 用作当前函数栈帧的基址,用于访问局部变量和参数 |
程序状态与控制寄存器 (EFLAGS)
EFLAGS寄存器是一个32位的寄存器
它的每一位(标志位)都记录了程序运行中的特定状态,主要用于条件判断和流程控制
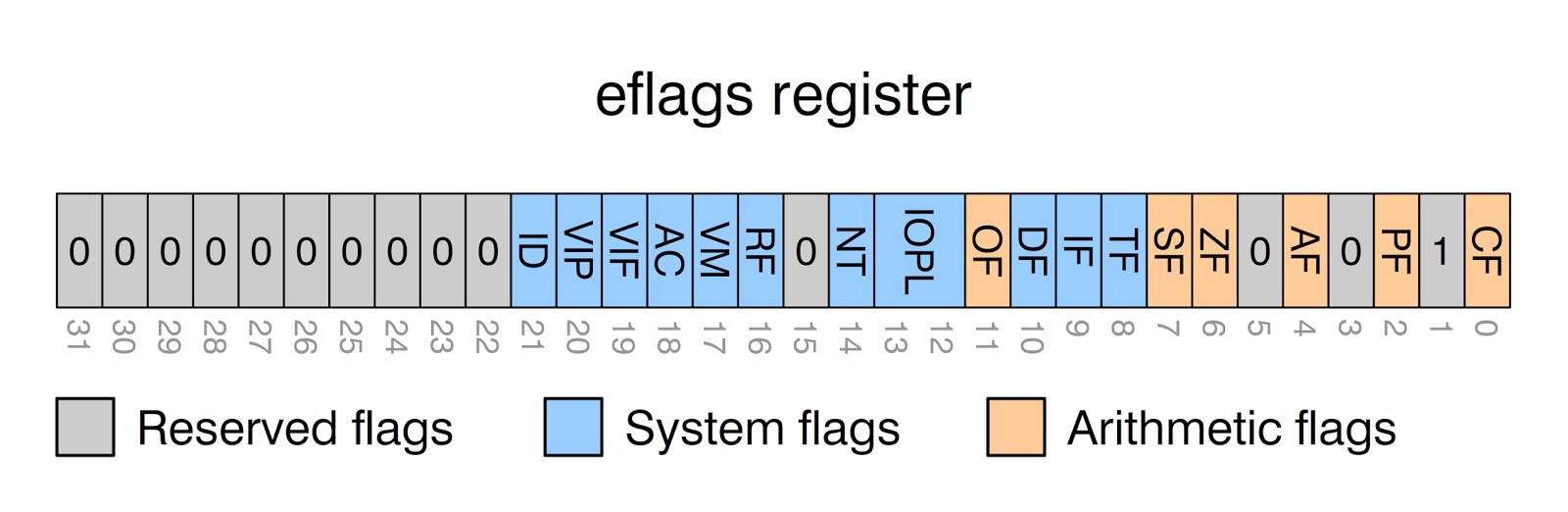
下面是一些常用的标志位:
| 标志位 | 名称 | 描述和功能 |
|---|---|---|
| ZF | 零标志 (Zero Flag) |
若算术运算结果为0,则ZF置为1,否则为0,常用于判断相等 |
| OF | 溢出标志 (Overflow Flag) |
当有符号整数运算的结果超出寄存器能表示的范围时,OF置为1 |
| CF | 进位标志 (Carry Flag) |
当无符号整数运算的结果溢出(产生进位或借位)时,CF置为1 |
| SF | 符号标志 (Sign Flag) |
等于运算结果的最高位(也就是符号位) 对于有符号数,0表示正数,1表示负数 |
| DF | 方向标志 (Direction Flag) |
控制字符串操作指令(如MOVS, SCAS)的处理方向 若DF=0,变址寄存器(ESI, EDI)地址递增 若DF=1,则地址递减 |
| TF | 陷阱标志 (Trap Flag) |
若置为1,CPU在执行每条指令后会产生一个单步中断 |
| IF | 中断允许标志 (Interrupt Enable Flag) |
若置为1,CPU可以响应外部设备的中断请求 |
指令指针寄存器 (EIP)
EIP(Extended Instruction Pointer)是一个32位的寄存器,存放着下一条将要被CPU执行的指令的地址
CPU总是根据CS段寄存器和EIP寄存器中的地址来读取下一条指令,每当一条指令被读取后,EIP的值会自动增加,增加的大小等于刚刚被读取指令的字节数,从而指向紧随其后的下一条指令
EIP寄存器的值不能被直接修改,它的改变只能通过特定的控制流指令(如 JMP, CALL, RET)或者由中断、异常来完成
段寄存器
段寄存器是6个16位的寄存器,在保护模式的内存分段管理中,它们存放着指向各个内存段的“段选择器”,CPU通过这些段选择器在系统描述符表(GDT/LDT)中找到段的实际基地址。
| 寄存器 | 名称 | 主要功能 |
|---|---|---|
| CS | 代码段寄存器 (Code Segment) |
存放应用程序代码所在段的段选择器 |
| SS | 栈段寄存器 (Stack Segment) |
存放当前程序栈所在段的段选择器 |
| DS | 数据段寄存器 (Data Segment) |
存放程序主要数据所在段的段选择器 |
| ES/FS/GS | 附加数据段寄存器 (Extra Segment) |
存放程序使用的附加数据段的段选择器 可用于特殊目的,比如通过FS定位线程环境块(TEB)等 |
IA-32数据类型
基本数据类型
这些是构成更复杂数据结构的基础整数类型
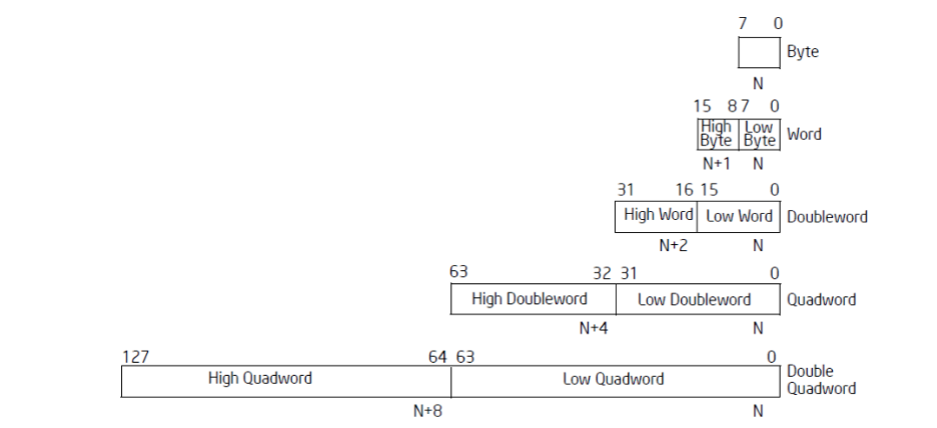
-
Byte
1字节(8位)的数据
-
Word
2字节(16位)的数据
-
Doubleword
4字节(32位)的数据
这是IA-32架构中最常用的数据大小,与通用寄存器(如EAX)的大小一致
-
Quadword
8字节(64位)的数据
虽然IA-32没有64位的通用寄存器,但在某些特定指令(如
RDTSC)或通过组合EDX和EAX寄存器,可以处理64位数据 -
Double Quadword
16字节(128位)的数据
浮点数据类型
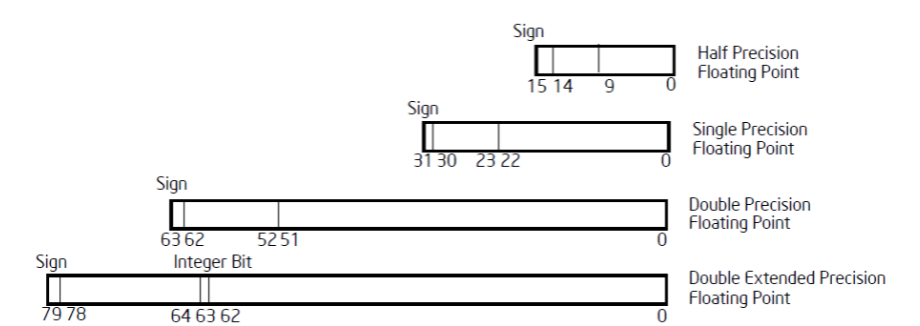
- 半精度(Half Precision):16位浮点数
- 单精度(Single Precision):32位浮点数
- 双精度(Double Precision):64位浮点数
- 扩展双精度(Double Extended Precision):80位浮点数
指针类型
指针在IA-32中用于存储内存地址,主要分为两种

-
Near Pointer(近指针)
这是一个32位的偏移量
它指向当前段内的某个地址,在现代操作系统的平面内存模型下,这实际上就是程序的虚拟地址
-
Far Pointer(远指针)
这是一个48位的指针,由一个16位的段选择器和一个32位的偏移量组成
它用于在分段内存模型下,跨段访问数据
IA-32汇编指令
Intel与AT&T汇编语法
Intel语法
这是Windows环境下的主流语法,易于阅读
[指令] [目标操作数], [源操作数]
逗号后面空格不是语法必须的,但是加空格是一个非常推荐的习惯,大多数逆向软件也遵从这个习惯
本文档后续将统一使用Intel语法
AT&T语法
常用于Linux和GNU工具链
[指令] [源操作数], [目标操作数]
示例
将立即数4移动到EAX寄存器
| 语法 | 指令 |
|---|---|
| Intel | mov eax, 4 |
| AT&T | mov $4, %eax |
数据移动指令
这类指令用于在寄存器、内存和立即数之间传递数据
MOV:数据传送
MOV(move)是数据传送指令,将右边操作数的值复制到左边操作数中
但是这两个操作数中最多只能有一个是内存操作数(带方括号的那种),另一个必须是寄存器或立即数
立即数 -> 寄存器
将常量0x12345678放入ESI
MOV ESI, 0x12345678
寄存器 -> 寄存器
将ECX的内容复制到EAX
MOV EAX, ECX
立即数 -> 内存
将地址为EAX的4字节内存设为1
MOV DWORD PTR [EAX], 1
[EAX]表示取EAX寄存器中的值作为内存地址
DWORD PTR表示操作的内存数据大小是4字节(32 位)
当汇编器不清楚要操作内存的大小时,就需要使用修饰符来确定,以下是常用的修饰符:
| 修饰符 | 大小 | 说明 |
|---|---|---|
| BYTE PTR | 1 字节(8 位) | 访问 8 位数据 |
| WORD PTR | 2 字节(16 位) | 访问 16 位数据 |
| DWORD PTR | 4 字节(32 位) | 访问 32 位数据 |
| QWORD PTR | 8 字节(64 位) | 访问 64 位数据 |
| NEAR PTR | 2/4 字节偏移 | 近指针,只包含偏移,段寄存器不变,常用于近调用 |
| FAR PTR | 段 + 偏移 | 远指针,包含段选择符和偏移,常用于跨段调用 |
寄存器 -> 内存
将EBX的值写入地址为EAX的内存中
MOV [EAX], EBX
将EAX的值写入地址为ESI+0x34的内存中
MOV [ESI+34H], EAX
注意这里的[]不能拆开写!
内存 -> 寄存器
将地址为ECX的内存中的值读入EAX
MOV EAX, [ECX]
将地址为ECX+EAX的内存中的值读入EDX
MOV EDX, [ECX+EAX]
将内存中地址0x50处的数据读入寄存器EAX
MOV EAX, [0x50]
LEA:加载有效地址
LEA (Load Effective Address) 用于计算源操作数指定的内存地址,并将地址加载到目标寄存器中
它与MOV的关键区别在于,MOV会访问该地址并取出其中的数据,而LEA只计算地址,不访问内存
也正因如此,使用LEA计算时,寄存器必须加上[]表示取地址
计算内存地址
假设EAX = 0x1000, 内存地址0x1000处的值为0xABCD
使用MOV:
MOV EBX, [EAX]
MOV将地址EAX(0x1000)指向的数据0xABCD放入EBX,结果是EBX = 0xABCD
使用LEA:
LEA EBX, [EAX]
LEA将地址表达式[EAX]本身的值0x1000放入EBX,结果是EBX = 0x1000
执行快速数学运算
LEA可以执行一些基础的数学运算,且比使用ADD或MUL等指令更高效,因为它不影响CPU的标志位
计算EAX = EBX + ECX * 4 + 100H:
LEA EAX, [EBX + ECX*4 + 100H]
注意这里的[]不能拆开写!
串操作
这类指令专门用于高效处理内存中的连续数据块(字符串)
它们通常与 REP 系列前缀结合使用,以重复执行相同的操作,重复次数由 ECX 寄存器控制
REP系列前缀
REP
全称REPeat,在执行指令前会检查ECX,指令会重复执行ECX次
eg:
MOV ECX, 5 ; 重复次数
REP MOVSB ; 将[ESI]的字节移动到[EDI],重复5次
REPE / REPZ
全称REPeat While Equal / REPeat While Zero,当ZF=1且ECX不为0时继续重复
eg:
MOV ECX, 10
REP CMPSB ; 比较两个字符串,ZF=1时继续,最多10次
REPNE / REPNZ
全称REPeat while Not Equal / REPeat while Not Zero,当ZF=0且ECX不为0时继续重复
eg:
MOV ECX, 10
REPNE SCASB ; 扫描字符串,ZF=0时继续,最多10次
索引增减控制指令CLD/STD
EFLAGS寄存器中的DF标志位决定了每次操作后ESI和EDI的变化方向,而CLD和SLD指令控制着DF
CLD指令
全称Clear Direction Flag,DF = 0,ESI和EDI在每次操作后递增
STD指令
全称Set Direction Flag,DF = 1,ESI和EDI在每次操作后递减
取地址运算符OFFSET
OFFSET是汇编语言中的一个编译时运算符,作用是取得一个标号(变量、数组等)的内存地址(偏移量)
比如我在数据段(.data)定义一个变量:
.data
SourceAddress DB 'A', 'B', 'C', 0
假设编译器把这段数据放在内存地址0x00405000
那么OFFSET SourceAddress在汇编时就会被计算为0x00405000
这里的DB被称作伪指令
它不是CPU执行的指令,是给汇编器用的命令,告诉汇编器在程序中生成数据、定义常量或分配空间
类似伪指令还有:
| 指令 | 全称 | 定义单位 | 示例 |
|---|---|---|---|
DB |
Define Byte | 1 字节 | DB 1, 2, 3 |
DW |
Define Word | 2 字节 | DW 1234h |
DD |
Define Doubleword | 4 字节 | DD 0x12345678 |
DQ |
Define Quadword | 8 字节 | DQ 0x1122334455667788 |
MOVSB / MOVSW / MOVSD:移动字符串
MOVS(Move String)指令用于将数据从源地址DS:ESI复制到目标地址ES:EDI
根据指令后缀,它每次可以复制1、2或4个字节
MOVSB:移动1字节(Byte)MOVSW:移动2字节(Word)MOVSD:移动4字节(Double Word)
下面的代码是使用REP MOVSD将源地址的32字节数据复制到目标地址:
;设置参数
MOV ESI, OFFSET SourceAddress ; 将源地址加载到ESI
MOV EDI, OFFSET DestAddress ; 将目标地址加载到EDI
MOV ECX, 8 ; 设置重复次数 (8次*4字节/次=32字节)
;执行复制
CLD ; 清除方向标志位(DF=0),确保ESI和EDI递增
REP MOVSD ; 重复执行MOVSD指令ECX次,即8次
STOSB / STOSW / STOSD:存储字符串
STOS(Store String)指令用于将AL/AX/EAX寄存器中的值存储到ES:EDI指向的内存地址
它常用于初始化一块内存区域
STOSB:将AL的内容存入[EDI]STOSW:将AX的内容存入[EDI]STOSD:将EAX的内容存入[EDI]
以下代码演示了如何将EDI指向的 36 字节内存块全部设置为 0
;设置参数
MOV EDI, ESI ; 设置目标内存地址 (假设地址已在ESI中)
XOR EAX, EAX ; 将EAX清零,这是我们要写入的值
MOV ECX, 9 ; 设置重复次数 (9次*4字节/次=36字节)
;执行写入
CLD ; 确保EDI递增
REP STOSD ; 重复执行STOSD指令ECX次,将EAX(0)连续写入目标内存
XOR EAX, EAX效果和MOV EAX, 0一样,都是将寄存器值置零,但是会更加高效
这是因为CPU看到XOR reg, reg这种特殊模式,会自动识别为清零优化,不会依赖旧值
Intel官方优化手册明确指出:
“Zero idioms such asXOR reg, regorSUB reg, regare recognized by the processor and are handled specially — they do not create a dependency on the old register value.”
SCASB / SCASW / SCASD:扫描字符串
SCAS(Scan String)指令用于将AL/AX/EAX寄存器中的值与ES:EDI指向的内存值进行比较,并根据比较结果设置EFLAGS寄存器的标志位
- 寄存器值等于内存值:
ZF = 1 - 寄存器值不等于内存值:
ZF = 0
它常用于在字符串中搜索特定字符
SCASB:比较AL和[EDI]SCASW:比较AX和[EDI]SCASD:比较EAX和[EDI]
下面的代码展示了如何计算一个以\0(NULL)结尾的字符串的长度
;设置参数
MOV EDI, EBX ; 假设字符串的起始地址在EBX中,将其加载到EDI
XOR AL, AL ; 将AL设置为0,即我們要查找的字符串结束符'\0'
MOV ECX, -1 ; 将ECX设为最大值,以扫描任意长度的字符串
;执行扫描
CLD ; 确保EDI递增
REPNE SCASB ; 当AL!=[EDI]时重复扫描,每次扫描EDI都会递增,直到找到'\0'或扫描完ECX次
; 找到'\0'后,EDI指向'\0'字符的下一个字节
;计算长度
NOT ECX ; 对ECX按位取反,得到扫描过的字符数
DEC ECX ; 让ECX减一,即减去最后的'\0'字符,得到字符串的实际长度
; 最终长度存储在ECX中
MOV ECX, -1这一步是为了什么?
在底层机器码中,-1并不会以负号形式存储,而是使用补码表示,而32位补码中-1 = 0xFFFFFFFF
所以这条指令本质上等价于:
MOV ECX, 0xFFFFFFFF
这样就把ECX设为了最大值0xFFFFFFFF,而ECX是无符号计数器,递减就从这个极大数开始,而不是-1
SCASB每执行一次,会自动让ECX减1,我们不知道字符串长度是多少,所以干脆从最大值开始扫
看看类似的用法:
| 汇编写法 | 实际数值 | 寄存器值 |
|---|---|---|
MOV ECX, 0 |
0 | 0x00000000 |
MOV ECX, 1 |
1 | 0x00000001 |
MOV ECX, -1 |
-1 | 0xFFFFFFFF |
MOV ECX, -2 |
-2 | 0xFFFFFFFE |
算术与位运算指令
这类指令用于执行基本的数学计算和位级操作
ADD / SUB:加法 / 减法
执行加法或减法运算,并将结果存回目标操作数
ADD dest, src ; 结果是dest = dest + src
SUB dest, src ; 结果是dest = dest - src
INC / DEC:加一 / 减一
将操作数的值增加1或减少1,比等效的 ADD/SUB 指令更短、更快
INC ECX ; 结果是ECX = ECX + 1
DEC EAX ; 结果是EAX = EAX - 1
NEG:取补
通过执行按位取反后加一的操作来获得操作数的算术相反数(补码)
NEG EBX ; 结果是EBX = -EBX
IMUL / MUL:有符号 / 无符号乘法
执行乘法运算,根据操作数的数量,用法有所不同
| 指令 | 操作数形式 | 结果寄存器 | 是否占用EDX | 特点 |
|---|---|---|---|---|
MUL SRC |
单操作数 | EDX:EAX | 是 | 完整64位结果,无符号 |
IMUL SRC |
单操作数 | EDX:EAX | 是 | 完整64位结果,有符号 |
IMUL DEC, SRC |
双操作数 | ECX | 否 | 只保留低32位,有符号 |
IMUL DEC, SRC, 立即数 |
三操作数 | ECX | 否 | 可立即数乘,有符号 |
单操作数(IMUL和MUL都支持)
将EAX与指定操作数相乘,结果是一个64位数,高32位存入EDX,低32位存入EAX
MOV EAX, -2 ; EAX = 0xFFFFFFFE
MOV EBX, 3
IMUL EBX ; EAX * EBX = -6 -> EDX:EAX = 0xFFFFFFFF:0xFFFFFFFA
MUL EBX ; EAX * EBX = 4294967290 -> EDX:EAX = 0x00000002:0xFFFFFFFA
多操作数(只有IMUL支持)
提供更高的灵活性,,可指定目标寄存器,结果直接存入目标寄存器,不分高低位,不占用EDX
MOV EBX, 3
IMUL EAX, EBX ; EAX = EAX * EBX
IMUL ECX, EBX, 5 ; ECX = EBX * 5 = 20
; 也可以直接指定内存,假设 [0x123] = -3
IMUL ECX, [0x123], 5 ; ECX = -3 * 5 = -15
IDIV / DIV:有符号 / 无符号除法
执行除法运算
| 位宽 | 被除数寄存器 | 商寄存器 | 余数寄存器 |
|---|---|---|---|
| 8位 | AX | AL | AH |
| 16位 | DX:AX | AX | DX |
| 32位 | EDX:EAX | EAX | EDX |
无符号的DIV
MOV EAX, 20 ; 低 32 位被除数
MOV EDX, 0 ; 高 32 位被除数
MOV EBX, 6 ; 除数
DIV EBX
; EAX = 20 / 6 = 3 (商)
; EDX = 20 % 6 = 2 (余数)
有符号的IDIV
MOV EAX, -20
MOV EDX, 0
MOV EBX, 6 ; 除数
IDIV EBX
; EAX = -20 / 6 = -3 (商)
; EDX = -20 % 6 = -2 (余数)
AND / OR / XOR:按位与 / 或 / 异或
对操作数进行按位逻辑运算,结果存回第一个操作数
| 指令 | 运算类型 | 说明 |
|---|---|---|
| AND | 按位与 | 两位都为1时结果为1,否则为0 |
| OR | 按位或 | 两位有1时结果为1,否则为0 |
| XOR | 按位异或 | 两位不同时结果为1,相同为0 |
AND EAX, 0x0F ; 取低4位,清除高28位
OR EAX, EBX ; 将EBX中为1的位合并到EAX
XOR EAX, 0xFFFFFFFF ; 按位取反
之前提到过的XOR EAX, EAX是将EAX寄存器清零的最快方式,CPU能识别这种特殊形式并进行优化,不产生对旧值的依赖,因此比MOV EAX, 0更高效
NOT:按位取反
将操作数的每一位反转(0变1,1变0)
MOV EAX, 0x0F ; 二进制0000 0000 0000 1111
NOT EAX ; 变成1111 1111 1111 0000 = 0xFFFFFFF0
SHL / SAL / SHR / SAR:逻辑 / 算数 的 左移 / 右移
将操作数的位向左或向右移动,空出的位用0填充
| 指令 | 运算 | 填充位 | 运算结果 |
|---|---|---|---|
| SHL / SAL | 左移 | 低位补 0 | 左移N位=乘以$2^N$ |
| SHR | 逻辑右移 | 高位补 0 | 右移N位=无符号除以$2^N$ |
| SAR | 算术右移 | 高位补符号位 | 右移N位=有符号除以$2^N$(保留符号) |
MOV EAX, 3
SHL EAX, 2 ; EAX = 3 << 2 = 12 (3*2^2)
SAL EAX, 2 ; 和SHL完全一样
MOV EBX, 16 ; 0x00000010
SHR EBX, 2 ; EBX = 16 >> 2 = 4 (无符号除以 4)
MOV ECX, -16 ; 0xFFFFFFF0
SAR ECX, 2 ; ECX = -16 >> 2 = -4 (保留符号)
ROL / ROR:循环左移 / 右移
将操作数的位向左或向右移动,移出的位会从另一端循环回来填充空位
MOV AL, 10010011b ; 二进制数 10010011,AL = 0x93
ROL AL, 2 ; AL = 01001110b, 原高2位“10”循环到低位
ROR AL, 3 ; AL = 11001001b, 低3位“110”循环到高位
控制流指令
这类指令通过修改EIP(指令指针)寄存器的值来改变程序的执行流程,从而实现分支、循环等结构
比较指令
这两个指令通过执行内部运算来改变EFLAGS寄存器中的状态标志位,但不会修改操作数本身
它们为后续的条件跳转指令提供判断依据
CMP:减法比较
内部执行A - B的减法运算
MOV EAX, 5
CMP EAX, 3 ; 实际执行 5 - 3
JG greater ; 如果 EAX > 3, 跳转
TEST:AND比较
内部执行A AND B的按位与运算
eg1:检测寄存器是否为0
TEST EAX, EAX ; A AND A
JZ is_zero ; 如果结果为 0 (ZF=1),跳转
eg2:检测某一位是否为1
TEST AL, 1 ; 检查最低位是否为 1
JNZ odd_number ; 若最低位为1(奇数),跳转
JMP:无条件跳转
JMP(Jump)指令会立即无条件地将程序的执行点转移到指定的目标地址
基本语法:
JMP label
label可以是同一段代码内的标签(短跳转或近跳转),也可以是其他段的地址(远跳转)
MOV EAX, 0 ; EAX = 0
JMP skip ; 无条件跳转到 skip 标签
MOV EAX, 5 ; 这一行永远不会被执行!
skip:
MOV EAX, 1 ; 执行到这里
Jcc:条件跳转
Jcc (Jump on Condition) 是一系列指令的统称
它们在CMP或TEST指令之后,根据EFLAGS寄存器的状态来决定是否进行跳转
| 指令 | 跳转条件(基于 EFLAGS) | 含义(中文描述) | 比较类型 |
|---|---|---|---|
| JE / JZ | ZF = 1 |
相等 / 结果为零 | 通用 |
| JNE / JNZ | ZF = 0 |
不相等 / 结果非零 | 通用 |
| JG / JNLE | ZF = 0 AND SF = OF |
大于(有符号数) | 有符号 |
| JGE / JNL | SF = OF |
大于等于(有符号数) | 有符号 |
| JL / JNGE | SF ≠ OF |
小于(有符号数) | 有符号 |
| JLE / JNG | ZF = 1 OR SF ≠ OF |
小于等于(有符号数) | 有符号 |
| JA / JNBE | CF = 0 AND ZF = 0 |
大于(无符号数) | 无符号 |
| JAE / JNB | CF = 0 |
大于等于(无符号数) | 无符号 |
| JB / JNAE | CF = 1 |
小于(无符号数) | 无符号 |
| JBE / JNA | CF = 1 OR ZF = 1 |
小于等于(无符号数) | 无符号 |
| JS | SF = 1 |
结果为负 | 通用 |
| JNS | SF = 0 |
结果为正或零 | 通用 |
| JO | OF = 1 |
溢出发生 | 通用 |
| JNO | OF = 0 |
无溢出 | 通用 |
| JC | CF = 1 |
进位(或借位)发生 | 通用 |
| JNC | CF = 0 |
无进位 / 无借位 | 通用 |
| JP / JPE | PF = 1 |
奇偶标志为偶(结果1个数为偶数) | 通用 |
| JNP / JPO | PF = 0 |
奇偶标志为奇 | 通用 |
跳转指令前缀
跳转指令前缀是汇编器用来指示跳转类型或范围的关键字
它不改变跳转的条件本身,只影响指令编码和偏移量大小,也就是CPU计算跳转地址时用多少字节表示偏移
这本质上是告诉CPU跳转目标离它有多远,CPU会选择合适的指令长度(1-6字节)存储偏移
| 前缀 | 偏移量大小 | 说明 |
|---|---|---|
| SHORT | 8位有符号偏移量 (-128 ~ +127) | 近距离跳转,小范围循环或if/else |
| NEAR | 16位或32位偏移量(同段跳转) | 目标在当前代码段内,距离较远 |
| FAR | 16/32位段内偏移 + 16位段选择子 | 跨段跳转,改变CS寄存器 |
条件跳转(Jcc)默认使用SHORT,如果目标太远,汇编器会自动转换为NEAR
流程控制结构示例
if-else结构
C语言:
if (*esi != 0) {
// block A
}
// block B
汇编:
MOV EDX, [ESI] ; EDX = *esi
TEST EDX, EDX ; 比较 EDX 和 0
JZ SHORT block_B ; 如果 EDX 为 0, 则跳转到 block_B
;block A 的代码
...
block_B:
;block B 的代码
for循环结构
C语言:
for (int i=0; i<10; i++) {
printf("%d\n", i);
}
汇编:
XOR ESI, ESI ; ESI = 0 (作为计数器 i)
LOOP_START:
;调用 printf 的代码
PUSH ESI
PUSH OFFSET FORMAT_STRING
CALL printf
ADD ESP, 8 ; 平衡堆栈
INC ESI ; i++
CMP ESI, 10 ; 比较 i 和 10
JL SHORT LOOP_START ; 如果 i < 10, 继续循环
栈与函数调用指令
栈
在IA-32架构下,栈是连续的内存区域,用于存储临时数据、函数参数和返回地址
-
栈存在于一个栈段内,由段寄存器SS指向段描述符
-
ESP寄存器所包含的栈指针永远指向栈顶位置,所有针对栈的操作都是基于
SS:ESP的地址引用
IA-32 的栈通常是高地址向低地址生长
栈帧
什么是栈帧
每当一个函数被调用时,都会在栈上为其分配一块专属空间,称为该函数的栈帧
栈帧用于存放函数的局部变量、传递给其他函数的参数以及保存调用者的上下文信息
栈帧的组成内容如下:
| 内容 | 说明 |
|---|---|
| 局部变量 | 函数内部声明的变量,存放在栈帧中 |
| 参数 | 调用被调用函数时压入栈的参数 |
| 栈帧相关指针 | 用于管理函数返回与栈帧切换 |
| 返回指令指针 | CALL指令将EIP(下一条指令地址)压栈,函数返回后跳转到这里执行 |
栈帧基指针(EBP)
EBP在函数调用时用作栈帧的固定参考点,方便访问局部变量和函数参数
基本栈操作:PUSH / POP
PUSH:压栈
将一个寄存器、内存或立即数的值压入栈顶
先将栈顶指针ESP减去一个单位,然后将操作数存入ESP指向的新地址:
-
栈向低地址扩展,IA-32下,一个单位4字节(32bit):
ESP = ESP - 4 -
将数据写入栈顶:
[ESP] = 操作数
MOV EAX, 0x1234
PUSH EAX ; ESP -= 4 , [ESP] = 0x1234
PUSH先减再存值
POP:出栈
从栈顶取出数据到寄存器或内存,并恢复栈指针
先将ESP指向地址的值取出到目标操作数,然后将ESP增加一个单位:
- 取出
[ESP]的值到目标操作数 - 栈指针上移,恢复原位置:
ESP = ESP + 4
POP EBX ; EBX = 栈顶值 , ESP += 4
POP先取值再加
调用与返回的分类
根据目标函数与调用者是否在同一个代码段,调用和返回可以分为两类
近调用 (Near Call) / 近返回 (Near Return)
控制流转移到当前代码段中的函数,或从当前代码段的函数返回
这是最常见的调用方式,用于访问程序内部的本地函数
远调用 (Far Call) / 远返回 (Far Return)
控制流转移到其他代码段中的函数,或从其他代码段返回
这种方式通常用于访问操作系统提供的服务(API)或其他进程的函数
CALL:调用函数
跳转到被调用函数,并保存返回地址以便函数执行完毕后回到调用点
近调用
- 压栈返回地址:
CALL指令会将下一条指令的地址(EIP) 压入栈顶 - 跳转到函数入口:CPU将EIP设置为被调用函数的起始地址
; 假设当前 EIP = 0x00401000
CALL my_function ; 1. 保存返回地址:PUSH 0x00401005 (CALL指令长度为5字节)
; 2. 跳转到my_function:JMP my_function
远调用
对于远调用,由于跨越了代码段,CPU不仅需要保存返回的地址偏移(EIP),还必须保存返回的段(CS),以便能够正确返回到调用者所在的原始代码段
- 压栈段寄存器CS:将当前代码段寄存器CS的值压入栈顶
- 压栈返回地址EIP:将EIP的当前值压入栈顶
- 跳转到函数入口:将目标函数的段选择器和偏移地址分别载入CS和EIP寄存器
CALL FAR PTR 2000h:0100h ; 远调用到 2000:0100
这里必须使用FAR PTR表示是远调用,否则会被当成近调用处理
RET:从函数返回
从栈顶取出返回地址,恢复执行流到调用者
近返回(RET/RETN)
- 弹出返回地址:从栈顶弹出一个32位的值到EIP寄存器
- 清理参数 (可选):
RET n会在弹出返回地址后,额外将ESP增加n字节,用于清理调用者压入栈的参数
RET ; 标准返回
RETN ; 近返回
RET 8 ; 返回并清理栈上 8 字节参数
此时就可以把RET理解为:
POP EIP
远返回(RETF)
- 弹出返回地址EIP:从栈顶弹出一个32位的值到EIP寄存器
- 弹出段寄存器CS:从栈顶弹出一个16位的值到CS寄存器
RETF ; 远返回
CPU不跟踪返回指令指针在栈上的位置,程序员必须确保在执行RET指令时,栈顶内容恰好是正确的返回地址
如果栈上的返回地址在RET执行前被修改(例如通过缓冲区溢出),程序的执行流就可能被劫持,这是一个常见的安全漏洞
调用约定
这是函数调用双方必须遵守的一套规则,它规定了参数如何传递、返回值如何返回、以及哪一方(调用者或被调用者)负责清理栈上的参数。
-
cdecl
C语言的默认约定,参数从右到左压栈,调用者负责清理栈
-
stdcall
Win32API常用,参数从右到左压栈,被调用者负责清理栈(通过
RET n) -
fastcall
stdcall的变种,前两个(或更多)参数通过ECX和EDX等寄存器传递,以提高速度,剩余参数压栈,被调用者负责清理
栈帧的创建与销毁(函数指令框架)
函数序言 (Prologue)
当执行CALL语句之后,函数开始时建立自己的栈帧
PUSH EBP ; 保存调用者的栈帧基址 (旧EBP)
MOV EBP, ESP ; 将当前栈顶设为新的栈帧基址
SUB ESP, 20H ; 让栈顶向低地址处延伸,以此为局部变量分配32字节空间
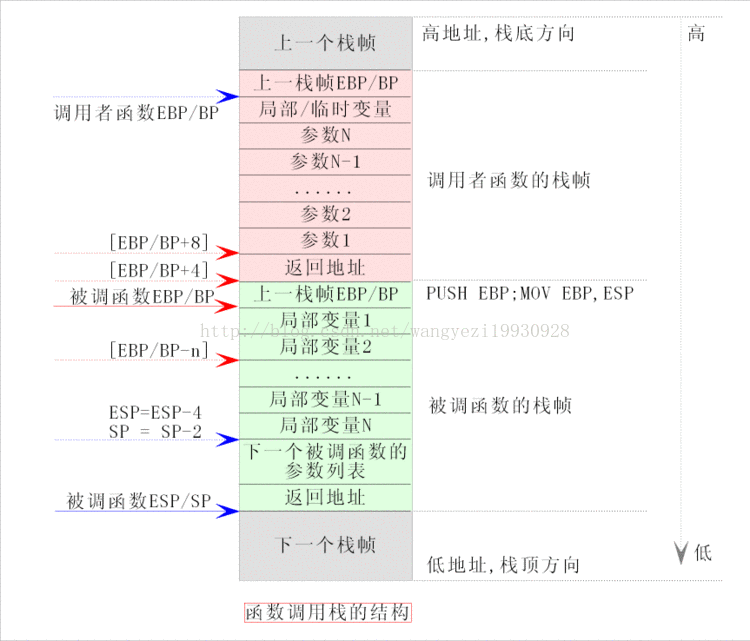
局部变量会放在EBP下面(地址更小),参数会放在EBP上面(地址更大),也就是这样访问:
[EBP + 8] ; 第一个参数(返回地址占用了4字节,所以从第8字节开始)
[EBP + 12] ; 第二个参数
[EBP - 4] ; 第一个局部变量
[EBP - 8] ; 第二个局部变量
函数结尾 (Epilogue)
函数返回前恢复调用者栈帧的标准操作
MOV ESP, EBP ; 释放局部变量空间
POP EBP ; 恢复调用者的栈帧基址
RET ; 返回
ENTER / LEAVE
高级指令,用于简化栈帧的创建和销毁
ENTER等价于函数序言,LEAVE等价于MOV ESP, EBP; POP EBP
也就是说,一个函数应该(不是必须)写在这样的框架里:
PUSH EBP
MOV EBP, ESP
;(函数主体,局部变量/操作)
MOV ESP, EBP
POP EBP
RET
或者:
ENTER
;(函数主体,局部变量/操作)
LEAVE
RET
调用流程总结
结合之前所说的一切,我们就总结出来一个函数被调用时触发的操作顺序:
- 调用者准备调用 (压入参数)
- 执行CALL指令 (压入返回地址)
- 函数序言 (压入调用者的EBP,为局部变量开辟空间)
- 函数主体 (压入局部变量)
那么当一个栈帧创建完毕,应该是这样的:
高地址
│ 参数 ← 函数调用者压入
│ 返回地址 ← call 自动压入
│ 旧 EBP(上一个EBP) ← push ebp 保存调用者基址
│ 局部变量
低地址
而在PUSH EBP之后,当前栈顶变成了栈帧的基址,也就是说帧创建完毕后,EBP和ESP位置如下:
高地址
│ 参数
│ 返回地址
│ 旧 EBP(上一个EBP)
[EBP位置]
│ 局部变量
[ESP位置]
低地址
此时[EBP]存放着调用者的EBP,[ESP]存放着最后一个局部变量(如果申请的空间用满了的话)
下面的图就很好展示了调用函数栈帧变化:
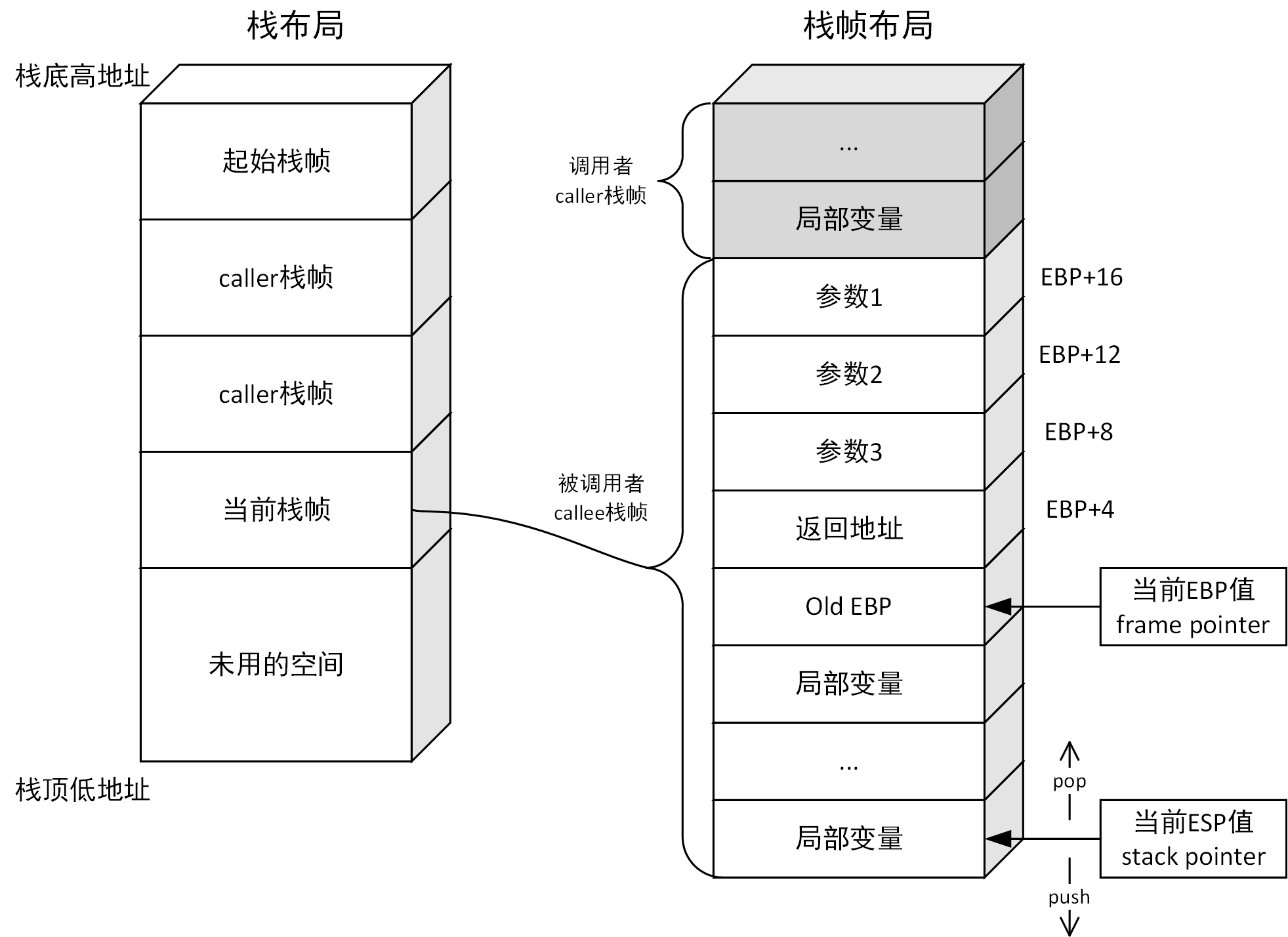
调用流程示例
举个例子,假设有这样一个程序:
main:
call foo
ret
foo:
push ebp
mov ebp, esp
sub esp, 4
mov DWORD PTR [ebp-4], 1 ;局部变量
push 1 ;传入bar的参数
call bar
mov esp, ebp
pop ebp
ret
bar:
push ebp
mov ebp, esp
sub esp, 4
mov esp, ebp
pop ebp
ret
进入main
EBP:main的旧EBP
ESP:main栈顶(局部变量区底)
高地址
┌───────────────────────┐
│ main 的参数(也许有也许没有) │
├───────────────────────┤
│ main 的返回地址 │ ← 调用者是CRT(C运行时)
├───────────────────────┤
│ 调用 main 的栈帧的EBP │ ← EBP 指向这里
├───────────────────────┤
│ main 的局部变量 │
└───────────────────────┘
低地址
call foo
main函数先把foo需要的参数压栈,之后call foo
call foo做了两件事:
1.把call下一条指令的地址,即当前EIP(指向call指令)+call指令长度,也即foo的返回地址,压入栈
2.让EIP跳转到foo的开始地址
高地址
┌───────────────────────┐
│ main 的参数 │
├───────────────────────┤
│ main 的返回地址 │
├───────────────────────┤
│ 调用 main 的栈帧的EBP │
├───────────────────────┤
│ main 的局部变量 │
├───────────────────────┤
│ → foo 的参数 │
├───────────────────────┤
│ → foo 的返回地址 (ret to main) │ ← ESP
└───────────────────────┘
低地址
进入foo
进入foo后,执行序言,为foo创建帧:
push ebp ; 保存 main 的 EBP
mov ebp, esp ; 建立 foo 的基址
sub esp, 4 ; 为 foo 的局部变量分配空间
EBP:当前栈帧的固定基址
[EBP]:main的旧EBP
[EBP+4]:返回地址(返回 main)
[EBP-4]、[EBP-8]:foo的局部变量
高地址
┌─────────────────────────────┐
│ main 的参数 │
├─────────────────────────────┤
│ main 的返回地址 │
├─────────────────────────────┤
│ 调用 main 的栈帧的EBP │
├─────────────────────────────┤
│ main 的局部变量 │
├─────────────────────────────┤
│ foo 的参数 │
├─────────────────────────────┤
│ foo 的返回地址 (ret to main) │
├─────────────────────────────┤
│ → main 的 EBP │ ← EBP
├─────────────────────────────┤
│ → foo 的局部变量 (4字节) │ ← ESP 指向这里
└─────────────────────────────┘
低地址
之后执行:
mov DWORD PTR [ebp-4], 1
给foo的局部变量空间写入值
foo调用bar
同样的流程
高地址
│ main 的 ... │
├─────────────────────────────┤
│ foo 的参数 │
├─────────────────────────────┤
│ foo 的返回地址 (ret to main) │
├─────────────────────────────┤
│ main 的 EBP │
├─────────────────────────────┤
│ foo 的局部变量 (4字节) │
├─────────────────────────────┤
│ bar 的参数 │
├─────────────────────────────┤
│ bar 的返回地址 (ret to foo) │
├─────────────────────────────┤
│ foo 的 EBP │ ← EBP
├─────────────────────────────┤
│ bar 的局部变量 (4字节) │ ← ESP
└─────────────────────────────┘
低地址
返回过程
首先bar执行MOV ESP, EBP,释放bar栈帧中存放了bar局部变量的地方
高地址
│ main 的 ... │
├─────────────────────────────┤
│ foo 的参数 │
├─────────────────────────────┤
│ foo 的返回地址 (ret to main) │
├─────────────────────────────┤
│ main 的 EBP │
├─────────────────────────────┤
│ foo 的局部变量 (4字节) │
├─────────────────────────────┤
│ bar 的参数 │
├─────────────────────────────┤
│ bar 的返回地址 (ret to foo) │
├─────────────────────────────┤
│ foo 的 EBP │ ← EBP ← ESP
├─────────────────────────────┤
│ bar 的局部变量 (4字节) │ (被释放)
└─────────────────────────────┘
低地址
然后执行POP EBP,将ESP指向的内容(foo的EBP)给EBP,然后释放这部分空间
高地址
│ main 的 ... │
├─────────────────────────────┤
│ foo 的参数 │
├─────────────────────────────┤
│ foo 的返回地址 (ret to main) │
├─────────────────────────────┤
│ main 的 EBP │ ← EBP
├─────────────────────────────┤
│ foo 的局部变量 (4字节) │
├─────────────────────────────┤
│ bar 的参数 │
├─────────────────────────────┤
│ bar 的返回地址 (ret to foo) │ ← ESP
├─────────────────────────────┤
│ foo 的 EBP │ (被释放)
├─────────────────────────────┤
│ bar 的局部变量 (4字节) │ (被释放)
└─────────────────────────────┘
低地址
最后执行RET,弹出返回地址,EIP跳转到foo的返回位置(main函数)
如果有参数则额外RET N释放参数空间
高地址
│ main 的 ... │
├─────────────────────────────┤
│ foo 的参数 │
├─────────────────────────────┤
│ foo 的返回地址 (ret to main) │
├─────────────────────────────┤
│ main 的 EBP │ ← EBP
├─────────────────────────────┤
│ foo 的局部变量 (4字节) │ ← ESP
├─────────────────────────────┤
│ bar 的参数 │(被释放)
├─────────────────────────────┤
│ bar 的返回地址 (ret to foo) │(被释放)
├─────────────────────────────┤
│ foo 的 EBP │ (被释放)
├─────────────────────────────┤
│ bar 的局部变量 (4字节) │ (被释放)
└─────────────────────────────┘
低地址
这样一来,bar的整个栈帧被销毁,ESP和EBP还原至foo栈帧
foo返回也是一样
下图关于参数划分的栈帧位置有些不同,不过也能辅助理解嵌套调用: