比较简短,结合逆向基础1 看吧,之后的内容比较复杂就单独开篇了~
从源代码到可执行文件
编程语言的层次
计算机硬件的世界建立在二进制之上,电子器件的开与关直接对应着0和1
要驱动这些硬件,就需要一种它们能直接“听懂”的语言,这便是编程语言演进的起点
机器语言
这是最底层的语言
它由0和1组成的二进制序列构成,即机器码或原生码,CPU可以不经任何翻译直接解读并执行
早期的计算机程序,例如1951年“哈维尔·德卡特伦”计算机所使用的穿孔纸带,记录的就是这种机器码
然而,它完全没有可移植性,且对人类来说极其晦涩难懂,毕竟谁会去背那么多不同的一长串的0和1?
汇编语言
为了改善机器语言的可读性,汇编语言应运而生,它使用助记符来代替二进制指令,因此也被称为符号语言
汇编语言与机器语言几乎是一一对应的关系,在执行前需要通过汇编器转换为目标平台的机器码
但尽管它的可读性大幅提升了,却依然与特定的CPU指令集架构绑定,可移植性很差
高级语言
高级语言是编程领域的伟大又伟大的革命
它高度抽象和封装了底层硬件细节,语法结构更接近自然语言,逻辑也更贴合人类的思维习惯
这使得程序员可以从繁琐的内存地址和寄存器操作中解放出来,专注于业务逻辑的实现,从而极大地提高了开发效率和代码的可读性
如今我们熟知的 Java, C, C++, Python, C# 等等,都属于高级语言
编译与解释
拥有了编程语言这一工具后,我们需要一个工作台来编写、调试和生成程序
这个工作台就是IDE(Integrated Development Environment,集成开发环境)
通过IDE,我们可以将源代码转化为可执行的程序,根据生成和运行方式的不同,程序主要分为两类
编译型程序
在执行前,通过编译器将全部源代码一次性翻译成目标平台的机器码,并打包成一个可执行文件
运行效率非常高,跨平台性差,比如为Windows编译的程序无法直接在Linux上运行
C、C++、Go都是如此
解释型程序
运行时,由解释器逐行读取源代码,并即时翻译成机器码交给CPU执行
跨平台性好,只要有解释器,代码就能运行,但是运行效率相对较低
常用的有Python, JavaScript, Ruby
混合型范例
Java!
所谓“一次编译,到处运行”的Java采用了一种巧妙的混合模式,源代码首先被编译成一种平台无关的中间代码——字节码(.class文件),然后,在不同平台上的**Java虚拟机(JVM)**会解释执行这些字节码
为了提升性能,JVM还引入了JIT(Just-In-Time Compilation,即时编译)技术,它会将频繁执行的“热点代码”编译为本地机器码,从而实现接近编译型语言的运行效率,真是很有创新了
C程序的构建
作为编译型语言的典范,C/C++程序的生成过程是理解可执行文件结构的基础
这个过程的最终产物,便是一个可执行文件,它主要经历编译和链接两大阶段
编译
此阶段由编译器负责,将源代码文件(.c)转换为包含机器码的目标文件(.o)
下面以一个简单的hello.c程序为例
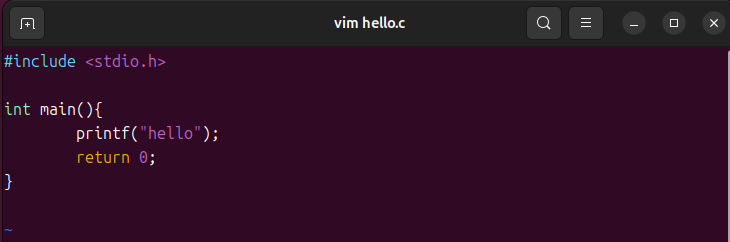
源码(hello.c)
#include <stdio.h>
int main() {
printf("hello");
return 0;
}
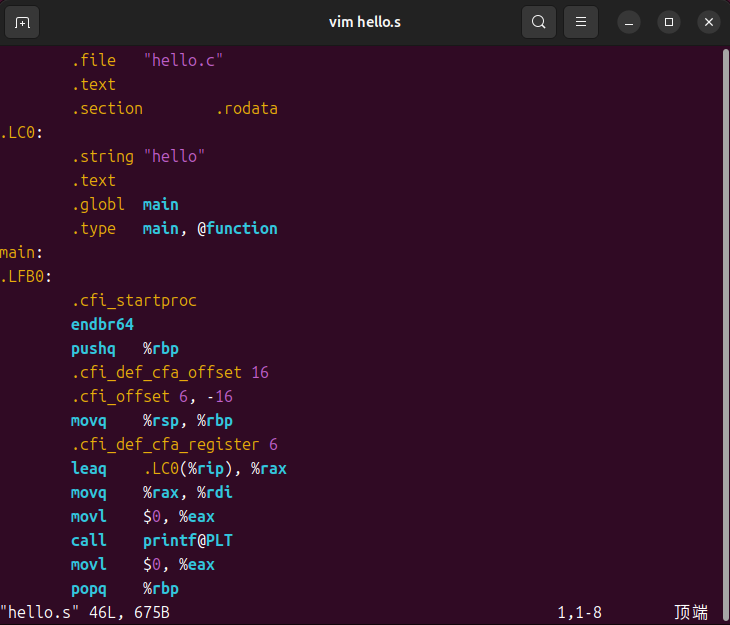
预处理、编译为汇编 (hello.s)
编译器首先进行预处理(比如包含头文件),然后将C代码翻译成汇编代码
# -S 选项: 仅编译,不进行后续的汇编和链接
gcc -S -o hello.s hello.c
汇编为目标文件(hello.o)
汇编器将汇编代码转换为二进制的目标文件
这个文件包含了机器码,但还不能独立运行,因为它可能引用了其他外部函数(比如printf就是外部函数)
# -c 选项: 编译并汇编,但不链接
gcc -c -o hello.o hello.s
看不懂呢……因为这是二进制,没办法完全转成正常的unicode,使用od查看原始的数据:
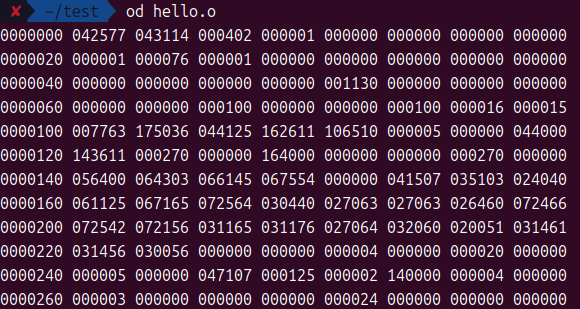
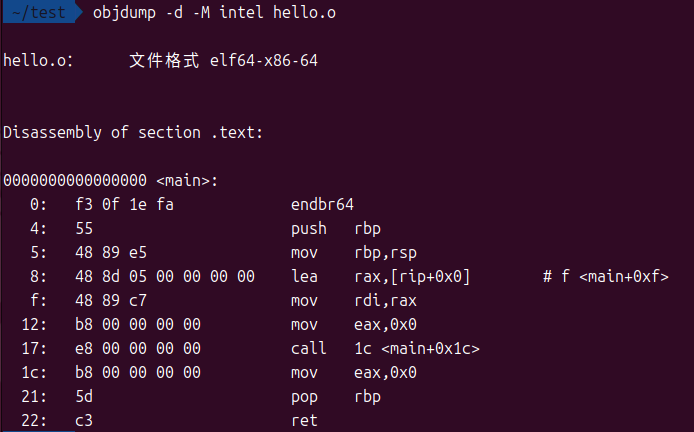
还是看不懂哈哈,其实还可以使用objdump命令查看,本质就是.s文件翻译的机器码而已
用-d选项反汇编所有可执行节,-M intel指定使用intel汇编语法(概念看不懂没关系,后面都会有的):
链接
链接器的任务是将一个或多个目标文件以及它们所需的系统库“链接”在一起,生成最终的可执行文件
其核心工作是符号解析和重定位(下文会说这是啥)
链接分为两种主要方式:
动态链接
现在最为常用的链接方式
只在可执行文件中记录所需库的引用信息,程序运行时,由操作系统加载共享的库文件
节约资源、易于更新,但是依赖外部环境
# 默认进行动态链接,生成可执行文件 hello
gcc -o hello hello.o
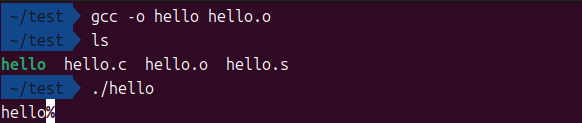
静态链接
将所有依赖的库代码完整地复制并合并到最终的可执行文件中
可独立运行,但体积大且更新困难
# 使用 -static 选项进行静态链接
gcc -static -o hello_static hello.o
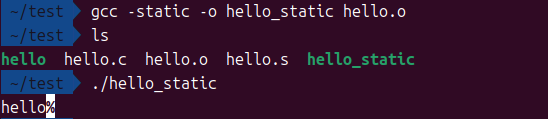
对比一下就能看出它有多大:
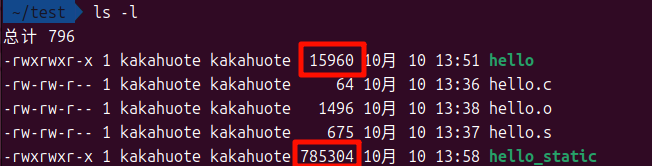
动态链接的只要一万多字节,而静态的要八十万字节!林冲
我们在之后会详细说明这两种链接方式的实现
可执行文件
何为可执行文件?
在上文,编译后链接生成的这个文件,就是一个可执行文件
顾名思义,他是能直接被用户执行的文件,这个名称也是一类文件的规范,它定义了链接器和加载器如何处理和执行二进制代码,规定了代码、数据、元信息等内容如何组织在一个文件中
目前,主流操作系统主要使用两种格式:
- Unix/Linux 系统: ELF (Executable and Linkable Format,可执行和可链接格式)
- Windows 系统:PE (Portable Executable,便携可执行文件)
之后我们会详细讲它们俩,不过不是这一篇
可执行文件的元信息
可执行文件不是纯粹的机器码集合,编译器在生成目标文件时,可以选择性地嵌入丰富的元信息
这些信息对于链接、调试和程序分析至关重要。元信息的存在与否,直接决定了逆向分析和调试的难易程度
主要的元信息包括以下三类:
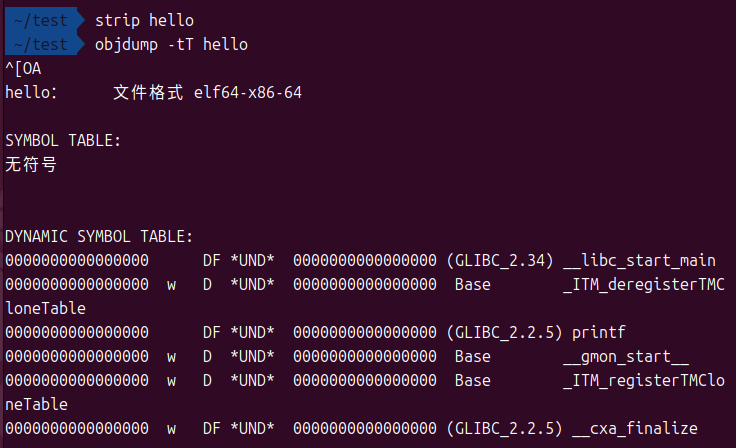
符号表
符号表记录了源代码中的符号信息,例如函数名、全局变量名等
表中每一个表项都包括:
-
符号名
-
绑定地址
-
符号类型
-
其他信息
链接器(用于解析不同文件间的符号引用)和调试器(用于将地址映射回人类可读的名称)都会使用它
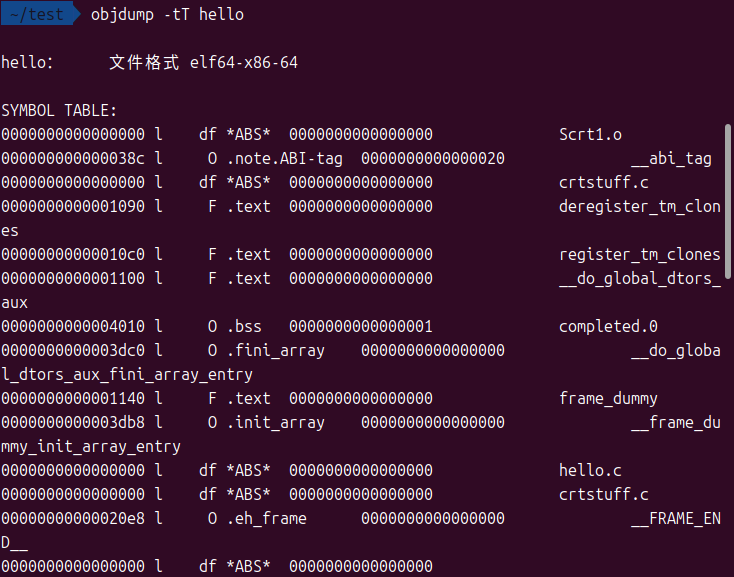
使用objdump查看符号表(-t)和动态符号表(-T):
objdump -tT hello
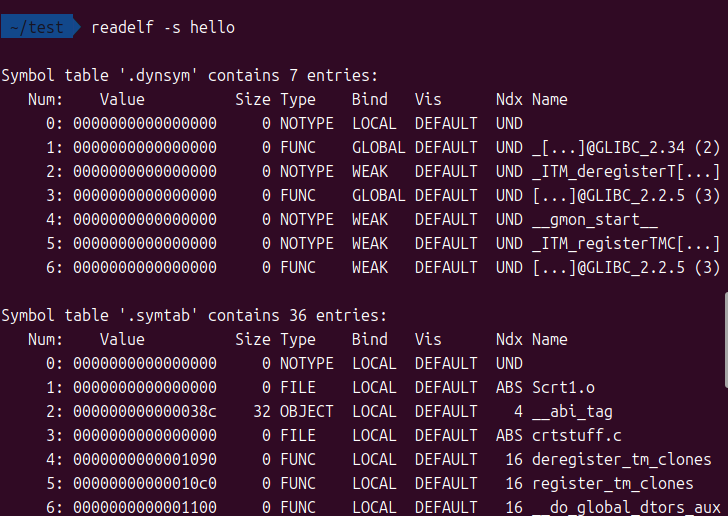
使用readelf查看符号信息:
readelf -s hello
重定位信息
在编译单个文件时,编译器并不知道函数和全局数据最终会被加载到内存的哪个确切地址,因此,它会在代码中留下标记,并生成一系列的重定位入口
当链接器将所有目标文件组合时,它会根据这些入口信息,用最终的绝对地址或相对地址来“修补”这些代码,确保程序能够正确跳转和访问数据
调试信息
为了方便调试,编译器可以生成详细的调试信息,并将其嵌入到可执行文件中
调试信息包含源代码文件名、行号信息、变量的类型与作用域等,这将二进制代码与原始的源代码关联起来
调试器可以利用这些信息,让我们可以在源代码级别设置断点、查看变量值,极大地提高了调试效率
精简与非精简二进制
根据是否包含上述元信息,可执行文件可分为两类:
-
非精简二进制(Unstripped)
包含完整的元信息,体积较大,但易于调试和反汇编
-
精简二进制(Stripped)
只保留运行必需的纯代码,几乎所有元信息都被移除
进行精简可以显著减小文件体积,并且由于缺少符号信息,大大增加了逆向工程的难度
在Linux系统中,可以使用strip命令来完成这个精简过程:
strip hello