
终于讲到了,久闻ELF大名,真的很有意思
在几乎所有的现代Unix-like操作系统(比如Linux)中,从可执行程序、共享库到目标文件,背后都有一个共同的标准——那就是ELF (Executable and Linkable Format,可执行和可链接格式)
ELF格式的文件也常简称对象文件,对象文件参与程序的链接和执行
参考文章:
三种形态
根据在程序生命周期中所处的阶段,ELF文件主要表现为三种形式:
可重定位文件(.o)
由编译器和汇编器生成,包含了代码和数据
它可以与其他目标文件链接,以创建可执行文件或共享库
# 从 test.c 生成可重定位文件 test.o
gcc -c test.c -o test.o
可执行文件
包含了执行一个程序所需的全部信息,它指定了如何创建一个进程映像
# 从 test.o 链接生成可执行文件 test
gcc test.o -o test
共享对象文件 (.so)
这就是我们常说的动态链接库,它有两个用法:
-
链接器能将它与其他
.o和.so文件链接,生成新的对象文件 -
动态链接器在程序运行时能将多个它与可执行文件结合,共同创建进程映像
# 生成位置无关代码的目标文件
gcc -c -fPIC shared.c -o shared.o
# 链接生成共享库
gcc -shared -o libshared.so shared.o
链接与执行
ELF格式的一个核心设计思想是为同一个文件提供两种不同的解析视图,以满足不同工具的需求
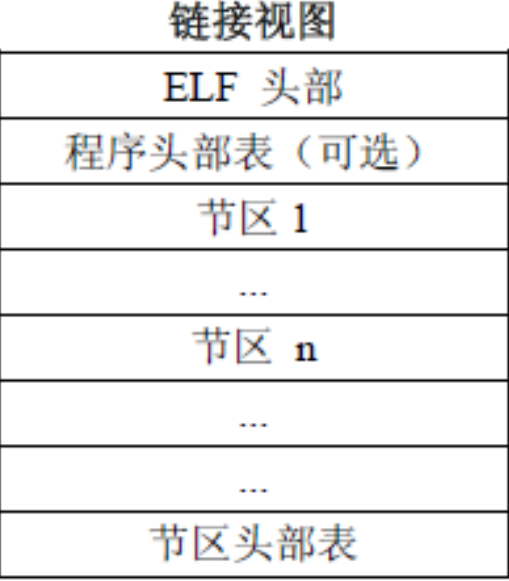
链接视图
供链接器使用
文件被看作是一系列**节(Section)**的集合,链接器通过解析节头表来处理和合并这些节
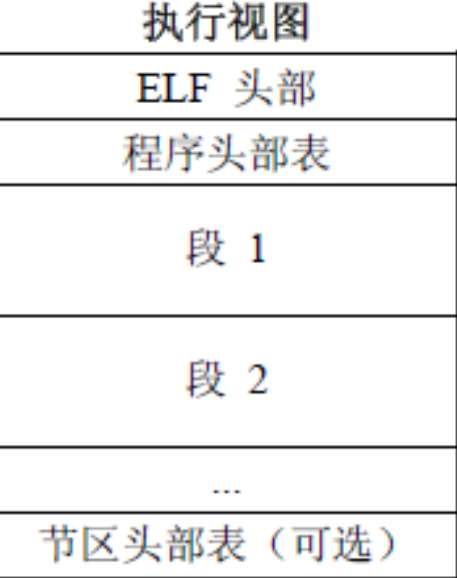
执行视图
供加载器(操作系统内核的一部分)使用
文件被看作是一系列**段(Segment)**的集合,加载器通过解析程序头表来将段加载到内存并创建进程
下面我们会分别解释它们是什么
ELF文件核心结构
ELF头
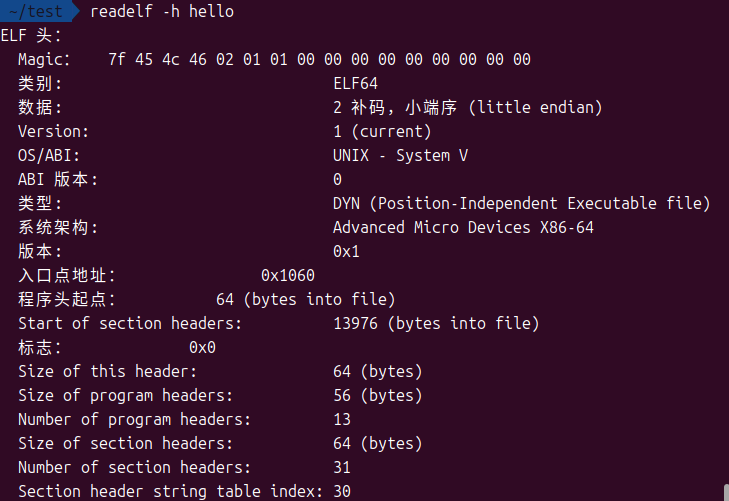
位于文件的最开始(即偏移量是0),是整个文件的索引名片,包含了最基本的信息:
-
文件魔数,用于识别ELF格式
-
文件位数,32位还是64位
-
数据编码存储方式,大端序还是小端序
-
指令集体系结构,如 x86-64、ARM
-
程序执行的入口点地址
-
程序头表和节头表在文件中的偏移量、条目数量和大小
还由其他的一些信息
可以使用readelf命令查看ELF头:
readelf -h <filename>
节头表与重要节区
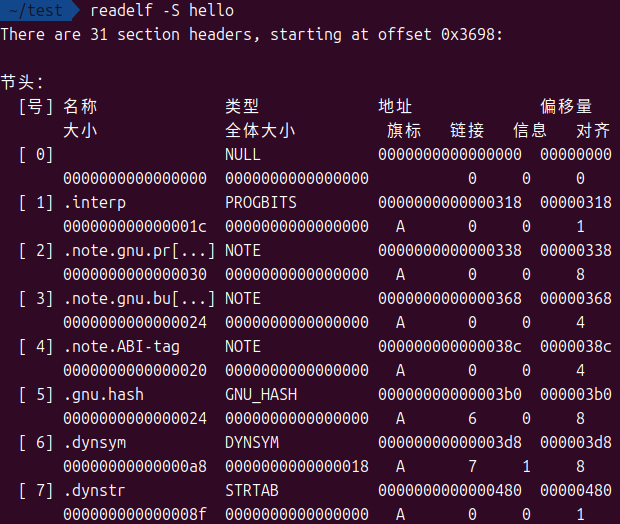
这是链接视图的核心
它是一个数组,描述了文件中所有的节,每个节都是一块具有相似属性的数据或代码的集合
一些重要的节:
| 节名称 | 含义 |
|---|---|
.text |
程序的可执行指令(代码) |
.data |
已初始化的全局变量和静态变量 |
.bss |
未初始化的全局变量和静态变量(在文件中不占空间,加载时才分配) |
.rodata |
只读数据,如字符串常量 |
.interp |
存放动态链接器的路径名 |
.plt |
过程链接表,用于动态链接中的函数调用跳转 |
.got |
全局偏移量表,存储动态链接符号的地址 |
.rel.<x> |
节<x>的重定位信息,比如.rel.text就是.text节的重定位信息 |
.dynamic |
动态链接所需的信息 |
可以使用readelf查看详细的节头表信息:
readelf -S <filename>
程序头表与段
这是执行视图的核心
在加载器眼中,文件被划分为若干个段,而它告诉系统如何将文件内容加载到内存中以创建一个进程
重要的段类型:
| 段类型 | 含义 |
|---|---|
LOAD |
可加载段,加载器需要将此类型的段从文件映射到内存 通常,一个 LOAD段对应代码(可读可执行),另一个对应数据(可读可写) |
INTERP |
指向动态链接器的路径(对应.interp节) |
DYNAMIC |
指向动态链接信息(对应.dynamic节) |
PHDR |
描述程序头表本身的位置和大小 |
可以使用readelf -l <filename>查看程序头表:
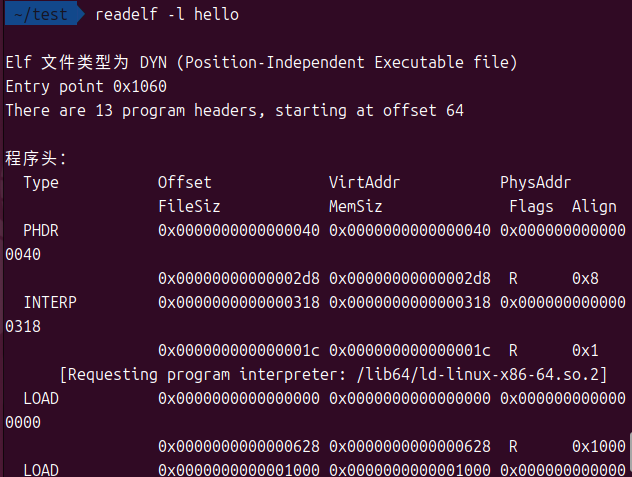
节与段到底是什么啊
这俩东西的确有些难以理解,我们展开说一下
节
节是ELF文件中基本的逻辑单位,用来分类不同类型的数据,编译器在生成目标文件(.o)时,会把不同性质的内容放到不同的节里
还是拿之前打印输出hello的那个c语言程序举例:
#include <stdio.h>
int main() {
printf("hello");
return 0;
}
我们把它编译链接生成可执行文件后,这个可执行文件内部就有了许多的节
比如.text存放的是函数的机器指令,也就是main()函数的汇编代码,而.rodata存放只读常量,比如字符串 "hello",也就是给文件里面的东西分类摆放了
当多个.o文件被合并时,链接器会把同名的节拼在一起,比如把所有.text合并成一个大.text
注意,这些节只对编译器和链接器有意义,别的东西来看是没有什么用的
段
当链接器把.o文件合并成最终的可执行文件后,它还要告诉操作系统运行这个程序时要加载哪些部分,这时它就会生成一组段信息
段描述的是内存映射的区域,比如哪一部分是可执行的(代码段),哪一部分又是可读写的(数据段)等等,一个段往往包含多个节
在上面代码编译生成最终的可执行文件会有两个主要的加载段:
第一个是可执行段,包含.text和.rodata,程序加载时,这部分会映射成只读、可执行的内存区域
第二个是可读写段,包含.data和.bss,程序加载时,这部分会映射成可读可写的区域,用于存储全局变量
除了这两个段还会有一些特殊段,就不多说了
我们上面说的都是“程序加载时”,也就是说段是给加载器看的,在加载的时候才起作用
如此羁绊
总之啊可以这样理解:
-
节是编译器和链接器关心的划分,它描述文件中的逻辑内容
段是操作系统加载器关心的划分,它描述程序加载到内存后的布局
-
节是编译时的单位
段是运行时的单位
-
节存在于文件逻辑结构中
段存在于文件加载映射中
在链接阶段完成之后,节和段完全就是两个东西,不会互相干扰
使用readelf -l看文件的时候,其实还会有下面这样的输出:
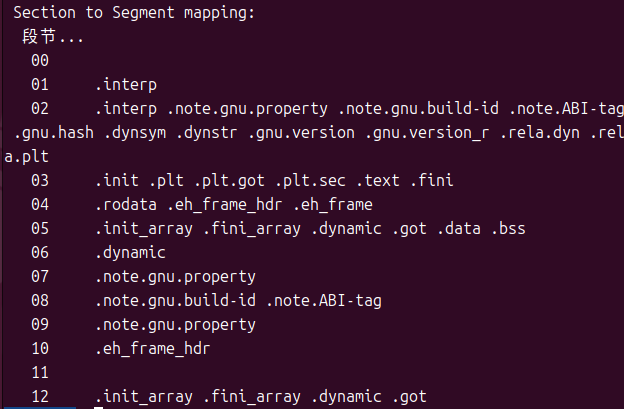
左边就是段表各个段的索引号,右边就是对应段里面存储了那些节
记得之前的strip命令吗,当执行strip时,程序会删除节头表,于是里面的信息,也就是元数据,都没有了
那为什么删除它不会影响执行呢?现在我们就应该知道了——
**因为操作系统加载程序时只看段信息!**节没了就没了呗
程序的链接与装载
ok,我们已经了解了ELF文件的内部结构,但一个静态的文件是怎么变成一个在内存中运行的进程的呢?
这个过程的核心就是链接和装载
而链接则负责解决不同代码模块之间的依赖关系,而装载负责将文件内容搬入内存
代码的两种形态
在介绍链接细节之前,我们先看看代码生成的两种不同模式,它们直接决定了文件应如何被加载
注意,下面的概念都是基于虚拟地址的
绝对代码(Absolute Code)
这是在编译时就假定自己会被加载到内存中一个固定地址的代码
这个预设的地址被记录在程序头表的p_vaddr字段中,操作系统加载器必须将代码段存放到这个指定的虚拟地址,否则程序内部的地址引用就会全部出错
对于一个进程的主程序来说,这是可行的,因为它是第一个被加载的,其首选地址通常是空闲的
位置无关代码(PIC, Position-Independent Code)
这是为共享库(.so文件)量身定做的代码喔,在之前介绍.so文件的时候已经提到过,使用GCC编译时加上-fPIC选项即可生成
共享库会被许多不同的进程加载和共享,我们无法为一个库预设一个固定的加载地址,因为这个地址在A进程中可能是空闲的,但在B进程中可能已经被主程序或其他库占用了
PIC通过生成不依赖于任何绝对地址的代码,完美地解决了这个问题
当加载一个PIC库时,系统会为它在当前进程中选择一个空闲的虚拟基地址,这意味着同一个.so文件,在不同的进程中其段的起始虚拟地址是不同的
PIC代码之所以能正常工作,关键在于它内部所有的地址引用(如调用库内另一个函数、访问全局变量)都不是硬编码的绝对地址,而是通过相对寻址的方式实现的
系统为PIC代码维护了段间的相对位置,无论库被加载到多高的基地址,其代码段和数据段之间的虚拟地址差值始终保持不变,这个差值与它们在原始.so文件中的虚拟地址差值是相等的
叽里呱啦说那么多,总之位置无关代码很灵活,在不同进程的虚拟地址空间里位置可变,但内部各段之间的相对位置保持不变
静态链接
静态链接发生在程序编译的最后阶段,它是一个将分散的模块组合成一个完整、独立的可执行文件的过程
链接器读取开发者编写的多个可重定位文件(.o文件)和可能用到的静态库(.a文件),将它们的所有内容“打包”到一个单独的可执行文件中
链接的核心操作之一是将所有输入文件中的同类型节合并,在之前介绍节的时候提到过的:
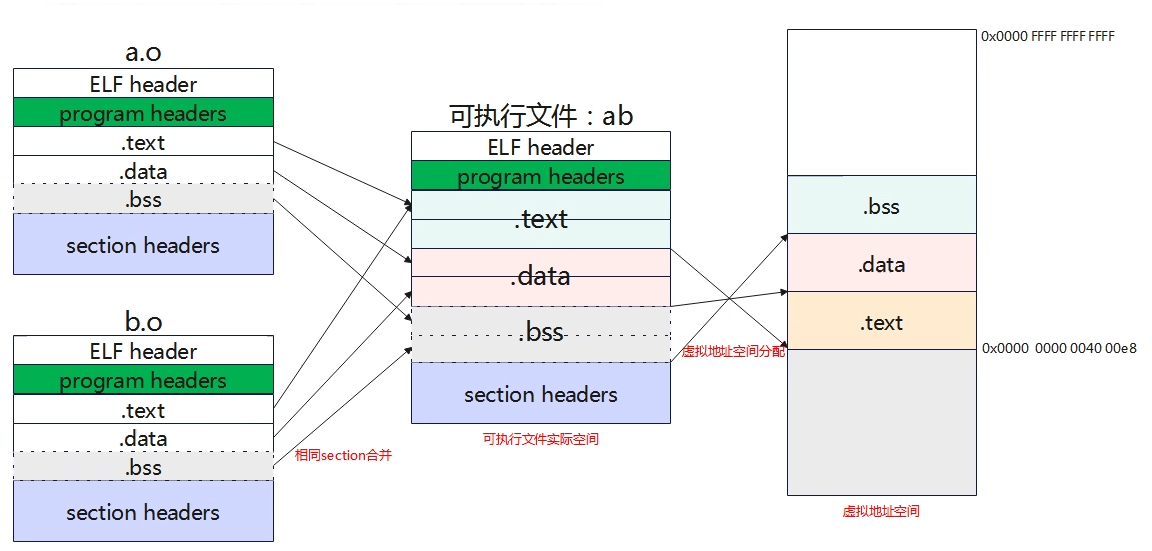
而在合并的过程中,链接器最关键的工作就是进行重定位
它负责解析各个模块间的符号引用(比如函数调用),并修正代码和数据中的地址,确保它们指向正确的位置
重定位
重定位的作用
重定位本质上是一种对二进制文件进行打补丁的机制,它将代码中对符号的引用连接到该符号的定义上,解决地址未知问题
还是拿之前的hello.c程序举例吧,我们调用了printf函数,但是程序不知道这个函数在哪,所以编译器只能在机器码里留下一个临时的占位符,再用一个重定位入口来告诉链接器“这里有个地址需要你填一下”
或许你还记得之前使用objdump查看汇编后的文件的那张图片:
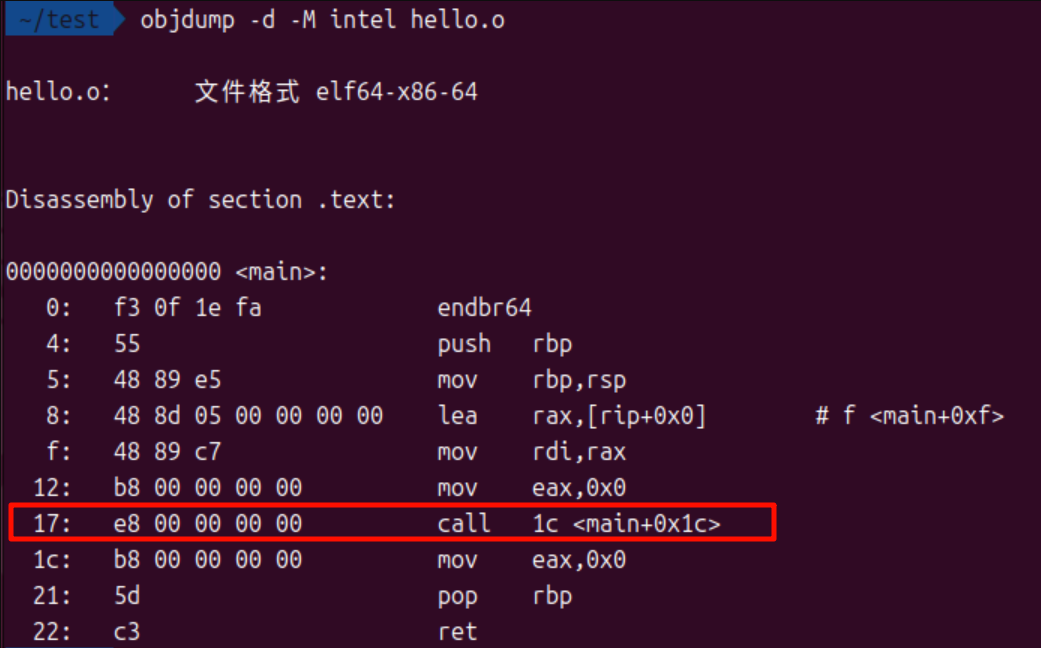
里面call(调用函数)这一行怎么理解呢?
右边是汇编,我们不管,只看左边:
17: e8 00 00 00 00
冒号前面的17意思是当前指令地址为0x17
冒号后面的e8 00 00 00 00五个字节是指令,其中第一个字节e8是对应call的操作码,后面四个字节是偏移量,都是“00”,这就是“编译器在机器码里留下的临时占位符”!
之前我们没有看链接后的可执行文件结构,现在我们来看看,还是使用objdump命令:
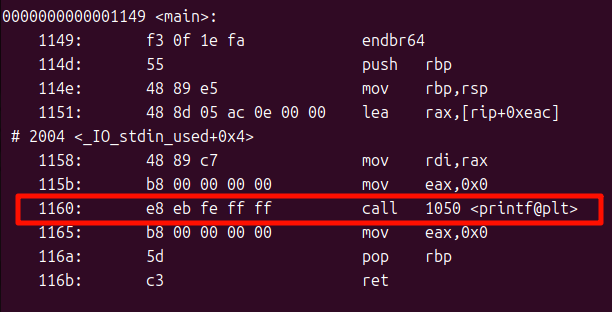
哦!链接之后,这里的偏移量被换成了确定的数据了!
这就是重定位的作用
重定位入口
链接器之所以知道要去哪里打补丁,是因为它读取了文件中的重定位节,也就是.rel.<X>
每个入口都用以下字段描述了一个重定位操作:
| 字段 | 说明 |
|---|---|
| OFFSET | 需要修正的位置在节内的偏移量,以字节为单位 |
| TYPE | 重定位类型,决定怎么计算地址 |
| VALUE | 目标符号,也就是被引用的对象的名称 |
使用objdump能查看重定位表:
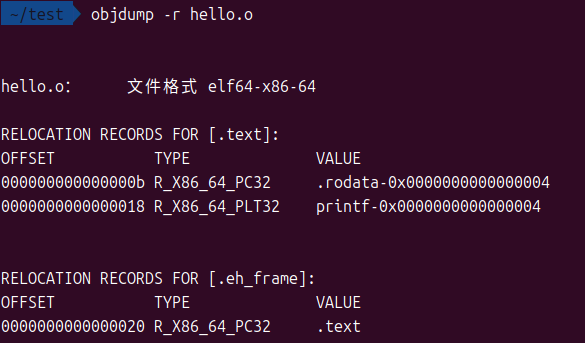
里面的第二条记录:
0000000000000018 R_X86_64_PLT32 printf-0x4
说明在.text段偏移0x18处有一个通过PLT(过程链接表)调用的printf的指令
重定位地址计算
链接器根据重定位类型使用特定公式来计算最终要填入的值
上文的记录的类型是R_X86_64_PLT32,用在x86-64架构,即64位架构
我们这里介绍一个类似的用在32位的R_386_PC32类型,其公式为:
目标值 = S + A - P
- S:是符号的最终值,即被调用函数在内存中的绝对地址
- A:是存储在要修改位置的原始值,称为隐式加数
- P:是要修改位置本身的地址
动态链接
动态链接将链接过程的一部分推迟到程序运行时进行。当程序依赖于共享库(如libc.so)时,操作系统会在程序启动时找到这些库,并将它们动态地绑定到进程上。这种方式极大地减少了可执行文件的体积和系统内存的占用。
启动过程
系统装载可执行文件本身后,如果在解析程序头表时发现有一个INTERP段,它就知道这个程序需要动态链接
此时会加载并启动INTERP段中指定的动态链接器(在Linux上通常是/lib/ld-linux.so.2),并将控制权移交给动态链接器
动态连接器会分析可执行文件需要依赖哪些共享库,然后查找、加载这些库,并将它们也映射到进程的内存空间中
延迟绑定
为了加快程序的启动速度,动态链接器默认采用延迟绑定策略:一个外部库函数的地址只有在它第一次被调用时才会被解析
这个机制由过程链接表 (PLT) 和 全局偏移量表 (GOT) 协同完成
过程链接表 (PLT)
给外部函数提供一个统一的跳板入口,负责第一次调用的动态解析
它在运行之前就已经确定并且不会被修改
全局偏移量表 (GOT)
保存外部函数或全局变量的真实地址,程序通过它来间接访问外部符号
它可以在程序运行中被修改(这就导致它很容易作为漏洞利用)
关于PLT和GOT的详细的结构,主要是pwn的内容,我们学逆向就点到为止
绑定过程
下面我们用printf为例看看什么叫延迟绑定:
- 首次调用函数:
- 代码中的
call指令实际上跳转到printf在PLT中的一个专属条目,我们称之为printf@plt printf@plt的第一条指令是跳转到GOT中为printf函数预留的地址槽printf_in_got- GOT槽里存放的并不是
printf的真实地址,而是printf@plt中下一条指令的地址!所以这个jmp实际上又跳了回来 - 程序继续执行PLT条目中的后续指令,它会将
printf函数的一个标识信息压栈,然后跳转到动态链接器中一个公共的解析函数 - 解析函数根据传入的标识信息,查找
printf函数的真实地址,然后用这个真实地址覆盖GOT中printf_in_got原来的值 - 最后,解析函数直接跳转到
printf的真实地址去执行
- 代码中的
- 再次调用函数:
- 代码再次执行
call printf@plt - PLT条目再次执行
jmp *[printf_in_got] - 但这一次,
printf_in_got这个槽里已经存放了printf函数的真实地址!所以,程序会直接跳转到printf函数,完全不再需要动态链接器介入,从而实现了高效调用
- 代码再次执行
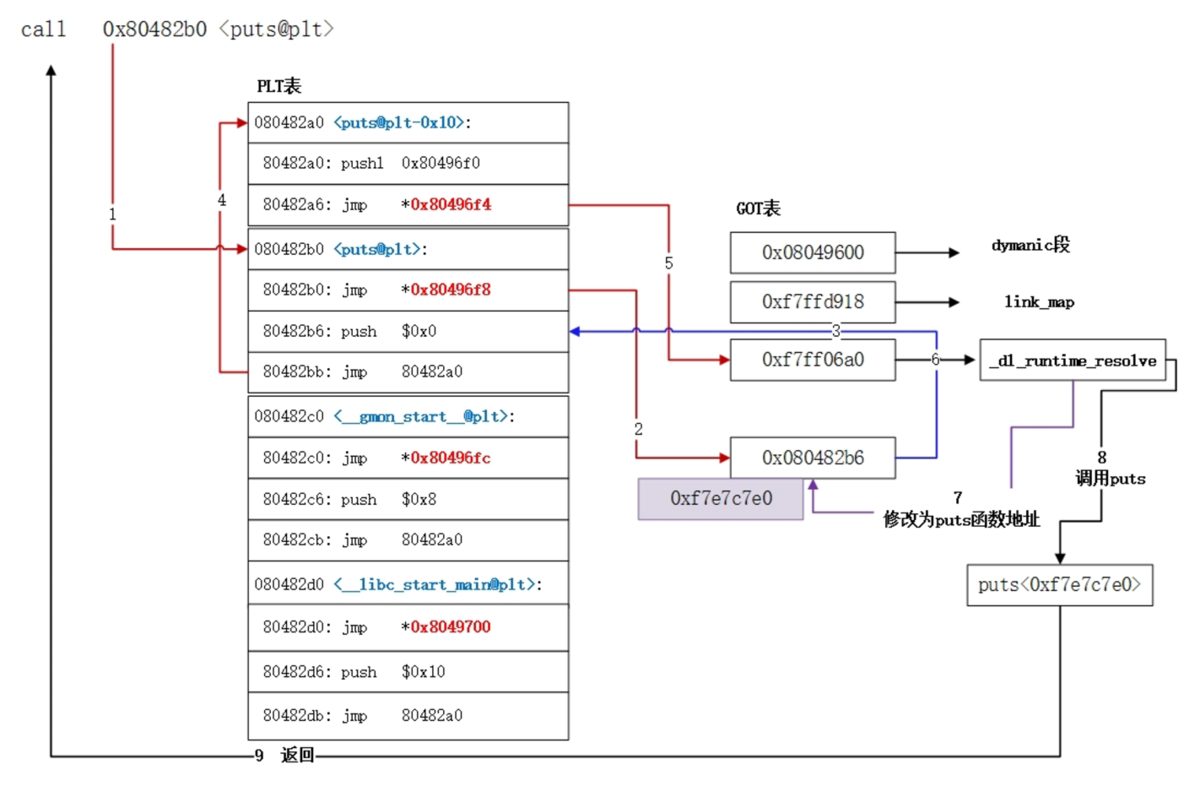
总之,plt就像指示牌,指向got,而got里面存了真正的地址,第一次使用plt会更新got值,后面就随便用了
程序的装载
将一个静态的ELF可执行文件转换为一个动态运行的进程映像,操作系统的加载器有着严谨的步骤
Shell调用
当用户在shell输入./hello时,shell的执行流程如下:
- 调用
fork()创建一个子进程 - 子进程调用
execve("./a.out", argv, envp)执行指定的ELF文件 - 父进程(shell)继续挂起,等待子进程结束后继续接收用户输入
也就是说,此时shell本身并不直接执行ELF文件,而是通过execve()请求内核将子进程的地址空间替换为ELF可执行文件
execve()的原型:
int execve(const char *filename, char *const argv[], char *const envp[]);
参数分别为:程序文件名、命令行参数、环境变量
execve系统调用
系统调用入口为:
int sys_execve(const char *filename, char *const argv[], char *const envp[]);
在内核中,sys_execve()会调用do_execve(),把用户传入的文件名、argv、envp(环境变量数组)封装为内核可以使用的格式,然后进入do_execve_common(),处理实际加载过程:
-
检查进程限制
例如每用户进程数是否超过限制
-
调度准备
sched_exec()选择负载最小的CPU -
准备执行参数结构
创建结构体
struct linux_binprm bprm:struct linux_binfmt bprm{ struct list_head lh; // 单链表表头 struct module *module; // 模块 int (*load_binary)(struct linux_binprm *); // 装载函数 };保存文件指针、命令行参数和环境变量、文件开头的缓冲区(前128字节)
-
拷贝参数与环境变量到内核
调用
copy_strings()将argv和envp拷贝到内核空间 -
调用
exec_binprm()搜索可执行文件格式,并调用对应加载函数
格式识别
exec_binprm()会调用search_binary_handler(),遍历由bprm组成的链表,调用对应格式的load_binary()
接着,对于可能的ELF文件,调用load_elf_binary(),并执行以下操作:
-
读取ELF头
读取文件开头128字节,检查魔数
{0x7f, 'E', 'L', 'F'},验证ELF类型(ET_EXEC或ET_DYN)你可能奇怪为什么已经知道是ELF了,还要再识别一次,那是因为之前只是初步匹配,这一步才是严格检查
-
读取程序头表
获取段的数量、偏移位置等信息,确定每个段在文件中的偏移、大小、内存加载地址和权限。
-
检查动态链接器
如果存在
.interp段,说明ELF需要动态链接,内核会打开动态链接器ELF文件,并递归调用load_elf_binary()
规划内存布局
在读取程序头表的时候,加载器会特别关注所有类型为LOAD的段,因为这些段是需要被完整加载到内存中的
程序头表中的每个LOAD条目都精确地指明了下面的内容:
- 该段在文件中的偏移量和大小(
p_offset,p_filesz) - 该段应该被加载到的目标虚拟内存地址(
p_vaddr) - 该段在内存中应该占据的空间大小(
p_memsz) - 该段的内存访问权限
之后,跟据这些信息确定内存布局:
.text、.rodata→ 可执行、只读段.data、.bss→ 可写段
准备工作
调用flush_old_exec(bprm)释放旧程序的代码段、数据段、栈等资源
使用setup_new_exec(bprm)初始化mm_struct(进程地址空间描述符)、地址空间
通过setup_arg_pages(),为进程分配用户态栈,将argv、envp写入栈顶
映射段到内存
根据规划好的内存布局,加载器开始为每一个LOAD段执行内存映射操作:
首先,在进程的虚拟地址空间中,于p_vaddr处开辟一块内存区域,大小为p_memsz
接着,将段的数据从ELF文件中(从p_offset偏移量开始)复制到刚刚开辟的虚拟内存中,复制的数据量为p_filesz
值得注意的是,p_memsz(内存大小)常常会大于p_filesz(文件大小)
这种差异通常是为了方便.bss节,这里存放的是未初始化的全局和静态变量,它们在程序运行前没有具体值,因此在文件中无需存储,不占用磁盘空间
加载器会在内存中将p_memsz与p_filesz之间的差额部分全部用0填充,从而完成这些变量的默认初始化
最后,加载器根据程序头表中为该段指定的权限位,设置这块内存区域的访问权限
设置入口点
对于静态链接程序,直接使用ELF头中的e_entry作为入口
对于动态链接程序,入口点由动态链接器提供
返回用户态
调用start_thread()初始化用户态寄存器,设置EIP为程序入口,设置ESP为栈顶,设置CPU标志位
启动程序执行
控制权交给ELF程序,程序从入口点_start或动态链接器入口开始运行