同样是很重要的文件格式,本篇设计到一些简单逻辑计算,也是挺有意思的
参考文章:
PE文件的类别
PE文件格式是Windows操作系统下使用的标准可执行文件格式,按照系统划分一般有两个称呼:
- PE32:指32位的可执行文件,也有人直接用PE代指
- PE32+:64位系统下的可执行文件,是PE32格式的一个扩展,也被叫做PE+
PE格式涵盖了多种文件类型,它们通过不同的扩展名来区分:
| 种类 | 主扩展名 |
|---|---|
| 可执行系列 | .exe,.scr |
| 库系列 | .dll,.ocx,.cpl,.drv |
| 驱动程序系列 | .sys,.vxd |
| 对象文件系列 | .obj |
其中,除了用于链接过程的对象文件(.obj)之外,其他类型的文件都能够被系统加载并执行
PE32文件的基本结构

DOS头
PE结构的最前端是DOS头,这是一个历史遗留的结构,主要为了兼容古老的MS-DOS系统
typedef struct _IMAGE_DOS_HEADER {
WORD e_magic; // 魔数,必须是 0x5A4D,即“MZ”
WORD e_cblp;
WORD e_cp;
WORD e_crlc;
WORD e_cparhdr;
WORD e_minalloc;
WORD e_maxalloc;
WORD e_ss;
WORD e_sp;
WORD e_csum;
WORD e_ip;
WORD e_cs;
WORD e_lfarlc;
WORD e_ovno;
WORD e_res[4];
WORD e_oemid;
WORD e_oeminfo;
WORD e_res2[10];
LONG e_lfanew; // 指向 PE 头的偏移
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
还是使用一个hello.c生成的exe文件:
#include <stdio.h>
int main() {
printf("Hello, World!");
return 0;
}
这里用010editor查看exe文件的二进制,它有模版功能,能很好的展示PE文件的结构:
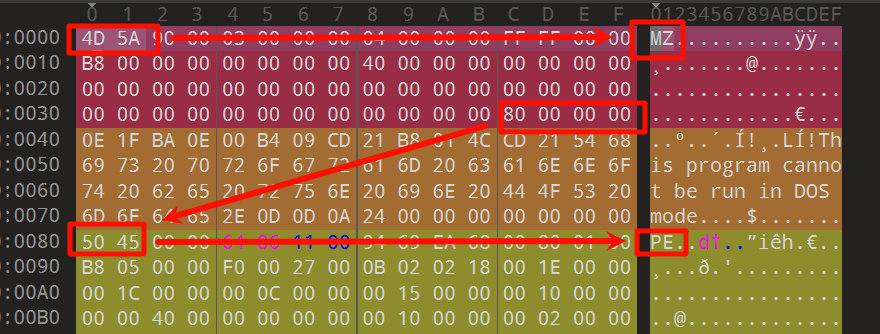
PE的起始两个字节是固定的签名“MZ”(0x4D5A),是识别一个PE文件的最初步标志
DOS头最重要的作用是其末尾的四字节的e_lfanew字段,该字段保存了指向NT头的偏移量,也就是PE程序的真正入口
DOS存根
紧随DOS头之后的是一段可选的DOS存根(DOS Stub)小程序

这个东西的由来比较好玩,也稍微讲讲
在上世纪80~90年代初期,个人电脑主要运行MS-DOS系统,那时候的可执行文件格式是MZ格式,由微软工程师Mark Zbikowski设计(他名字的首字母就是MZ)
后来到了Windows3.x,微软引入了PE格式,但那时的很多电脑还经常在DOS模式下启动,用户如果直接在DOS命令行中里运行一个PE格式的程序就会出现问题:DOS根本不认识PE格式!
微软不希望让DOS报错或者死机,于是做了这样的设计:在新格式的开头保留了一个旧的MZ头和一小段能在DOS下执行的程序,这就是DOS存根
如果在纯DOS环境下尝试运行一个现代的Windows程序,这段存根代码会被执行,它通常只会在屏幕上打印一句提示信息“This program cannot be run in DOS mode”,然后正常退出
而在windows环境下,当windows识别到这是一个PE文件,就会直接跳转到文件偏移e_lfanew处,DOS存根会被完全忽略掉所以可以随便改这一段也不会出错
这样既保证了兼容性,也避免了错误,还是挺不错的
NT头
NT头是PE格式的核心头部,包含了关于文件的大量关键信息,它由一个签名和两个重要的子结构组成
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature; // 签名 "PE\0\0" (0x00004550),四字节
IMAGE_FILE_HEADER FileHeader; // 文件头,20字节
IMAGE_OPTIONAL_HEADER32 OptionalHeader; // 可选头(对于32位),32位下224字节, 64位下240字节
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
加载器通过签名确认文件是有效的PE文件
文件头
typedef struct _IMAGE_FILE_HEADER {
WORD Machine; // 运行平台(如 x86 = 0x14C,x64 = 0x8664)
WORD NumberOfSections; // 节区数量
DWORD TimeDateStamp; // 时间戳(文件编译时间)
DWORD PointerToSymbolTable; // 调试符号表指针(现代 PE 通常为 0)
DWORD NumberOfSymbols; // 符号数量(通常为 0)
WORD SizeOfOptionalHeader; // 可选头大小
WORD Characteristics; // 文件属性标志位
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
可选头
也有称呼其为扩展头的
typedef struct _IMAGE_OPTIONAL_HEADER32 {
WORD Magic; // 标识类型:0x10B 表示 PE32,0x20B 表示 PE32+
BYTE MajorLinkerVersion; // 链接器主版本号
BYTE MinorLinkerVersion; // 链接器次版本号
DWORD SizeOfCode; // 代码段总大小
DWORD SizeOfInitializedData; // 已初始化数据段大小
DWORD SizeOfUninitializedData; // 未初始化数据段大小(.bss)
DWORD AddressOfEntryPoint; // 程序入口点(RVA)
DWORD BaseOfCode; // 代码段起始 RVA
DWORD BaseOfData; // 数据段起始 RVA
DWORD ImageBase; // 程序首选装载基址
DWORD SectionAlignment; // 节区在内存中的对齐单位
DWORD FileAlignment; // 节区在文件中的对齐单位
WORD MajorOperatingSystemVersion; // 目标操作系统主版本
WORD MinorOperatingSystemVersion; // 次版本
WORD MajorImageVersion; // 程序版本号(主)
WORD MinorImageVersion; // 程序版本号(次)
WORD MajorSubsystemVersion; // 子系统版本号(主)
WORD MinorSubsystemVersion; // 子系统版本号(次)
DWORD Win32VersionValue; // 保留(一般为 0)
DWORD SizeOfImage; // 映像在内存中的总大小
DWORD SizeOfHeaders; // 所有头部的总大小(对齐后)
DWORD CheckSum; // 校验和(系统文件使用)
WORD Subsystem; // 子系统类型(GUI、CUI 等)
WORD DllCharacteristics; // DLL 特性标志
DWORD SizeOfStackReserve; // 保留的栈空间大小
DWORD SizeOfStackCommit; // 已提交的栈空间大小
DWORD SizeOfHeapReserve; // 保留的堆空间大小
DWORD SizeOfHeapCommit; // 已提交的堆空间大小
DWORD LoaderFlags; // 加载标志(保留)
DWORD NumberOfRvaAndSizes; // 数据目录数量(一般为 16)
IMAGE_DATA_DIRECTORY DataDirectory[16]; // 数据目录数组(导入表、导出表等)
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
程序的真正入口点 = ImageBase + AddressOfEntryPoint
-
虚拟地址 (Virtual Address, VA)
程序在内存中执行时使用的绝对地址
在32位系统中,这是一个0x00000000到0xFFFFFFFF范围内的值
-
映像基址 (ImageBase)
PE映像在内存中的起始虚拟地址
这是一个非常重要的值,加载器会优先尝试将文件加载到这里
-
相对虚拟地址 (Relative Virtual Address, RVA)
相对于
ImageBase的偏移量由于在创建PE文件时,无法预知它最终会被加载到内存的哪个确切位置,因此PE文件内部的大部分地址信息都以RVA的形式存在,这样便于后续的重定位
公式:
VA = RVA + ImageBase -
原始偏移 (RAW offset)
数据在磁盘文件中的位置,相对于文件开头的偏移量,起始值为0,就是我们在十六进制查看器里面看到的地址值

节表
紧跟在NT头后面的是节表,这是一个数组,它由多个节区头结构IMAGE_SECTION_HEADER结构组成
文件中有多少个节区,就有多少个节区头,节表就有多少个元素,详细描述着PE体中对应节区的属性
和ELF的节类似,PE的节也用于分类各种不同的数据
不过不同的是,PE的节是直接参与到程序运行中的,而ELF则依靠段运行,节删掉也无所谓
换言之,PE的节更像是ELF节与段的结合
除此之外,PE节的名称也有所不同,这里列举一些常见的节:
| 名称 | 作用 |
|---|---|
.text |
可执行代码 |
.data |
已初始化数据 |
.rdata |
只读数据(常量、字符串) |
.bss |
未初始化数据(通常不占文件空间) |
.rsrc |
资源(图标、菜单、对话框) |
.reloc |
重定位表 |
.idata |
导入表(Import Table) |
.edata |
导出表(Export Table) |
每个节区头大小固定为40字节
#define IMAGE_SIZEOF_SHORT_NAME 8
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; // 节名称,例如 ".text" ".data" ".rdata" ".rsrc"
union {
DWORD PhysicalAddress;
DWORD VirtualSize; // 节区在内存中的大小(RVA对应)
} Misc;
DWORD VirtualAddress; // 节在内存中的 RVA(相对于 ImageBase)
DWORD SizeOfRawData; // 节在文件中的大小(磁盘对齐后的字节数)
DWORD PointerToRawData; // 节在文件中的起始偏移
DWORD PointerToRelocations; // 重定位表指针(如果有重定位信息)
DWORD PointerToLinenumbers; // 行号信息指针(调试用)
WORD NumberOfRelocations; // 重定位表条目数量
WORD NumberOfLinenumbers; // 行号条目数量
DWORD Characteristics; // 节特性标志(可读、可写、可执行等)
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
可以看到各个节区的大小固定,不足的都使用0填充了:
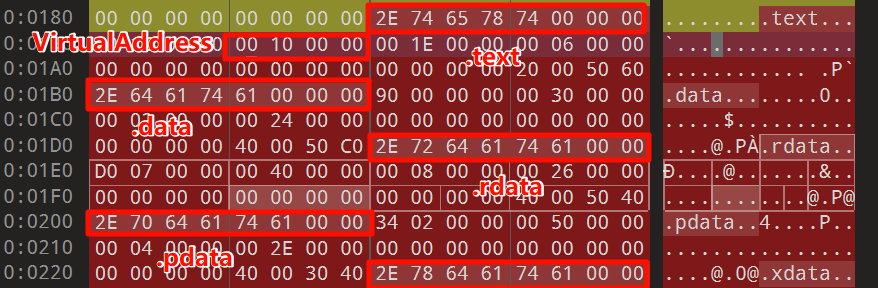
有一点需要注意的是,表示PE头(DOS头 + DOS Stub + NT头 + 节表)的大小的字段SizeOfHeaders是根据NT头的文件头的文件在磁盘的对齐字段FileAlignment对齐的,也就是SizeOfHeaders的大小按照FileAlignment向上取整,这种大小称作SizeOfRawData
另外还有SectionAlignment,这是文件在内存的对齐大小,一般要比FileAlignment大得多,虽然比较稀疏浪费空间,但可以提高CPU访问效率,这种大小称作VirtualSize
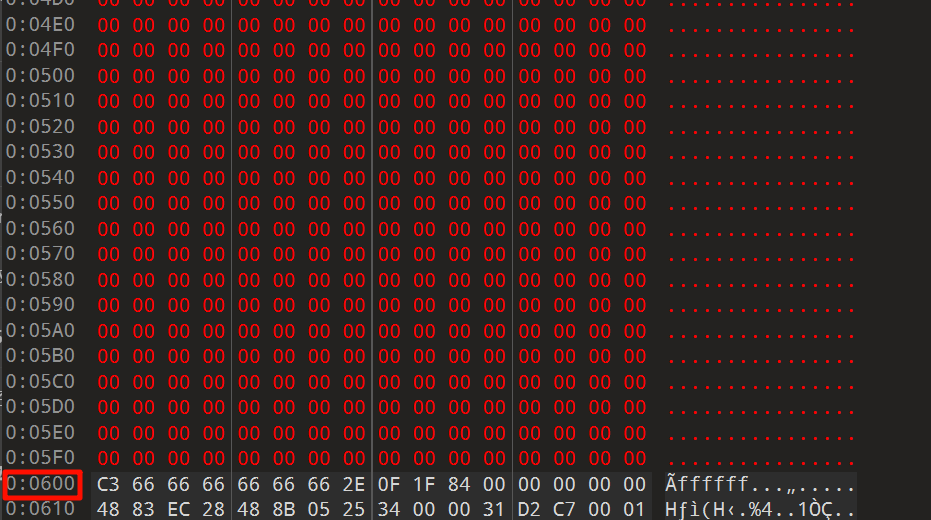
下图我们能看见示例exe里面的具体数据,SizeOfHeaders的确是FileAlignment的整数倍:
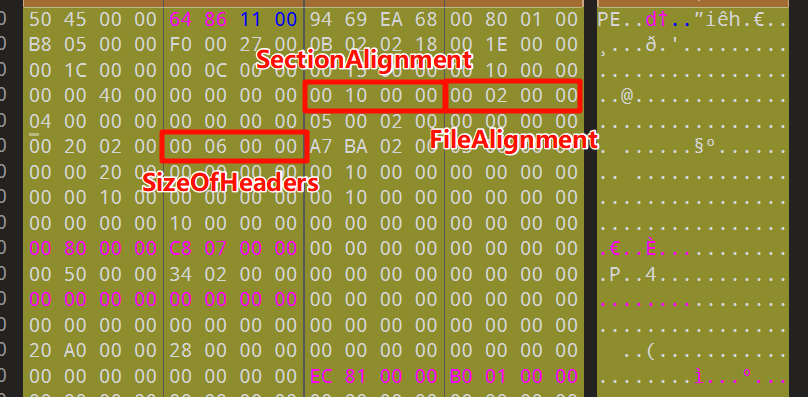
而PE头结束处地址也确实是600h,不足的地方都补0了:
更好的工具查看
虽然010有模版功能,但终究不是很直观,要找某一个字段还是有些困难
现在已经有很多PE文件结构查看器,比如PEview,就能很方便查看PE文件结构:
动态链接
动态链接库(DLL)
什么是DLL
DLL是一个独立于主程序文件之外的程序库文件,它包含可被多个应用程序共享使用的代码、数据和资源
与静态链接将LIB库代码直接嵌入到可执行文件中不同,DLL的代码和数据在程序编译时并不合并,而是在程序运行时才被链接到主程序中,就像ELF的.so共享文件
| 特性 | 静态库(.lib) | 动态库(.dll) |
|---|---|---|
| 链接时机 | 编译/链接阶段直接嵌入 EXE | 程序运行时才加载(动态链接) |
| 共享性 | 每个EXE拥有独立副本 | 多个进程可共享同一 DLL的代码段 |
| 文件大小 | EXE文件增大 | EXE文件较小,DLL独立存在 |
| 更新 | 更新库需重新编译 EXE | 更新DLL不需重新编译EXE(只要接口未变) |
可以使用软件dnspy对dll进行逆向
DLL的装载方式
显式链接(Explicit Linking)
程序运行到对应代码的时候时才装载DLL,使用完毕后立即释放内存
应用程序通过调用Windows API完成对DLL中特定函数的链接:
HMODULE hDll = LoadLibrary("example.dll"); // 加载 DLL
FARPROC func = GetProcAddress(hDll, "FunctionName"); // 获取函数地址
FreeLibrary(hDll); // 卸载 DLL
如果发现没办法调用目标DLL,程序才会报错
隐式链接(Implicit Linking)
程序启动时就装载所有需要使用的DLL,程序终止时才释放占用的内存
在EXE编译时就声明依赖DLL,Windows加载器在进程初始化时扫描EXE的导入表,并加载所有依赖DLL
如果DLL缺失,程序启动会失败
导入表
当一个PE文件需要调用其他DLL提供的函数(称为导入函数)时,它就通过导入表来记录这些依赖关系
PE文件加载时,Windows加载器会读取其导入表,得知它需要哪些DLL,之后加载器会找到并加载这些DLL,然后查询DLL的导出表,找到所需函数的真实内存地址,最后将这个地址填入PE文件的导入地址表中
导入表目录
不知道你是否还记得,在之前介绍可选头的时候,结构体里面最后有一个数组:
IMAGE_DATA_DIRECTORY DataDirectory[16];
其中第2个元素(OptionalHeader.DataDirectory[1])就是导入表的目录,它也是一个结构体:
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress; // 导入表在文件内存映像中的RVA
DWORD Size; // 导入表大小
} IMAGE_DATA_DIRECTORY;
它的作用就是指向导入表的开头
导入表结构
导入表由IMAGE_IMPORT_DESCRIPTOR数组构成,结构如下:
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics;
DWORD OriginalFirstThunk; //导入名称表 INT 的 RVA
};
DWORD TimeDateStamp; // 通常为 0
DWORD ForwarderChain; // 通常为 -1 或 0
DWORD Name; // DLL 名称的 RVA
DWORD FirstThunk; // 导入地址表 IAT 的 RVA
} IMAGE_IMPORT_DESCRIPTOR;
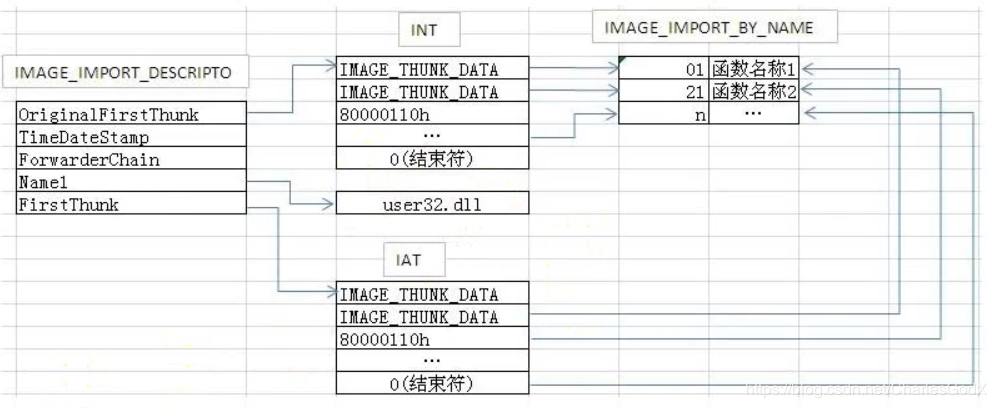
导入名称表(INT)与导入地址表(IAT)
导入名称表(Import Name Table,INT)与导入地址表(Import Address Table,IAT)都是IMAGE_THUNK_DATA结构的数组:
typedef struct _IMAGE_THUNK_DATA32 {
union {
DWORD ForwarderString; // 转发字符串的RVA(不常见)
DWORD Function; // 实际函数地址(IAT加载后填充)
DWORD Ordinal; // 按序号导入时的标志和序号
DWORD AddressOfData; // 指向 IMAGE_IMPORT_BY_NAME 的RVA(INT按名称导入时)
} u1;
} IMAGE_THUNK_DATA32;
-
导入名称表INT(OriginalFirstThunk):
每个条目指向
IMAGE_IMPORT_BY_NAME,包含导入函数的名称或序号:typedef struct _IMAGE_IMPORT_BY_NAME { WORD Hint; // 提示值(编译器生成的索引,用于加快查找) BYTE Name[1]; // 函数名称的字符串,以'\0'结尾 } IMAGE_IMPORT_BY_NAME;记录函数信息,但未解析真实地址
-
与导入地址表IAT(FirstThunk):
在加载前,IAT内容和INT 一模一样
加载时Windows加载器解析DLL中函数实际地址,然后覆盖IAT对应条目
程序调用函数时,通过IAT中的地址直接跳转
PE文件加载前:
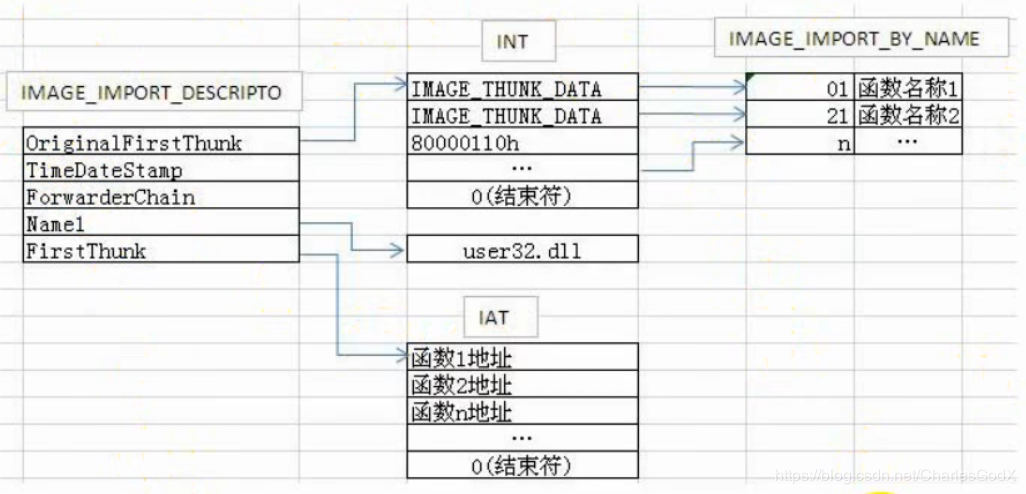
PE文件运行时:
读取INT条目获取函数名,使用DLL模块导出表找到函数实际地址,覆盖IAT对应条目
示例:分析notepad.exe的导入表
先区分几个概念以及公式:
-
虚拟地址 (Virtual Address, VA)
程序在内存中执行时使用的绝对地址
在32位系统中,这是一个0x00000000到0xFFFFFFFF范围内的值
-
映像基址 (ImageBase)
PE映像在内存中的起始虚拟地址
这是一个非常重要的值,加载器会优先尝试将文件加载到这里
-
相对虚拟地址 (Relative Virtual Address, RVA)
相对于
ImageBase的偏移量由于在创建PE文件时,无法预知它最终会被加载到内存的哪个确切位置,因此PE文件内部的大部分地址信息都以RVA的形式存在,这样便于后续的重定位
VA = RVA + ImageBase -
原始偏移 (RAW offset)
数据在磁盘文件中的位置,相对于文件开头的偏移量也就是文件偏移,起始值为0,就是我们在十六进制查看器里面看到的地址值
这个位置一般通过已知的RAW确定,特别是节的:
目标RAW = 节在文件中的起始位置 + (目标RVA - 节在内存中的起始虚拟地址)其中
节在内存中的起始虚拟地址就是节的RVA,节在文件中的起始位置就是节的RAWRVA - 节在内存中的起始虚拟地址计算的就是目标在节内的偏移尽量理解吧,真是弯弯又绕绕
先在OptionalHeader中找到导入表的RVA为0x2A5AC
(这个就是可选头末尾数组的第二项_IMAGE_DATA_DIRECTORY,存放了导入表的RVA和大小)
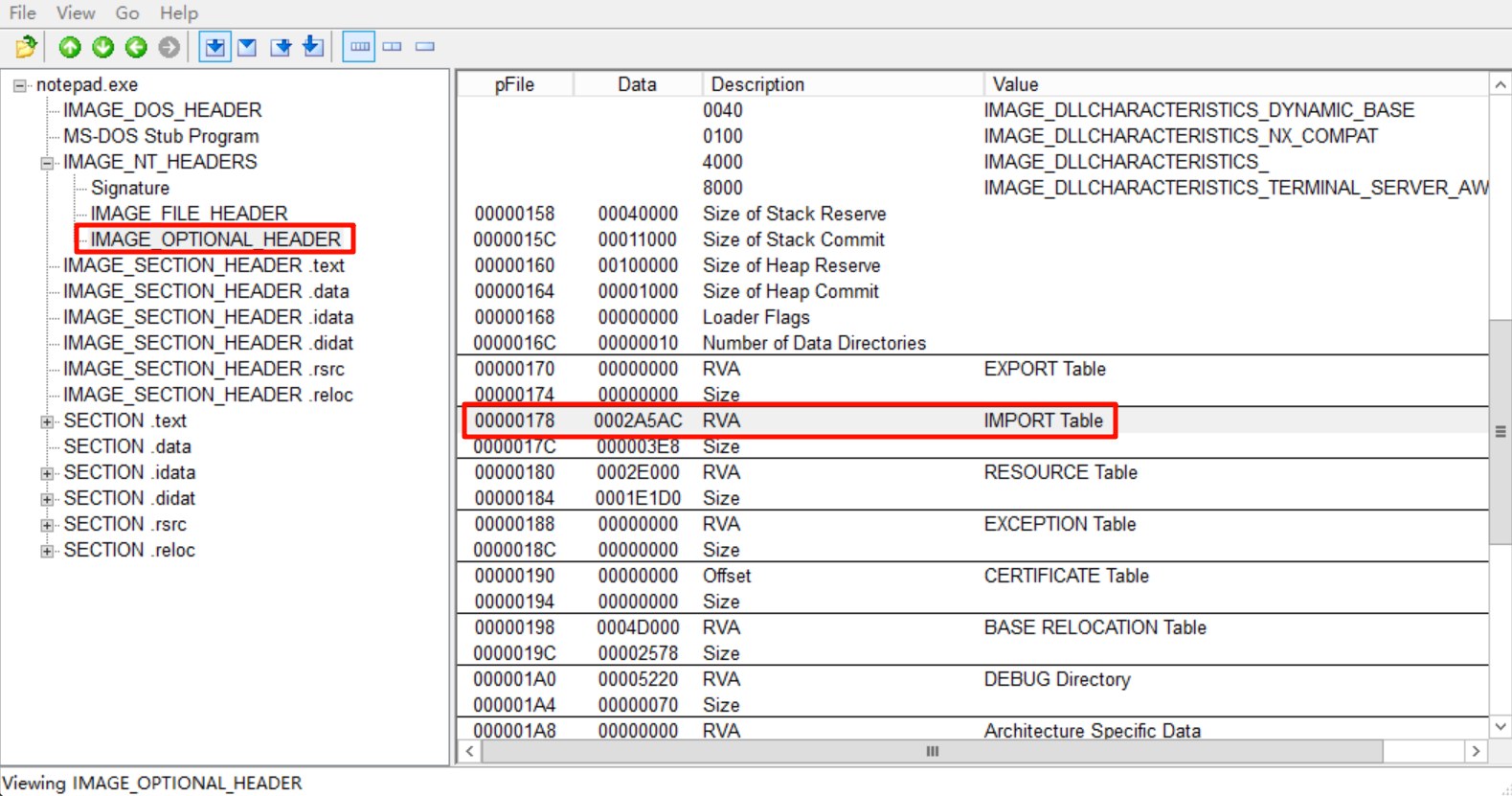
接下来我们要去找到表被存储在了哪个节里
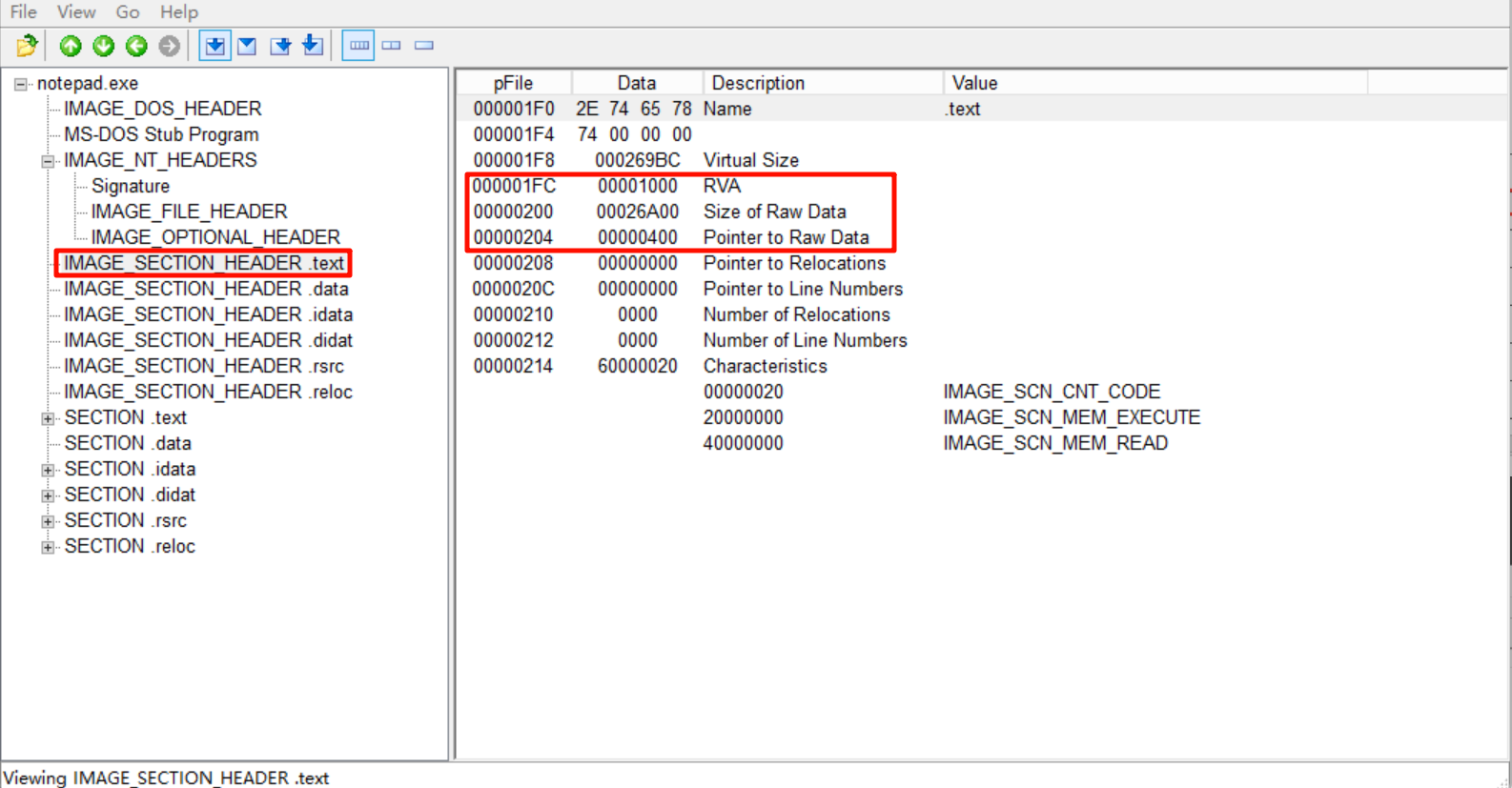
先看第一个.text节,我们关注的是RVA、SizeOfRawData、PointerToRawData
由于ImageBase只有一个值,我们就能通过RVA判断位置
因为0x01000 + 0x26A00 < 0x2A5AC,也就是说导入表的位置不可能在.text节里面:
就这样逐个往下找,能找到导入表位置在.idata节:
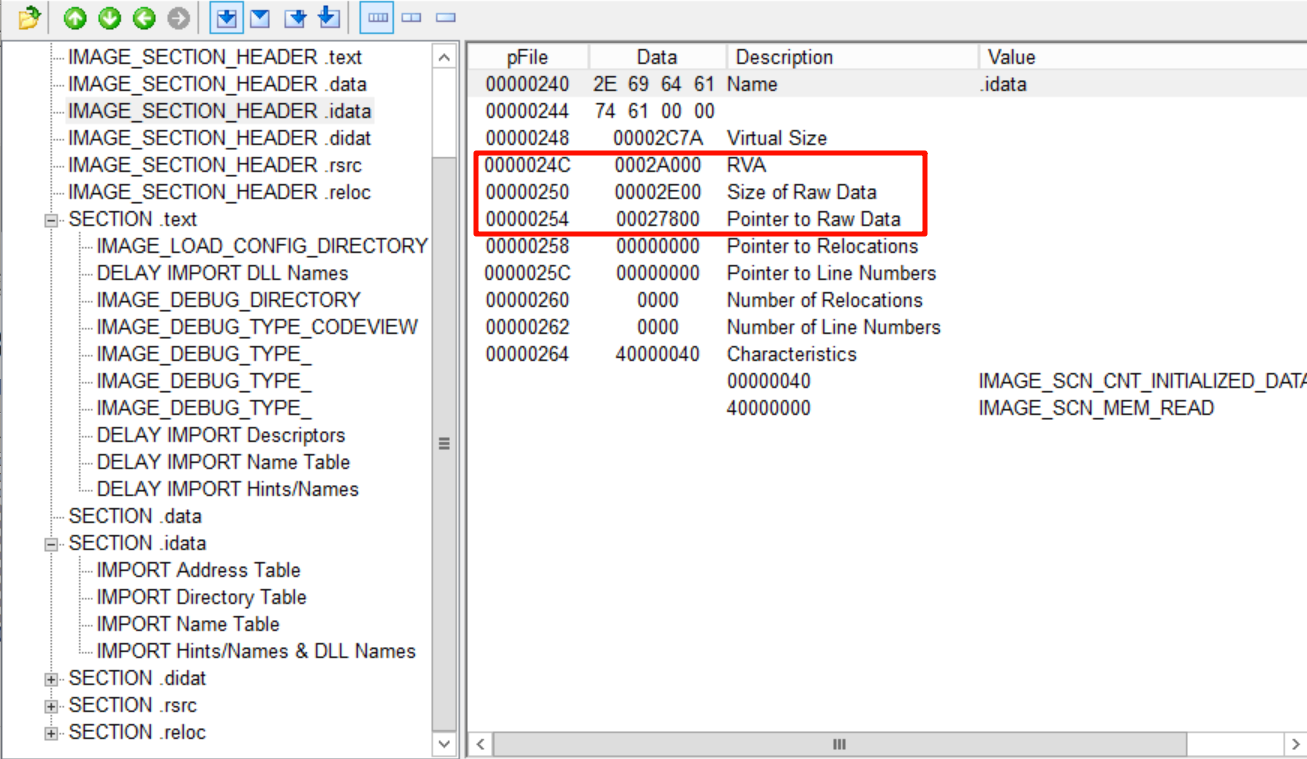
接下来,我们要求出导入表的RAW
知道了导入表的RVA为0x2A5AC,再结合.idata节的RVA(0x2A000)和RAW(0x27800),就能计算出第一个IMAGE_IMPORT_DESCRIPTOR在文件中的RAW为0x2A5AC - 0x2A000 + 0x27800 = 0x27DAC
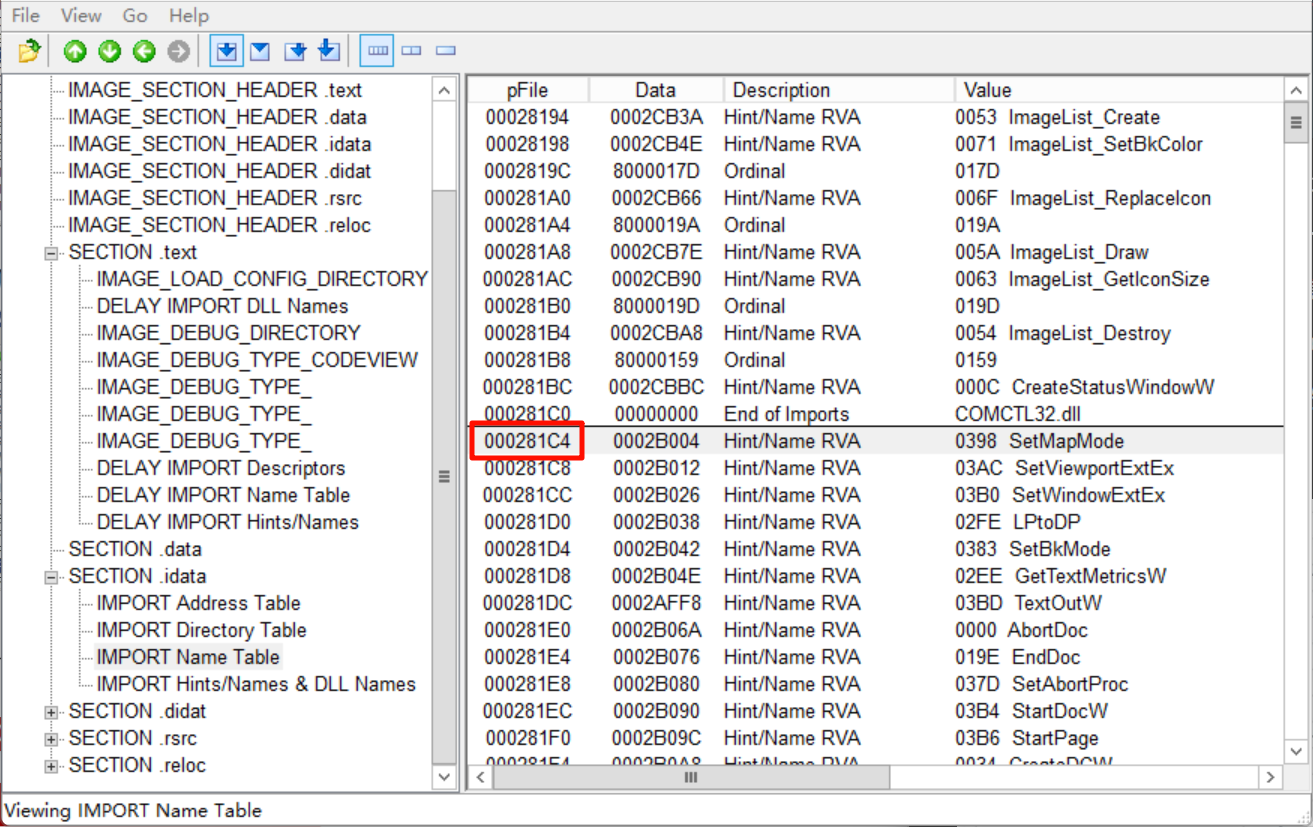
打开导入表,果然第一项的INT地址和我们算的一样(导入表结构最前面的就是INT):
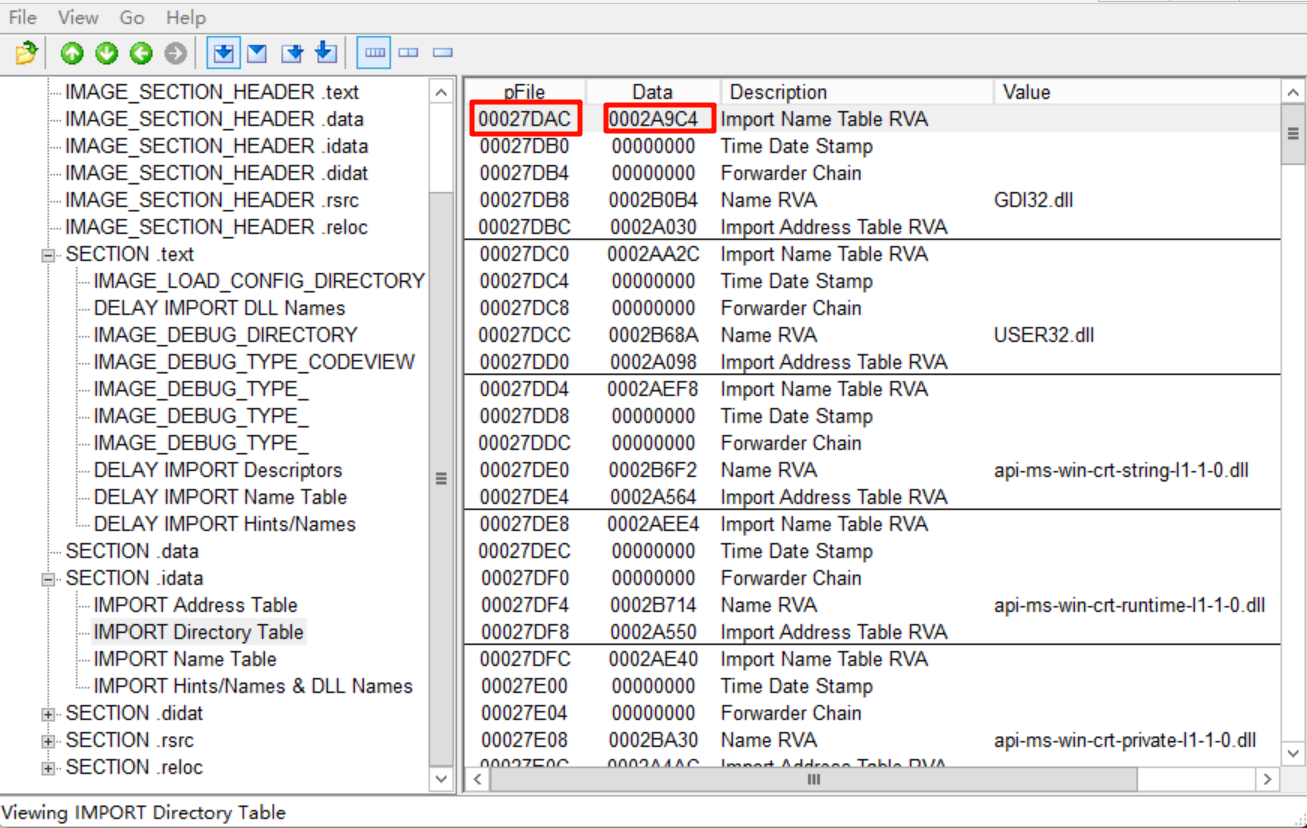
根据表里面存储的INT的RVA,能计算出它的RAW:
0x2A9C4 - 0x2A000 + 0x27800 = 0x281C4
查看INT,这个地址对应的就是第一项:
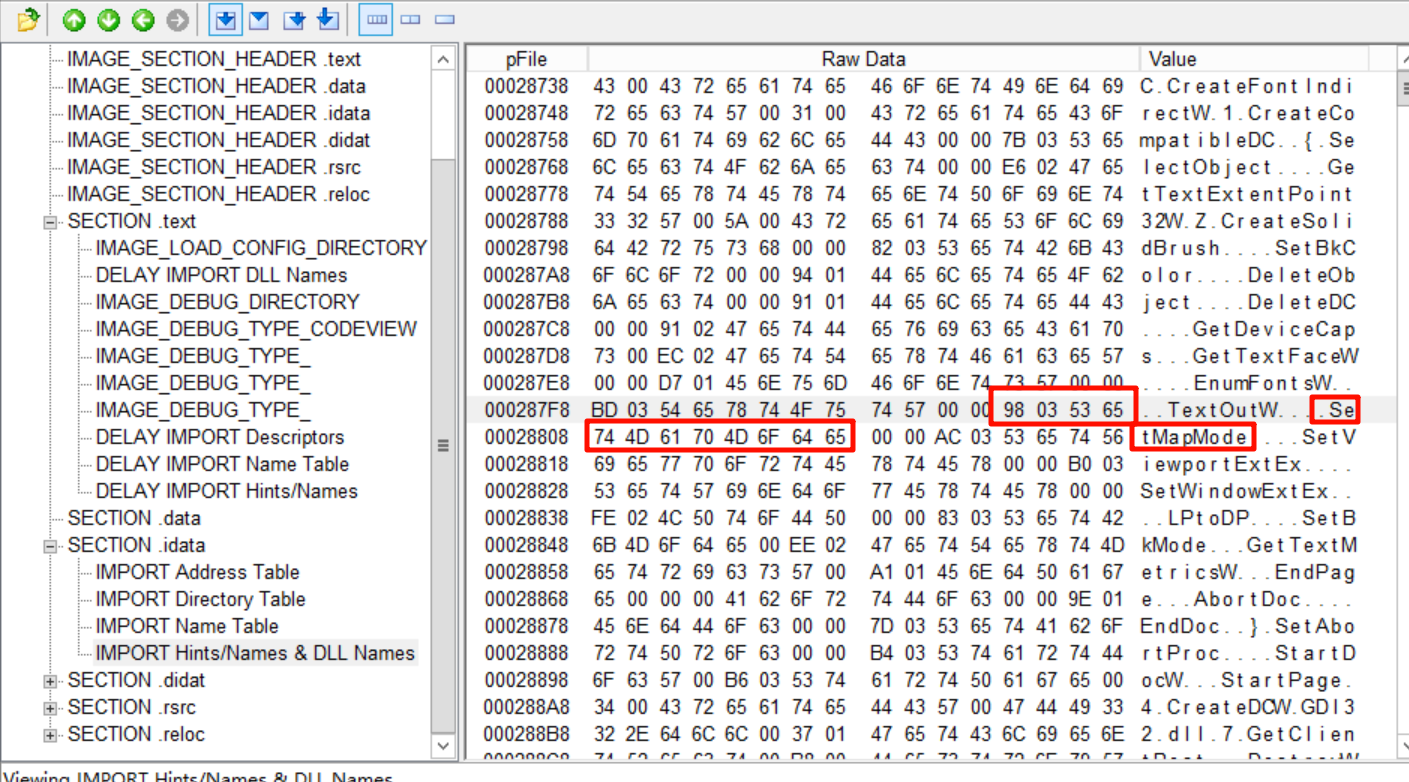
INT存储的是IMAGE_IMPORT_BY_NAME的RVA,还是这样算出RAW:
0x2B004 - 0x2A000 + 0x27800 = 0x28804
在文件偏移里能找到:
总结一下过程:
可选头的导出表入口 -> 导出表 -> INT -> IMAGE_IMPORT_BY_NAME
这一切都基于对应节的RAW
导出表
装载DLL文件时,实际上也创建了一系列能够被其他PE文件调用的函数,而导出表就是DLL文件用来告诉外界它能提供哪些函数的功能的,EXE文件通常没有导出表
和导入表一样,它的地址也在可选头末尾的数组里,是第一个元素OptionalHeader.DataDirectory[0]
组成导出表的结构如下:
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics; // 保留,通常为 0
DWORD TimeDateStamp; // 时间戳
WORD MajorVersion; // 主版本号
WORD MinorVersion; // 次版本号
DWORD Name; // DLL 名称 RVA
DWORD Base; // 起始序号(Ordinals 从 Base 开始)
DWORD NumberOfFunctions; // EAT 中函数总数
DWORD NumberOfNames; // ENT 中函数名总数
DWORD AddressOfFunctions; // EAT RVA(函数地址表)
DWORD AddressOfNames; // ENT RVA(函数名表)
DWORD AddressOfNameOrdinals; // 序数数组 RVA
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
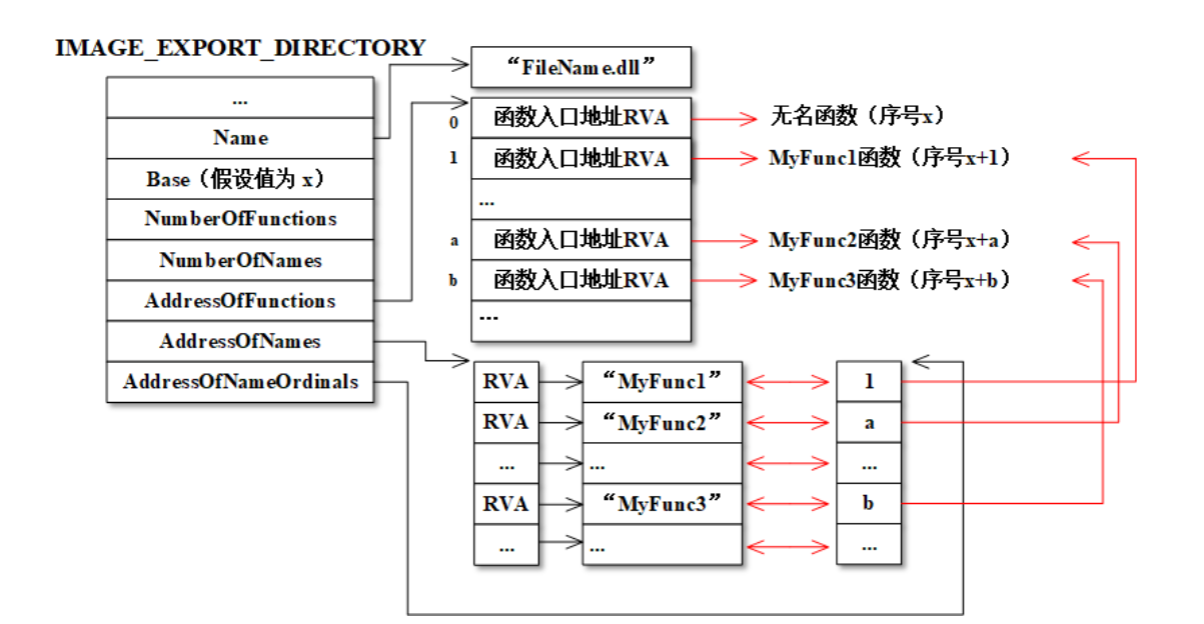
这个结构中包含了三个重要的指针数组的RVA:
AddressOfFunctions:指向导出地址表(EAT)AddressOfNames:指向导出名称表(ENT)AddressOfNameOrdinals:指向一个序数数组
这三个表协同工作:通过函数名在ENT中找到其索引,用这个索引在序数数组中找到对应的序数,最后用这个序数作为索引在EAT中找到函数的最终RVA
示例:分析kernel32.dll的导出表
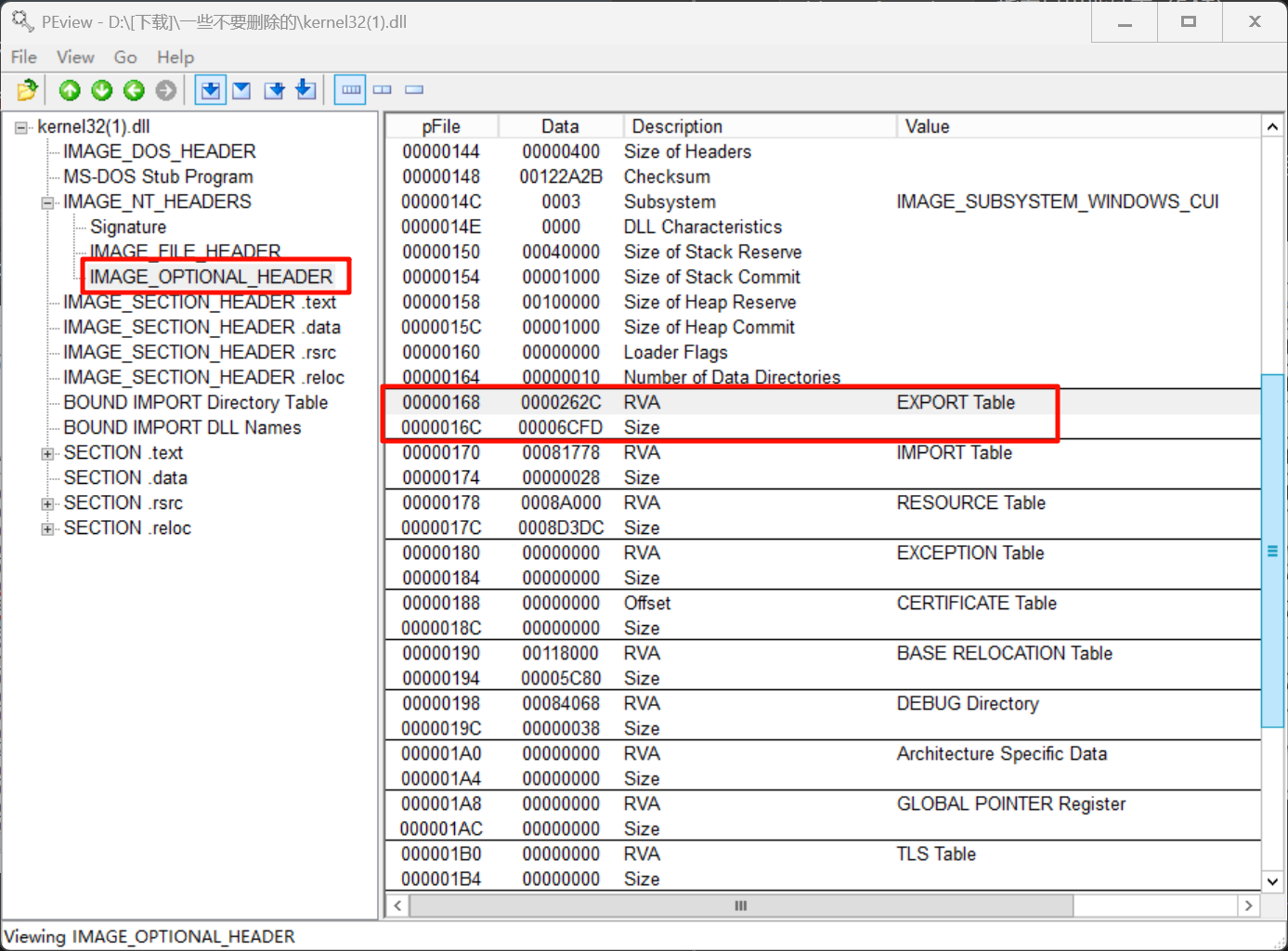
先找到导出表的位置
在可选头末尾数组的第一项找到导出表存放的RVA和大小:
在.text节能看到RVA+SizeOfRawData已经远大于导出表的RVA+Size,说明导出表就存放在.text中:
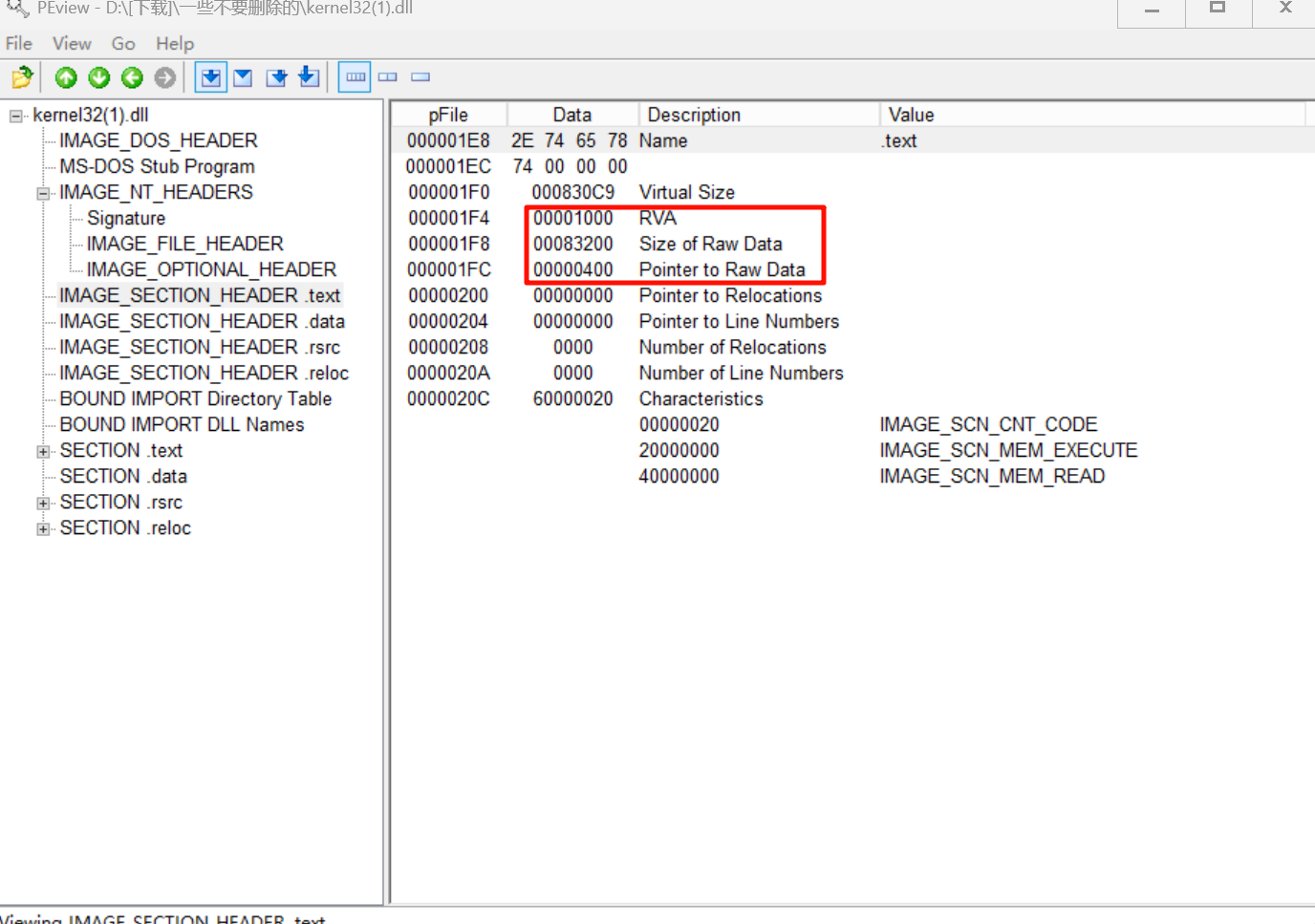
根据PointerToRawData,能找出第一个IMAGE_EXPORT_DIRECTORY项的RAW为0x262C - 0x1000 + 0x0400= 0x1A2C
在.text节里面找到导出表,可以看见第一个字段的文件地址就是0x1A2C:
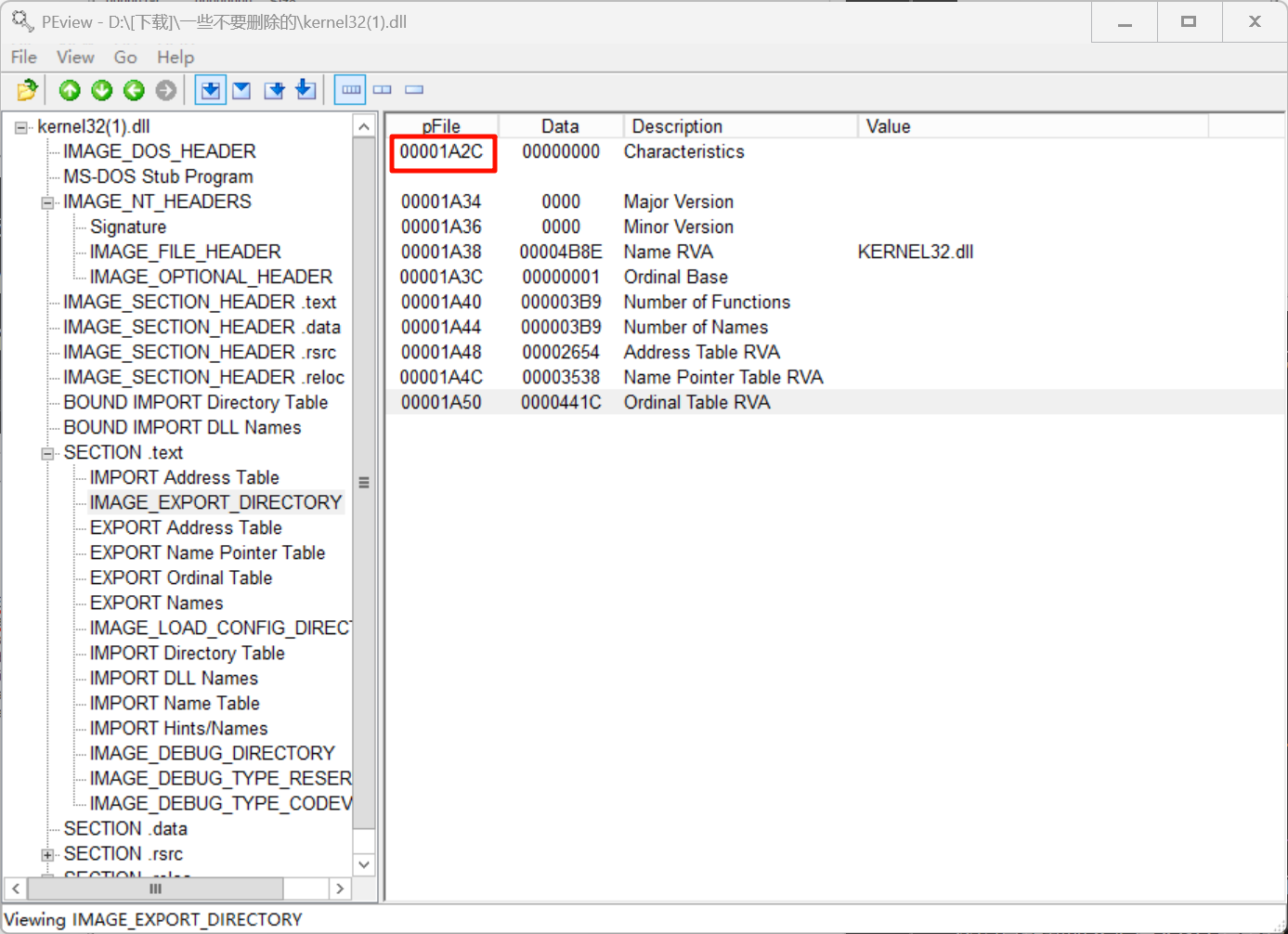
根据导出表开头的RVA数据,可以计算出各个部分内容的RAW:
DLL NAME:0x4B8E- 0x1000 + 0x0400= 0x3F8E

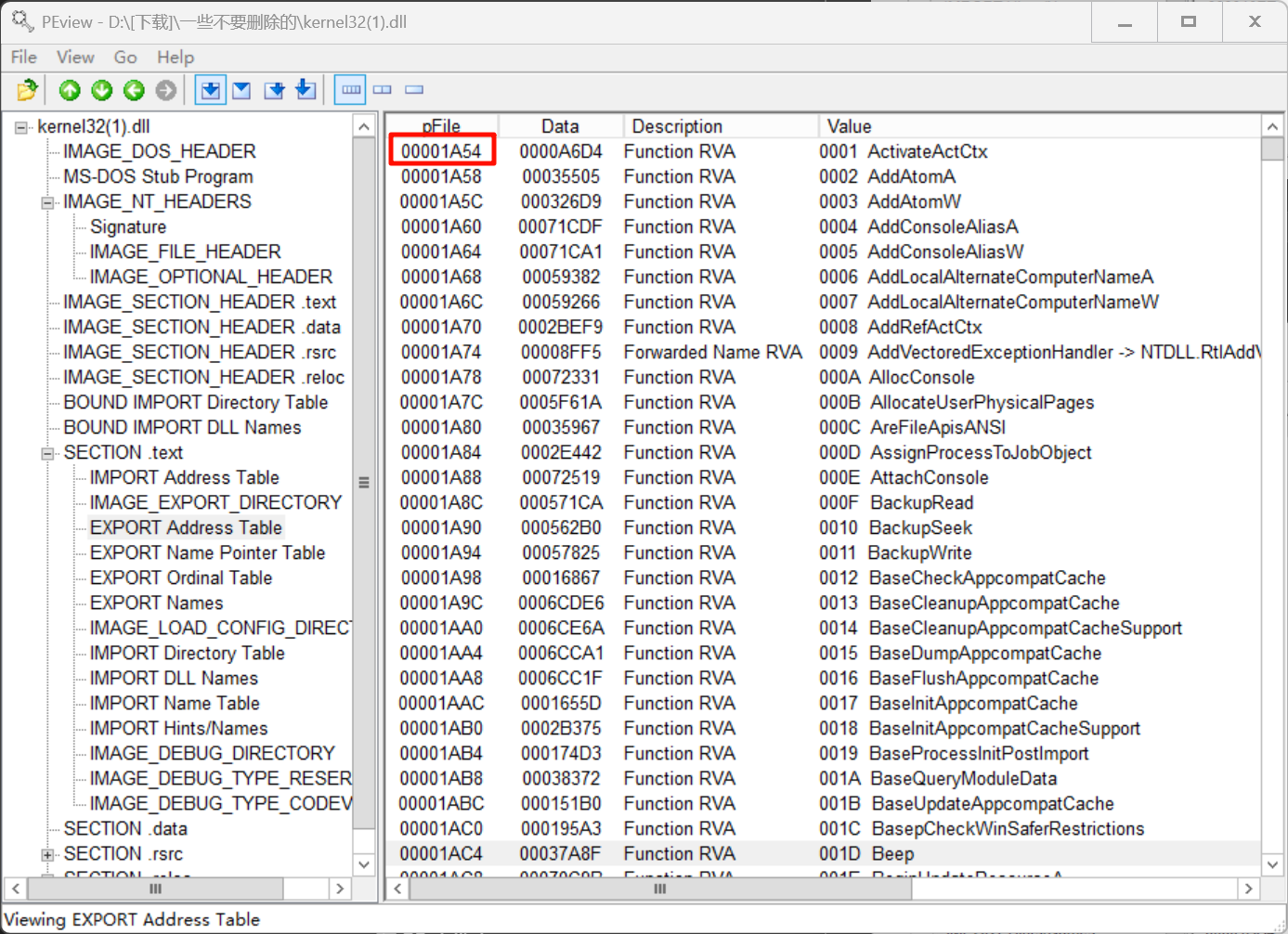
EXPORT Address Table:0x2654 - 0x1000 + 0x0400= 0x1A54
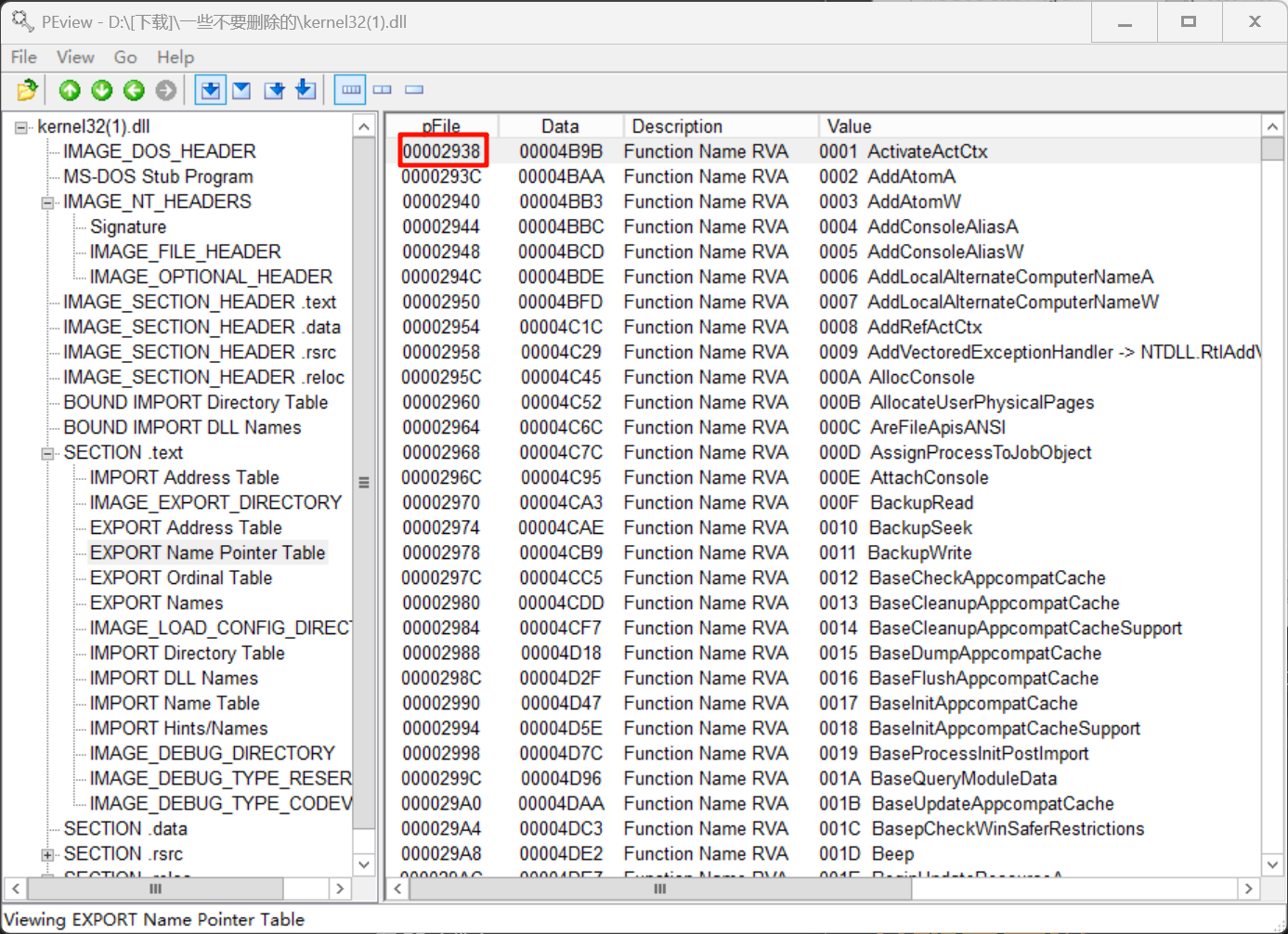
EXPORT Name Pointer Table:0x3538 - 0x1000 + 0x0400= 0x2938
EXPORT Ordinal Table:0x441C - 0x1000 + 0x0400= 0x381C
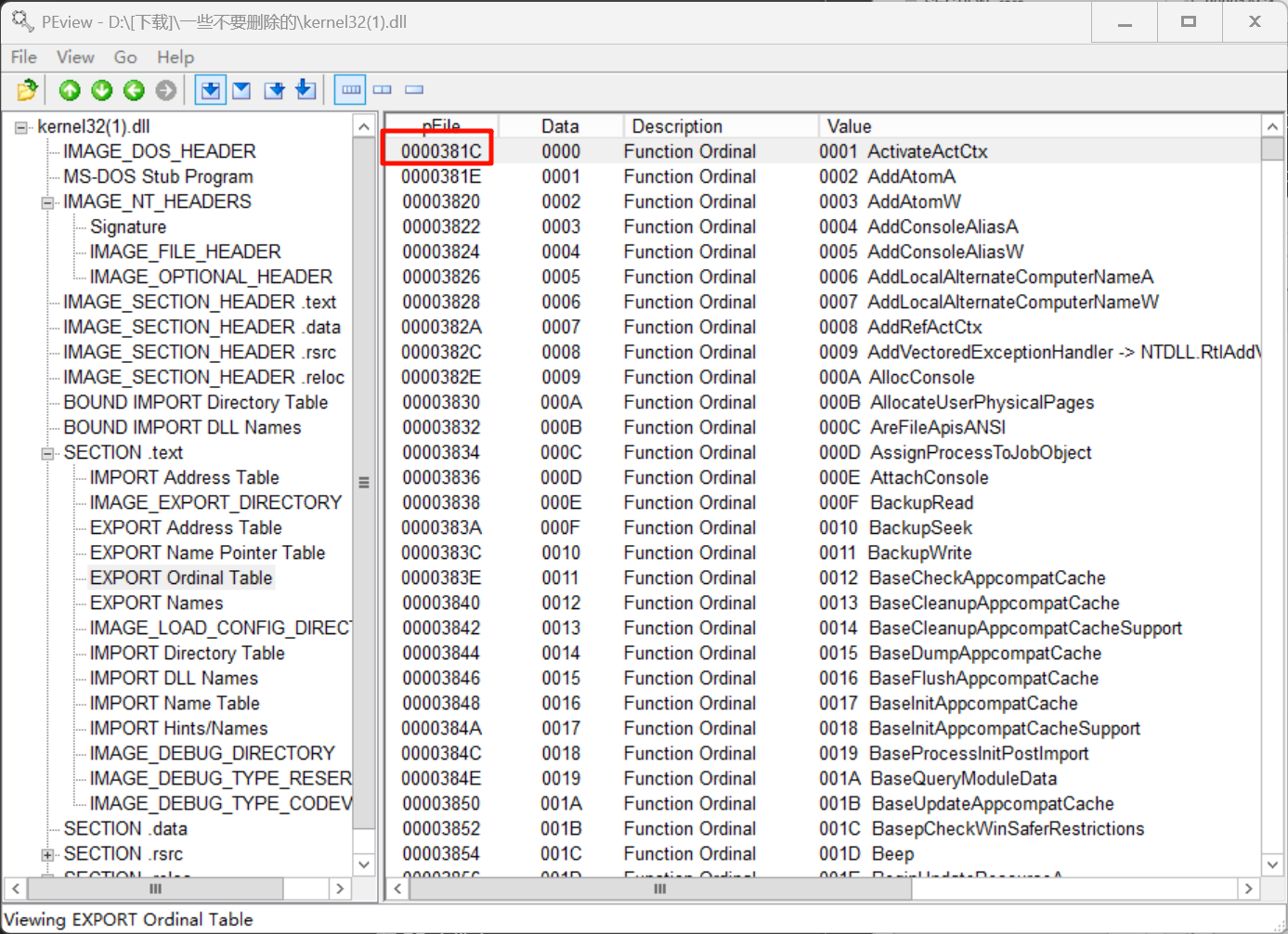
现在根据这些表我们找一下函数CreatProcessA的入口地址
第一步是在ENT表中找到该函数的索引,逐个匹配,最终在第62项找到CreatProcessA:
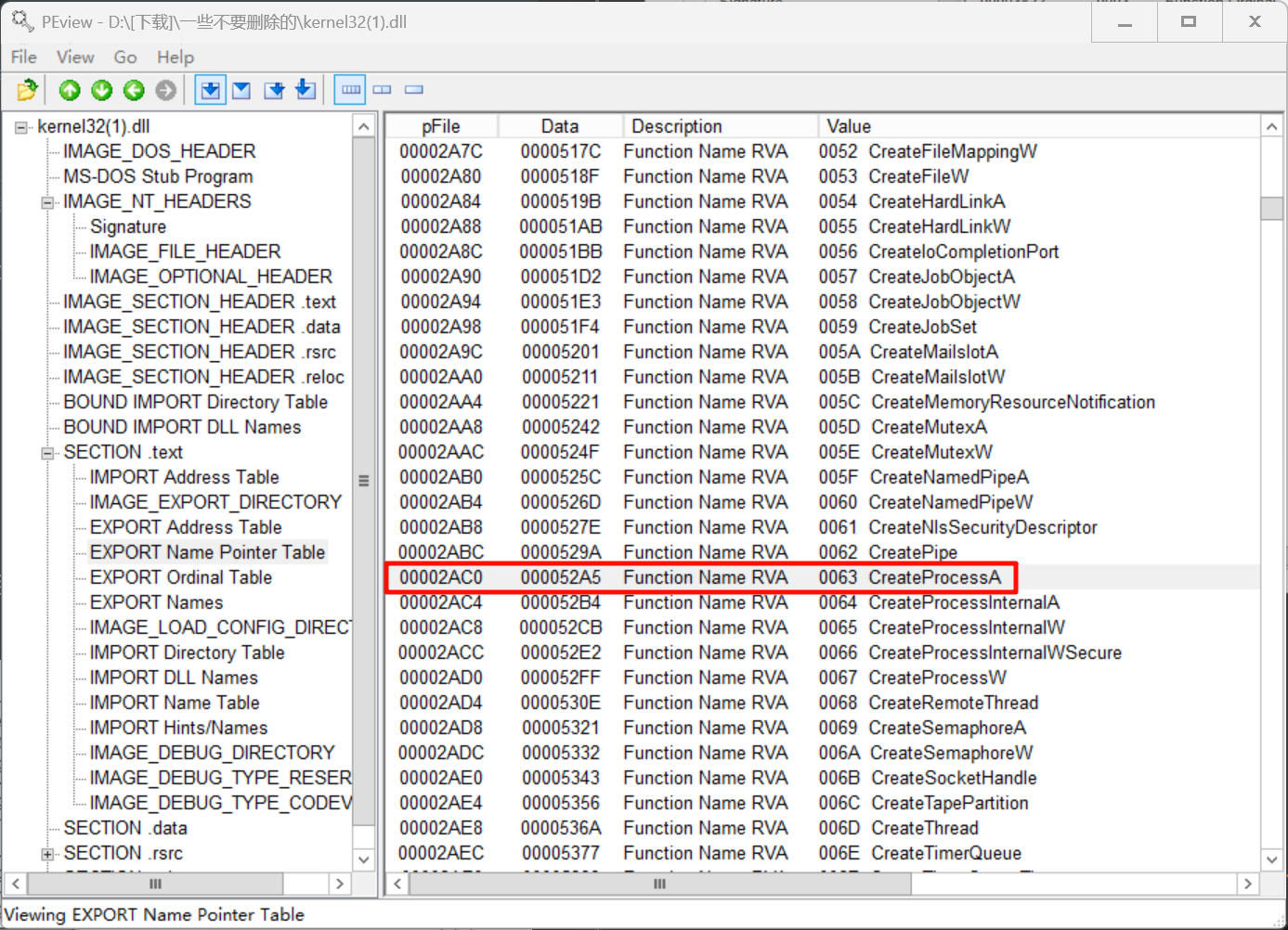
记下62这个索引值
接着来到序号表,这里每项大小是0x0002,取出第62项的值:0x381C + 62 * 0x0002 = 0x38E0
这里的表是按顺序来的,所以也是62:

最后来到EAT表,这里每项大小是0x0004,取出第62项:0x1A54 + 62 * 0x0004 = 0x1BDC
其中存放的RVA就是函数CreatProcessA的RVA0x236B:
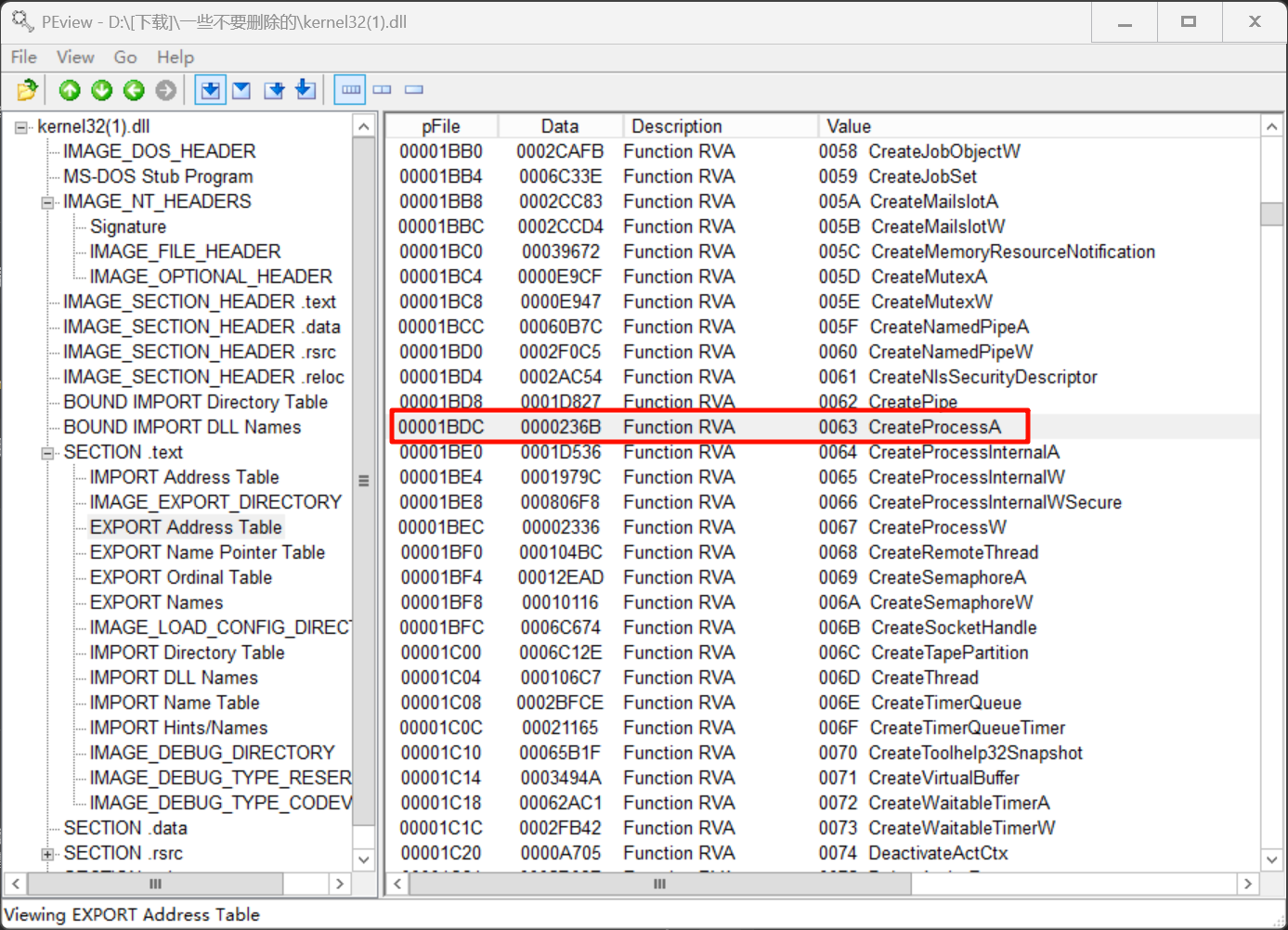
通过这个RVA计算RAW:0x236B - 0x1000 + 0x0400 = 0x176B
基址重定位
为什么需要重定位
当加载器准备将一个DLL加载到其首选的ImageBase地址时,如果该地址已经被其他模块占用,会发生什么?
答案是加载器会为这个DLL在内存中另找一个空闲的位置,然后对其进行基址重定位
虽然说PE文件中大部分地址是RVA,但代码或数据中仍然可能存在一些硬编码的绝对地址(也就是确定的虚拟地址,VA),这些地址是基于原始ImageBase计算的
当ImageBase改变时,这些地址就必须被修正:
新地址 = 硬编码地址 - 固有ImageBase + 实际加载基址
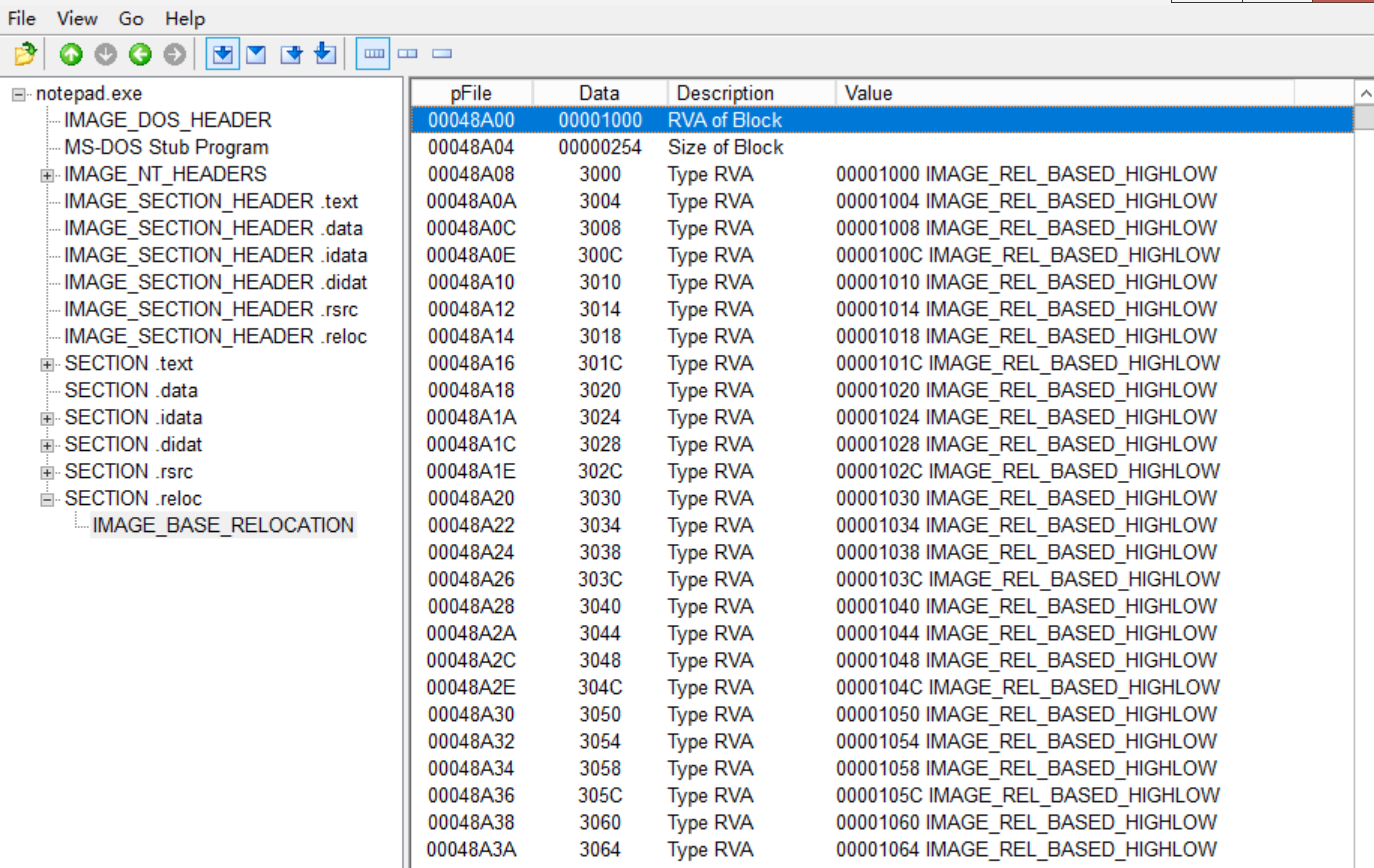
重定位表
PE文件通过基址重定位表来告诉加载器哪些位置存在硬编码地址需要修正
重定位表的地址也存放在可选头末尾的数组中,是第六个元素OptionalHeader.DataDirectory[5]
组成重定位表的结构如下:
typedef struct _IMAGE_BASE_RELOCATION {
DWORD VirtualAddress; // 本块起始 RVA(相对于 ImageBase)
DWORD SizeOfBlock; // 当前块大小,包括头部 + 16-bit 偏移表
WORD TypeOffset[1]; // 可变长度的 16-bit 数组,记录偏移和类型
} IMAGE_BASE_RELOCATION;
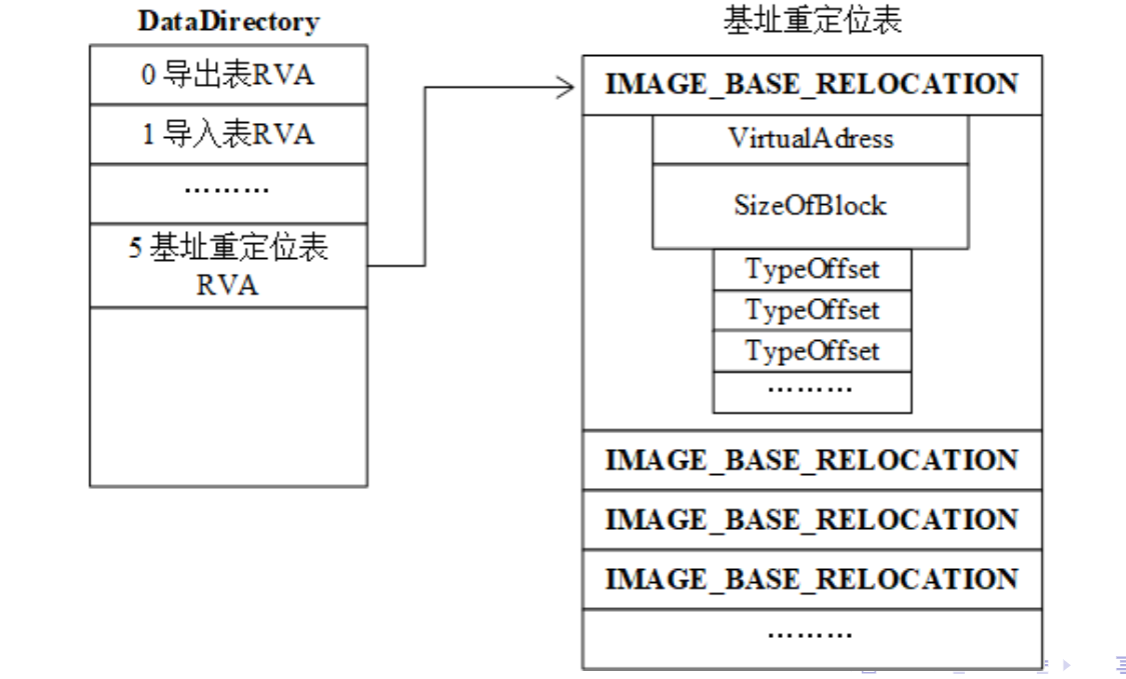
每个块中,VirtualAddress字段定义了一个基准RVA,块后面紧跟一个TypeOffset数组
TypeOffset是16bit元素构成的数组,每个元素可以如下分割:
-
高4bit:重定位类型
Type 描述 0 IMAGE_REL_BASED_ABSOLUTE(不调整,占位用) 3 IMAGE_REL_BASED_HIGHLOW(32-bit 地址调整,常用在 PE32) 10 IMAGE_REL_BASED_DIR64(64-bit 地址调整,PE32+) 其他 不同平台/特殊用途 -
低12bit:相对于VirtualAddress的偏移
将这个偏移量与块的基准RVA相加,就得到了一个需要被重定位的硬编码地址的RVA
加载器会定位到这些RVA的RAW,读取其中的硬编码VA,然后进行修正
它们就存储在.reloc节里: