
经过前几节课,跟着破解了几个crack,我也觉得我成逆向大神了……吗?
破解软件哪有那么容易,尤其是商用的,更不可能将自己的代码就这样暴露在大众面前,肯定会想方设法提高逆向工程的难度!
之前我们提到过,删掉ELF的节表就能很好的做到这一点,但是那毕竟只在linux上,有没有更普遍的做法呢?
这就是这篇文章要说的技术 —— 代码混淆(Obfuscation)
所谓知己知彼,百战不殆,只有知道混淆是什么后,才知道如何去对抗和破解它
混淆的基本原理
混淆是什么?
混淆是一种程序变换技术,其目的是通过重构代码,在保持程序原有功能(语义)等价的前提下,增加代码的复杂性,使其更难以被逆向分析和理解
这个过程可以被视为一个转换:

混淆可以在多个不同层次上进行:
- 源代码级:对高级语言代码(如C、Java)进行变量重命名、逻辑变换等
- 中间代码/字节码级:针对.NET或Java的字节码进行混淆
- 汇编/二进制级:直接对编译后的机器码或汇编代码进行修改
有些不理解?让我们来看一个具体的汇编混淆片段(为了方便观看,前面就加上行号了):
01 XOR EBX, EAX
02 XOR EAX, EBX
03 XOR EBX, EAX
04 INC EAX
05 NEG EBX
06 ADD EBX, 0A6098326H
07 CMP EAX, ESP
08 MOV EAX, 59F67CD5H
09 XOR EAX, 0FFFFFFFFH
10 SUB EBX, EAX
11 RCL EAX, CL
12 PUSH 0F9CBE47AH
13 ADD DWORD PTR [ESP], 6341B86H
14 SBB EAX, EBP
15 SUB DWORD PTR [ESP], EBX
16 PUSHFD
17 PUSHAD
18 POP EAX
19 ADD ESP, 20H
20 TEST EBX, EAX
21 POP EAX
哇,真是写了好多啊,那这么长的代码,实现了什么强大的功能呢?
我们一步一步看:
寄存器交换:
; 初始状态: EAX = N, EBX = M
01 XOR EBX, EAX ; EBX = M ^ N
02 XOR EAX, EBX ; EAX = N ^ (M ^ N) = M (即 EBX 的初始值)
03 XOR EBX, EAX ; EBX = (M ^ N) ^ M = N (即 EAX 的初始值)
这是一个不使用第三个寄存器来交换EAX和EBX内容的技巧,看着虽然有些复杂,但也还合理
垃圾指令:
04 INC EAX ; EAX = EAX + 1
05 NEG EBX ; EBX = -N (对N取补)
06 ADD EBX, 0A6098326H ; EBX = -N + 0A6098326H
07 CMP EAX, ESP ; 比较 EAX 和 ESP
嗯?有些不对劲了
行04修改了EAX —— 但是EAX的值在后面的第08行被完全覆盖了,所以这次INC没有任何意义!它完全可以不存在,也就是一条垃圾指令!
行05和06是对EBX的值N的取补计算
行07的CMP会设置EFLAGS标志寄存器,但这些标志位在被任何条件跳转指令使用之前,就被第09行的 XOR指令给覆盖了(它也会修改标志位),所以这也是一条垃圾指令!
好吧好吧,反正这部分结束之后,EBX的值变成了-N + 0A6098326H
常量展开:
08 MOV EAX, 59F67CD5H ; EAX = 59F67CD5H
09 XOR EAX, 0FFFFFFFFH ; EAX = NOT 59F67CD5H = 0A609832AH
10 SUB EBX, EAX ; EBX = EBX - EAX
行08和09没有直接使用MOV EAX, 0A609832AH修改EAX,而是通过两步计算(XOR 0xFFFFFFFF等同于NOT,即按位取反)来得到这个值,增加了分析难度,这种方法叫做常量展开
行10用EBX减去EAX:EBX = (-N + 0A6098326H) - 0A609832AH = -N - 4
这是一个重要的中间结果, EBX的值变成了-N - 4
基于栈的混淆:
11 RCL EAX, CL ; [垃圾指令]
12 PUSH 0F9CBE47AH ; 压入一个常量
13 ADD DWORD PTR [ESP], 6341B86H ; 0F9CBE47AH + 6341B86H = 0
14 SBB EAX, EBP ; [垃圾指令]
15 SUB DWORD PTR [ESP], EBX ; [ESP] = 0 - EBX
行11和14都是垃圾指令,因为EAX的值在第18行被POP覆盖了
行12和13再次使用了常量展,它们的目的仅仅是PUSH 0
行15从栈顶的值中减去EBX,也就是:[ESP] = 0 - (-N - 4) = N + 4
此时,N + 4这个值在栈顶,没有在代码表面
复杂的空操作:
16 PUSHFD ; 压入 EFLAGS (4 字节)
17 PUSHAD ; 压入所有通用寄存器 (8 * 4 = 32 字节)
18 POP EAX ; 弹出 4 字节 (PUSHAD 压入的 EAX)
19 ADD ESP, 20H ; 弹出 32 字节 (20H = 32)
20 TEST EBX, EAX ; [垃圾指令]
行16和17一共向栈上压入了4 + 32 = 36字节的数据,行18和19一共从栈上弹出了4 + 32 = 36 字节的数据
这四条指令 (16, 17, 18, 19) 组合起来,是什么也没做!同时,它还搅乱了EAX寄存器,真是太坏了
行20也是垃圾指令,它设置的标志位并没有被使用
所以,这四行完全就是纯废话
获取最终结果:
21 POP EAX ; 弹出栈顶的值到 EAX
结果是EAX = N + 4
也就是说,这一长串令人眼花缭乱的代码,其等价语义仅仅是:
ADD EAX, 4
真是神乎其技,对吧?哎呦,恶心死了
这个例子里面体现了哪些混淆的方法呢,我们来看看:
-
基于模式的混淆
把常见的逻辑替换成了绕人的写法,比如
XOR交换 -
常量展开
用计算代替常量
0和0A609832AH,必须一步步分析才知道最后的结果 -
无关代码插入
大量的垃圾指令,完全没有意义的操作
-
基于栈的混淆
运算结果暂存在栈上,光看寄存器或者内存什么都看不出来
-
使用不常用指令
RCL、SBB、PUSHFD、PUSHAD,这几个指令除了RCL,我都没有写在逆向基础的第一章……
这些混淆方法后面我们一个个说
理论上的安全性
理论上,一个完美的混淆器应该具有所谓的虚拟黑盒(Virtual Black-Box, VBB)属性
这意味着,一个源程序$P$被混淆后得到的程序$P’$所能提取到的任何信息,都应该同样能通过“黑盒”访问(即只观察输入和输出)得到
换句话说,对于攻击者而言,拥有$P’$的代码文本并不比只拥有$P$的执行权限能获得更多信息
一个完美的混淆器应满足三个条件:
- 功能性:混淆后的程序$P’$与原程序$P$功能完全相同
- 多项式减速:$P’$的执行时间和空间开销相比$P$最多呈多项式级增长
- 虚拟黑盒属性:如上所述,拥有$P’$代码的攻击者无法比只拥有$P$的访问权的攻击者推断出更多信息
现状与应用
但理论终究是理论而已
2001年已有研究证明,能够满足上述所有条件的完美混淆器是不存在的!
因此,在现实世界中,混淆的目标并非实现理论上的绝对不可分析,而是使逆向分析付出的成本要大于通过逆向可能获得的收益,也就是努力让破解软件的人放弃
混淆技术被广泛应用在以下领域:
- 恶意软件:病毒、木马等用于对抗安全软件的分析和检测
- 软件知识产权保护:保护商业软件的核心算法不被窃取
- 软件防篡改:增加攻击者修改程序逻辑(如绕过付费验证)的难度
+++
下面我们正式来介绍混淆方法
数据混淆
数据混淆侧重于隐藏程序中使用的数据,如常量、字符串、变量等
常量展开
defend
常量展开是一种与编译器优化相反的技术,它将代码中一个明文常量替换为一组计算过程,而这个过程的最终结果等于该常量
也就是说,攻击者不能通过简单的查看某一个明文值来得到最终的结果,必须对大块的代码进行分析
之前例子我们已经见过:
PUSH 0F9CBE47AH ; 压入一个立即数
ADD DWORD PTR [ESP], 6341B86H ; 栈顶值变为 0F9CBE47AH + 6341B86H = 0
这就是把0这个值隐性地加入了逻辑中
更高级的常量展开不会将计算指令紧挨着放在一起,而是将它们交错在大量不相关的垃圾指令之间:
MOV EAX, 0F9CBE47AH
; ... (大量垃圾指令)
XOR EBX, EBX
CMP ECX, 5
; ... (更多垃圾指令)
PUSH EAX
ADD DWORD PTR [ESP], 6341B86H
分析器很难将PUSH和ADD两条指令关联起来,从而无法轻易识别出0这个常量
attack
如何破解这种混淆呢?
最简单的方法是动态分析,在调试器中运行到该代码块之后,直接看栈顶或目标寄存器的值就行
如果是静态分析,大多数工具会将寄存器和内存视为符号变量,而不是具体数值
比如,当它们分析MOV EAX, 0F9CBE47AH时,EAX的值会被记为类似这样的形式:
sym_EAX = 0F9CBE47AH
之后到ADD DWORD PTR [ESP], 6341B86H时,会自动计算出:
sym_ESP_val = 0F9CBE47AH + 6341B86H = 0
也就是在静态的时候把变量全部计算出来
同时,静态分析工具还能追踪特定寄存器或内存位置的值,这可以跨越垃圾指令,找出所有修改该值的指令,并最终计算出结果
基于模式的混淆
defend
这种技术将一条或多条指令,替换为另一组功能上等价、但形式上更复杂的指令序列
其实也就是所谓的把简单问题复杂化
模式的混淆可以在高级语言,也能在汇编语言,下面给出一些示例
高级语言层面:
| 原始运算 | 等价混淆运算 |
|---|---|
| -x | ~x + 1 |
| $x + 1$ | $-(\sim x)$ |
| $x - 1$ | $\sim(-x)$ |
| rotate left (x, y) | $(x«y)$ |
汇编语言层面:
| 原始指令 | 等价混淆指令 |
|---|---|
PUSH REG32 |
SUB ESP, 4、MOV DWORD PTR [ESP], REG32 |
PUSH REG32 |
LEA ESP, [ESP-4]、MOV DWORD PTR [ESP], REG32 |
MOV EDX, IMM32 |
CALL $+5、POP EDX、XOR EDX, (Mask ^ IMM32) |
MOV EDX, OFFSET LBL JMP EDX |
PUSH (OFFSET LBL ^ Mask)、POP EDX、XOR EDX, Mask、JMP EDX |
汇编层面的模式替换更难,因为它不仅要保证通用寄存器的结果等价,还必须考虑对标志位寄存器的副作用是否等价,但汇编层面的模式替换往往比高级语言层面的更有效,怎么办呢?
于是,自动化的混淆器诞生了
高级混淆器拥有一个庞大的等价指令模板库,例如对于ADD EAX, 1,它可能有10种不同的实现方式
在混淆时,它会随机从库中挑选一个模板,这意味着同一个原始函数在两次不同混淆后,其二进制代码可能是完全不同的,并且这个库还能随时更新,这使得基于签名的模式匹配完全失效
attack
反编译器对于破解这种混淆非常有效,因为它们的核心功能是语义分析,不关心具体指令的实现
比如,随便汇编的PUSH怎么玩,反编译器只关心在函数X的第Y行,REG32被放到了栈顶
这样一来,就算模式被替换了,反编译生成的伪C代码很可能是一样的
由于各种技术原因,反编译器并不是在还原真实的源代码,而是在猜测性地重建一种“看起来像C的高层语义表示”,它未必是标准C、未必可编译、也未必与原代码逐字等价,所以叫伪C代码(pseudocode)
此外,某些脚本或插件可以在汇编层面模拟编译器的优化器,它会检查一个小的指令窗口(例如3-5条指令),如果发现SUB ESP, 4; MOV [ESP], EAX这样的模式,就自动将其折叠(或注释)为PUSH EAX
当然,这种方法在上面也说过,很容易被针对
数据编码
这是一种更高级的混淆方式
普通编码
defend
- 编码:设定一个编码函数 $y = f(x)$。在程序中不存储原始数据 $x_0$,而是存储编码后的数据 $f(x_0)$
- 解码:在运行时,当需要使用 $x_0$ 时,再通过 $f(x_0)$ 将其恢复(解码)为 $x_0$
对编码函数$f$的要求是,它必须是难以逆向的,即从 $y_0$ 难以推断 $x_0$,或者从多组 $(x, y)$ 难以推断出 $f$
比如,程序中的数据(特别是字符串、API名、常量)是以加密形式存储在.data或.rdata段中的
一个经典的同态混淆是MBA (Mixed Boolean-Arithmetic) ,它将一个简单的算术运算(如z = x + y)替换为一个极其复杂的、但代数上等价的混合布尔-算术表达式
例如,z = x + y可以被替换为:
z = (x ^ y) + 2 * (x & y)
更可能是:
z = ( ( (x & ~y) | (~x & y) ) + ( (x | y) & (x & y) ) * 2 )
这样,攻击者面对的就是一个由XOR、OR、AND、ADD等等指令组成的巨大公式,极难将其还原
这个看上去有点像模式混淆,但是他们其实是不一样的:
-
模式混淆改的是指令形貌,属于语法层
-
数据编码改的是算式,属于语义层
反编译器对前者通常是秒杀,但对后者需要做数学
attack
这种编码方式有一个致命的缺点:数据使用的时候,会被解密成明文
那么,只要攻击者在调试器中对存储加密数据的内存地址设置一个内存断点,当程序读取该数据(准备解密)时,只需单步跟踪,就一定能看见解密的过程,U直到解密完成,即可在内存或寄存器中看到明文
或者也能在某个函数执行前,转储一次进程内存,执行函数后,再转储一次,比较两次快照的差异,往往能直接发现解密到内存中的明文数据,不过这种方法很容易被**用后即焚(使用完解密数据后立刻清除)**防御住
同态编码
defend
正如之前所说的,一般的数据编码方案需要在每次使用数据前都进行动态解码,这会带来开销和风险
一个好的方案是,我们能直接在编码后的数据上实施运算 —— 这就是同态的概念
在抽象代数中,同态是两个群 $G$(源代数)和 $H$(目标代数)之间的一个映射 $f$,它保留了运算结构
例如,如果 $G$ 和 $H$ 分别支持 $+_g$ 和 $+_h$ 运算,则 $f(x +_g y) = f(x) +_h f(y)$
在混淆中,这意味着我们可以对编码后的数据 $f(x)$ 和 $f(y)$ 执行某个操作,其结果等同于对原始数据 $x$ 和 $y$ 执行操作后再编码的结果
最简单的例子就是异或:$f(x)=x⊕k$
attack
同态编码比较难破解,可以采用黑盒方式
固定y,然后输入x=1, 2, 3...,观察输出,通过多轮测试和归纳,可以猜出原始操作
不过编码混淆的基础就是不容易猜出函数,所以真的很难破解啊
控制流混淆
控制流混淆(Control Flow Obfuscation,CFO)的目标是打破静态分析工具对程序执行流程的假设
静态代码分析工具通常依赖以下假设:
CALL指令只用于函数调用CALL会返回到紧随其后的下一条指令RET指令代表函数的边界和返回- 条件跳转的两侧分支均可能被执行,且分支目标都是代码而非数据
- 间接跳转的目标是容易确定的(例如
switch结构或函数指针)
CFO的所有技术都是为了打破上述一个或多个假设,给分析器制造麻烦
插入无效代码(花指令)
这是最常见的混淆手段之一,分为死代码和垃圾代码
CTFwiki :
“花指令(junk code)是一种专门用来迷惑反编译器的指令片段,这些指令片段不会影响程序的原有功能,但会使得反汇编器的结果出现偏差,从而使破解者分析失败。比较经典的花指令技巧有利用 jmp 、call、ret 指令改变执行流,从而使得反汇编器解析出与运行时不相符的错误代码”
死代码
defend
死代码是指那些会被执行、但其执行结果对程序的最终状态没有任何影响的指令
这侧重于数据混淆
为了插入死代码,混淆器需要进行活跃变量分析(这是静态分析的内容),找出在某个程序点上哪些寄存器或变量是死的,也就是即它们的值在被再次赋值前不会被使用,然后插入修改这些死寄存器的指令
int f() {
int x, y;
x = 1; // <-- 死代码, x 的值在被使用前就被第3行覆盖了
y = 2; // <-- 死代码, y 从未被使用
x = 3; // <-- x 在此变为“活”的
return x;
}
attack
既然他们能用活跃变量分析插入死代码,那么攻击者也可以同样利用活跃变量分析去除死代码
以上面的例子来说,大部分静态分析工具可以计算出在x = 1之后,x在被x = 3覆盖之前从未被读取过,因此 x=1是死代码,可以安全移除,或标记为死代码
垃圾代码
defend
垃圾代码是指那些永远不会被执行到的代码块,侧重于控制流混淆
之前说过,静态分析工具会假设条件跳转的两侧分支均可能被执行,插入垃圾代码就会大大增加负担
eg1:简单的无条件跳转
JMP real_code
; --- 垃圾代码开始 ---
ADD EAX, 1
XOR EBX, EBX
PUSH EAX
; --- 垃圾代码结束 ---
real_code:
POP EAX ; 有效代码
eg2:伪装的条件跳转
通过数据混淆,将无条件跳转伪装成条件跳转
PUSH EAX ; 保存 EAX
XOR EAX, EAX ; EAX = 0, 同时设置 ZF = 1
JZ real_code ; ZF 永远为 1,所以这条 JZ 永远会跳转
; --- 垃圾代码开始 ---
MOV EAX, 0xDEADBEEF
CALL some_func
; --- 垃圾代码结束 ---
real_code:
POP EAX ; 恢复 EAX
eg3:无效的条件跳转
JZ target_1 ;
JMP target_2 ;
target_1:
NOP ; target_1 只是一个空指令
target_2:
; --- 真正的有效代码 ---
静态分析器可能会认为target_1和target_2都是有效的分支,但实际上target_1什么用也没有
eg4:反汇编去同步
这是一种高级的垃圾代码插入技术,它利用了反汇编器和 CPU实际执行之间的差异
它会在一个JMP指令后,插入一些看起来像指令、但实际上是数据的字节:
start:
jmp real_code ; 直接跳过下面这串“数据”
db 0x55, 0x8B, 0xEC, 0x83, 0xEC, 0x10
; 看上去像标准 prologue + 写入 0xDEADBEEF
real_code:
; 真正执行的代码从这里开始
mov eax, 1
ret
如果是线性扫描式反汇编(从某个起点地址开始,按地址递增顺序一条条解码指令),就会把db的这串数据解码,而这串数据的意义刚好是:
55 push ebp
8B EC mov ebp, esp
83 EC 10 sub esp, 0x10
这就是一个函数前言,而许多反汇编器和函数识别器会用前言/后言模式来猜测“这里是不是函数的开头”
一旦在线扫过程中遇到类似55 8B EC的序列,就倾向于标记为函数起点,并继续把后面字节当代码解下去,这就掉进陷阱了
attack
他们欺骗了静态分析器,关我动态分析什么事?
攻击者可以利用二进制插桩工具来追踪程序的实际执行路径,运行程序后,所有从未被执行到的代码块都可以被认为是垃圾代码
这种方法需要尽可能多样的数据输入,来避免有所遗漏,所以也不是很有效,比较通常的还是人工分析
不透明谓词
这是插入垃圾代码的升级版
不透明谓词是一种特殊的条件表达式,其结果在混淆时是确定的,但对于静态分析器来说却非常难推导
- $P^T$:一个永远为True的不透明谓词
- $P^F$:一个永远为False的不透明谓词
通过使用不透明谓词作为分支条件,混淆器可以向程序的控制流图(CFG)中插入伪分支
eg:
原始代码:
Block A
Block B
使用 $P^T$ 混淆后:
Block A
IF (P^T)
GOTO Block B
ELSE
GOTO Block_B_Buggy ; 这是一个包含垃圾代码的伪造块
分析器会看到两个分支,但实际上只有Block B永远会被执行,以此增加分析的负担
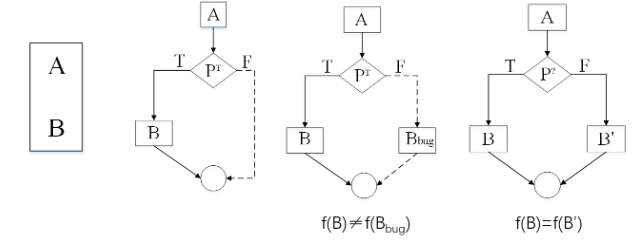
基于数学的谓词
defend
这种方法的核心是利用一个数学恒等式或数论属性来构造一个条件表达式
这个表达式在混淆时被设计为永远为真 ($P^T$) 或永远为假 ($P^F$),但其形式对于静态分析器或人类分析师来说并不直观
一个简单的$P^T$:
if ((x * x) >= 0)
任何实整数的平方永远大于等于零,这对于分析器来说比较容易识别
一个高级的$P^T$:
if ((7 * x * x - 1) % 3 != 0)
x * 2总是偶数,偶数 + 1总是奇数,任何奇数对2取模永远不等于0
attack
可以使用SMT(satisfiability modulo theories,模理论可满足性)求解器,比如大名鼎鼎的Z3,将谓词喂进去,并询问是否存在一个x,使得该表达式为False,如果Z3回答不可满足,则证明该谓词是 $P^T$
也可以在调试器中,使用不同的输入运行代码成千上万次,如果if语句的True分支每次都被命中,而False分支被命中了0次,那么它有极高的概率是一个$P^T$,这种方法被称为动态探测,是更为廉价暴力的手段
基于环境的谓词
defend
这种方法的核心是谓词的结果不依赖于程序内部的计算,而是依赖于外部环境的一个恒定状态
eg:
if (GetModuleHandleA("kernel32.dll") != NULL)
kernel32.dll是所有Windows用户模式进程的基础核心库,它必然已经被加载到进程空间中,因此,这个 API 调用永远不会返回NULL,也就是说这个谓词在任何Windows进程中都是$P^T$
而静态分析器不知道GetModuleHandleA的返回值,它必须假设这个API既可能成功也可能失败,这会迫使分析器在控制流图中保留两个分支,而False分支会是永远不会被执行的垃圾代码
attack
可以使用hook或者patch来拦截这个API调用,当检测到输入是"kernel32.dll"时,强行修改其返回值为NULL
或者根据经验判断,通过谓词签名库匹配固定的环境谓词模式,然后标记它
基于指针别名的谓词
defend
这种方法的核心是利用指针别名(即两个或多个不同的指针变量指向了同一块内存地址)来构造谓词
比如现在有一个$P^T$:
if (p == q)
混淆器会通过两条表面上完全不同、但结果相同的复杂计算路径来分别初始化p和q:
int arr[20];
int* p = &arr[10]; (路径1)
int* q = &arr[0]; (路径2 开始)
// ... (插入 50 行垃圾指令) ...
q = q + 5; (路径2 继续)
// ... (插入 50 行垃圾指令) ...
q = q + 5; (路径2 结束)
if (p == q) { ... } (恒为真)
静态分析器很难在数百行垃圾指令的干扰下,静态地跟踪q的值并推导出&arr[0] + 5 + 5等于&arr[10]
因此,它必须假设p == q和p != q两种情况都可能发生
attack
使用代码切片技术,从if (p == q)开始向上回溯代码,只提取那些对p或q的值有影响的指令:
p的切片可能是:mov eax, OFFSET arr; add eax, 40; mov p, eaxq的切片可能是:mov ebx, OFFSET arr; add ebx, 20; add ebx, 20; mov q, ebx
结果就是所有的垃圾指令都被过滤掉了,通过这个简化的切片,可以轻而易举地看出p和q相等
另外,就上例来说,静态分析工具也可以将arr的基址看做是一个符号,然后顺着指令分析,但不做运算,得到最后的表达式,再喂给SMT求解器他们结果是否相等
破坏代码局部性
defend
跳转重排
通过向基本块中引入无意义的JMP指令,将原本在逻辑上和物理上都连续的代码块打散,破坏其局部性
eg:
原始代码:
start:
push offset caption
push 0
push offset digtxt
call MessageBoxA
...
混淆后:
start:
push 0
jmp instr_1
instr_2:
call MessageBoxA
jmp instr_5
instr_3:
push 0
jmp instr_2
instr_4:
push offset digtxt
jmp instr_3
instr_1:
push offset caption
jmp instr_4
instr_5:
...
函数内联与外联
函数内联 (Inlining):
将子函数$P$的代码直接合并到调用者$Q$的代码中,如果$P$被多次调用,会导致代码体积显著膨胀
函数外联 (Outlining):
将函数$Q$中任意一段代码(特别是逻辑上不相关的部分)提取出来,构成一个新的函数$R$,然后在$Q$的原位置替换为一个CALL R
基本块重排
将一个函数的所有基本块打乱,并在物理上随机散布到程序的.text段中,甚至插入到其他函数的缝隙中,然后通过JMP将它们重新链接起来
函数克隆
复制一个函数$f$,得到 $f’$,他们的的功能完全一样,但可能使用了不同的指令模板(也就是基于模式的混淆)
混淆器将程序中一半对$f$的调用替换为对 $f’$的调用,迫使攻击者浪费一倍的时间去分析两个不同的函数,最后才发现它们是等价的
attack
实际上,破坏代码局部性只能对人工分析造成较大阻碍
分析工具都不应该关心基本块的物理位置,只应该关心它们之间的逻辑关系,通过跟随这些跳转,可以100%还原出原始的控制流图,这就让前面三种混淆完全无效了,相信用过IDA的一定能体会到这种图的便利
而对抗函数克隆,可以使用模糊哈希,这些工具比较两个函数的的CFG结构、常量、API调用等,如果相似度极高,就可以判定它们是克隆函数
控制流间接化
defend
使用动态计算的分支地址,或者模拟JMP和CALL指令,来隐藏真实的控制流
eg1:使用RET模拟JMP
JMP <target>可以被等价替换为:
PUSH <target> ;
RET ;
这会打破静态分析器“RET代表函数返回”的假设
eg::使用CALL模拟JMP
CALL real_code ;
; --- 垃圾代码 ---
...
real_code:
ADD ESP, 4 ;
; --- 真正的有效代码 ---
这里的CALL只是起到了PUSH <返回地址>和JMP real_code的作用
而real_code开头的ADD ESP, 4则抛弃了压入栈的返回地址(垃圾代码的地址),从而实现了JMP的效果
eg3:修改栈上的返回地址
CALL FunctionA ;
original_ret_addr:
; --- 垃圾代码 ---
actual_ret_addr:
NOP ;
; --- 真正的有效代码 ---
...
FunctionA:
; 假设垃圾代码长度为 9 字节
ADD DWORD PTR [ESP], 9 ; 关键!修改栈顶的返回地址
RET ;
CALL FunctionA时,压入栈的返回地址是original_ret_addr,但FunctionA内部通过[ESP](即指向返回地址的指针)修改了它,将其改为了actual_ret_addr
其实也就是上一种的变种
attack
对于PUSH <target>; RET,IDA等现代工具已经可以很好地识别
它们会分析RET指令时ESP指向的值,如果它不是一个CALL指令的返回地址,而是一个PUSH压入的常量,IDA会自动将其标记为JMP(显示为retn_0并添加注释)
控制流图扁平化
defend
这是最复杂的控制流混淆技术之一
它将一个函数内所有控制结构(如 if-else、while、for)全部“拍平”,用一个单一的分发器结构来替代
分发器:这通常是一个巨大的switch结构
状态变量:引入一个 swVar 变量
代码块拆分:原始函数的所有基本块被拆分,并放入switch的不同case中
每个基本块的末尾不再是JMP或JZ,而是负责更新swVar,将其设置为下一个应该执行的基本块的 ID
eg:
原始代码:
int a=1, b=2;
while (a < 10) {
b = a + b;
if (b > 10) {
a++;
} else {
b--;
}
}
use(b);
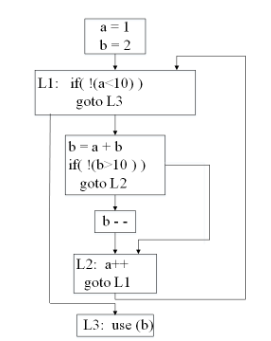
CFG扁平化混淆后 (伪代码):
int a, b;
int swVar = 1; // 状态变量,初始为 1
goto dispatcher;
dispatcher:
switch (swVar) {
case 1: // 对应原始的 S1
a = 1;
b = 2;
swVar = 2; // 下一个去 S2
goto dispatcher;
case 2: // 对应原始的 S2 (while)
if (!(a < 10))
swVar = 6; // (while 循环结束,去 S6)
else
swVar = 3; // (while 循环体,去 S3)
goto dispatcher;
case 3: // 对应原始的 S3
b = b + a;
if (!(b > 10))
swVar = 5; // (if 为 false,去 S5)
else
swVar = 4; // (if 为 true,去 S4)
goto dispatcher;
case 4: // 对应原始的 S4 (if-true)
a++;
swVar = 2; // 回到 S2 (while 头部)
goto dispatcher;
case 5: // 对应原始的 S5 (if-false)
b--;
swVar = 2; // 回到 S2 (while 头部)
goto dispatcher;
case 6: // 对应原始的 S6 (use(b))
use(b);
break; // 结束
}
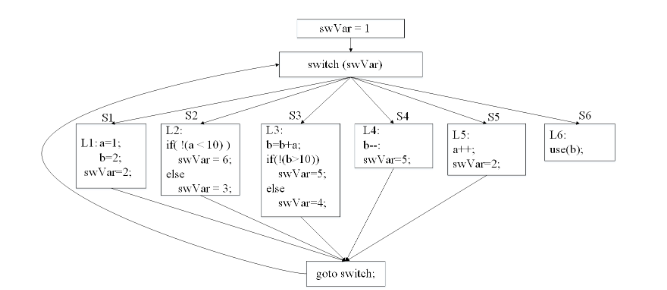
这种混淆彻底摧毁了原始的while和if逻辑结构,静态分析器和攻击者只能看到一堆基本块和一个switch,基本块之间的逻辑关系被隐藏在对swVar的控制操作中
更有甚者,swVar的更新不再是简单的赋值,它可能是一个复杂的MBA表达式,例如:
swVar = ((swVar_old * 0xABCDEF) + 0x123456) ^ 0xDEADBEEF
同时,case标签也不是1,2,3...,而是0xABC, 0xDEF, 0x123...,这使得分析师必须先逆向出状态转换函数,才能重建CFG
attack
进行静态CFG重建:
- 定位分发器
switch和状态变量swVar - 分析每个
case块 - 忽略块内的所有业务逻辑,只看块末尾对
swVar的写入 case 3:…swVar = 4;这条指令就是一条从Block 3到Block 4的有向边case 2:…if (cond) swVar = 6; else swVar = 3;这是从Block 2出发的两条边,分别指向Block 6和Block 3
通过这个方法,可以100%自动化地重建原始的CFG