取证常考知识点,不得不品的一环啊
如果对磁盘存储这些的概念不是很熟悉,建议看看:磁盘相关的东西
参考资料:
什么是RAID
RAID,全称Redundant Array of Independent Disks,独立磁盘冗余阵列是一种将多个独立的物理磁盘驱动器组合成一个逻辑单元的存储技术
对于操作系统而言,这个由多块磁盘组成的RAID阵列看起来就像一个单一的大容量硬盘
那么,RAID技术有什么好的?
-
数据容错
因为在多个磁盘上有存储数据的副本或校验信息,RAID可以有效防止因单块磁盘故障而导致的数据丢失
当一块磁盘损坏时,系统可以利用其余磁盘上的冗余数据进行恢复,这抵御故障并继续运行
-
性能提升
通过将数据分割成小块并同时读写到多个磁盘上,数据传输速率高,读写性能远超单个磁盘
这种方式也被称为条带化存储,每个条带包含一段连续的数据,同一条逻辑行的数据块分布在不同磁盘上
条带这个东西不太好用文字理解,举个例子
假设有两块硬盘DiskA、DiskB,要存储的数据是字符串
ABCDEFGH:未条带化(普通存储):
- DiskA:
ABCDEFGH - DiskB:空
读取的时候只能A读,B不工作
条带化存储(条带大小2字节):
条带号 DiskA DiskB 1 A B 2 C D 3 E F 4 G H 也就是说第一个条带=
A(DiskA) +B(DiskB),大小就是AB(两个字节),后面的也以此类推同一个条带的上下两部分数据存储在了AB两块磁盘的同一个位置
每次读取数据时,按照条带来读,无需切换硬盘,和普通的两个盘分别存储有本质区别
这样读取的时候两块盘可以同时工作,速度几乎翻倍!这就是最简单的RAID0的工作原理
- DiskA:
RAID级别
ok啊,终于进入正题了
根据不同的数据组织方式和冗余策略,形成有不同的RAID级别
找资料的时候看见一张特好玩的图:

等看完下面的内容就懂了,虽然不太准确,但还是挺形象的hhh
图里前三个并不是RAID的概念,而是数据存取/服务部署的概念,最好了解一下
-
Standalone(单机部署/单盘存取)
只能从一块硬盘获取数据,如果硬盘挂掉,那么数据就不可用
对于服务,则是只把服务部署在一个主机,服务坏了就坏了
-
Hotswap(热插拔)
热插拔是指在系统运行过程中,可以直接插入或拔出硬件设备,而不需要关机或重启系统
而**热备技术(HotSpare,简称HS)**就是依靠它实现:一块硬盘工作,另一块硬盘作为热备,当主盘故障时系统自动切换到备用盘
服务部署也是同理,以一个服务作为热备,随时顶替
-
Cluster(集群)
同一数据存储在多个硬盘里/同一服务部署在多台主机上,形成集群,一个坏了另一个还能用
和HS不一样的是会切换硬盘/主机
嗯,图里的这种幽默也由此可见一斑了
RAID0:条带化
2个以上硬盘并联
将数据分块,无冗余地并行写入阵列中的所有磁盘,空间利用率高高的,就是磁盘本身的容量
读写性能极高,是所有RAID级别中理论速度最快的
但也因为没有任何数据冗余,任何一块磁盘损坏都会导致所有数据的丢失

RAID1:镜像
将数据完整地复制到另一块或多块磁盘上,形成互为镜像的副本,提供了很高的数据安全性
但其磁盘空间利用率只有一半,并且写入性能相比单盘没有提升(没有使用条带化),是比较不行的冗余方式

RAID2:位级条带化+汉明码校验
在位级别上对数据进行条带化,并使用专门的磁盘存储汉明码进行错误校验,实时纠正单位数据错误
这种方式实现复杂,可用空间是(N-P)*S,其中N是总盘数,P是校验盘数,S是盘容量
校验盘的数量P与数据盘的数量有关,关系有点复杂,就不展开了
随着现代硬盘自带纠错功能,该级别已被市场淘汰了

RAID3:块级条带化+专用校验盘
在字节级别上进行数据条带化,使用一块专用的磁盘来存储所有数据的奇偶校验信息,可用空间是(N-1)*S
至少使用三块硬盘,如果只有两块就和RAID1一样了
由于数据按字节分布在所有数据盘上,任何读写操作都需要所有磁盘协同工作,这使其不适合处理大量随机的小型读写请求,适合大块连续数据的读写,例如未压缩视频编辑
但由于所有校验操作都集中在一块专用盘上,导致高并发随机写入的性能被大幅限制,因此也已很少使用

RAID4:块级条带化+专用校验盘
在块级别上对数据进行条带化,并同样使用一块专用磁盘存储奇偶校验信息,所以可用空间也是(N-1)*S
至少使用三块盘,理由和RAID3一样
相比RAID3,改善了小文件的读取性能,因为读取请求可以由单个数据盘独立完成
但写入操作时,这块专用的校验盘依然制约了性能,核心问题并未得到解决

RAID5:分布式奇偶校验
在块级别上条带化数据,将奇偶校验信息交错地分布到所有磁盘上,性能、容量和安全性之间有很好的平衡
因为奇偶校验信息占据的空间刚好是一块盘,所以可用空间也是(N-1)*S
至少使用三块硬盘,如果只有两块的话就无法存储完整的条带信息了
它可以在单块磁盘损坏时不丢失数据,因为后续的读取可以通过阵列中剩余的数据和奇偶校验块计算出来
但由于奇偶校验计算是在整个条带上进行的,其每个写入操作都需要重新计算校验值,性能会有一定损失

由于RAID5是非常常用的类型,也是电子取证重点考察的部分,我们重点讲一下它
RAID5的核心在于其校验数据的分布式存储,其校验原理基于异或运算(XOR,用符号^代指)
例如,RAID5存储方式下有A1, A2, A3三个数据块,其校验块Ap的计算方式为Ap = A1 ^ A2 ^ A3,如果其中一个数据块(如A2)丢失,可以通过A2 = A1 ^ A3 ^ Ap来恢复
而校验块在磁盘间的分布规律,即所谓“循环方式”,是重组中最关键的一环
它由两个东西决定:循环方向和同步性(对称性)
循环方向
决定RAID5每条条带的奇偶校验块(P)在不同磁盘上的分布方式
左循环
校验块P0, P1, P2...从阵列的最后一个盘开始,从右向左依次移动
| 条带号 | Disk0 | Disk1 | Disk2 | Disk3 |
|---|---|---|---|---|
| 0 | P0 | |||
| 1 | P1 | |||
| 2 | P2 | |||
| 3 | P3 | |||
| 4 | P4 | |||
| 5 | P5 |
右循环
校验块P0, P1, P2...从阵列的第一个盘开始,从左向右依次移动
| 条带号 | Disk0 | Disk1 | Disk2 | Disk3 |
|---|---|---|---|---|
| 0 | P0 | |||
| 1 | P1 | |||
| 2 | P2 | |||
| 3 | P3 | |||
| 4 | P4 | |||
| 5 | P5 |
同步性(对称性)
决定写数据和校验时,磁盘是否按固定顺序同时参与写入
下面内容我们默认使用左循环的方式,填入D0~D8这九个数据块
异步(不对称)
下一个数据条带的起始数据块总是从0号盘开始写入,不考虑上一行校验块的位置
| 条带号 | Disk0 | Disk1 | Disk2 | Disk3 |
|---|---|---|---|---|
| 0 | D0 | D1 | D2 | P0 |
| 1 | D3 | D4 | P1 | D5 |
| 2 | D6 | P2 | D7 | D8 |
| 3 | P3 | |||
| 4 | P4 | |||
| 5 | P5 |
其实就是每行从0依次由低到高填入
同步(对称)
下一个数据条带的起始数据块紧跟在当前条带校验块所在的磁盘之后,如果校验块在最后一个盘,则起始数据块回到0号盘
| 条带号 | Disk0 | Disk1 | Disk2 | Disk3 |
|---|---|---|---|---|
| 0 | D0 | D1 | D2 | P0 |
| 1 | D4 | D5 | P1 | D3 |
| 2 | D8 | P2 | D6 | D7 |
| 3 | P3 | |||
| 4 | P4 | |||
| 5 | P5 |
先判断下一个条带的校验块位于哪个磁盘,然后将数据写入校验块所在的磁盘的下一个磁盘
之后向高号盘写入,直至该条带内编号最大的数据块写满后,再回到同条带内的0号盘写入,直至写满条带
比如条带三,因为校验块是Disk1,数据写入顺序就是D6(Disk2)-> D7(Disk3)-> D8(Disk0)
至此,我们就掌握了完整的RAID5写入标准数据与校验数据的方式
RAID6:双分布式奇偶校验
在RAID5的基础上增加了第二个独立的校验块,并将两种校验信息都交错分布在所有磁盘上
有两组独立的校验信息,占用的总空间等于两块磁盘的容量,所以可用空间是(N-2)*S
至少需要4块磁盘,可以容忍两块磁盘同时损坏
但也因为要进行两次校验计算,RAID6的写入性能,尤其是小数据块的随机写入,通常低于RAID5

RAID10 (1+0)
先将磁盘两两配对做RAID1(镜像),然后再将这些镜像对组合成一个RAID0(条带化)
兼具RAID1的高可靠性和RAID0的高性能,只要每个镜像对中至少有一块磁盘正常,数据就不会丢失
但成本高,且磁盘利用率和RAID1一样,只有50%
eg:
| 条带号 | Disk0 | Disk1 | Disk2 | Disk3 |
|---|---|---|---|---|
| 1 | D0 | D0 | D1 | D1 |
| 2 | D2 | D2 | D3 | D3 |
Disk0/1是镜像组1,Disk2/3是镜像组2
使用RAID0对镜像组条带化后,多组镜像同时读写
RAID50 (5+0)
先将磁盘分组构建多个RAID5阵列,再将这些RAID5阵列组合成一个RAID0
每个子RAID5组都允许坏一块盘,提供了比单个RAID5更高的性能和更好的容错能力
可用空间是K*(M-1)*S,K是RAID5子阵列的数量,M是每个子阵列中的磁盘数量
eg:
| 条带号 | Disk0 | Disk1 | Disk2 | Disk3 | Disk4 | Disk5 |
|---|---|---|---|---|---|---|
| 1 | D0 | D1 | P0 | D3 | D4 | P1 |
| 2 | D5 | P2 | D6 | D7 | P3 | D8 |
前3块盘是RAID5组1,后3块盘是RAID5组2
RAID0跨两组条带化后,多组并行,提高性能
RAID60 (6+0)
先将磁盘分组构建多个RAID6阵列,再将这些RAID6阵列组合成一个RAID0
每个子RAID6组都允许坏两块盘,提供了极高的性能和顶级的容错能力
可用空间是K*(M-2)*S
eg:
| 条带号 | Disk0 | Disk1 | Disk2 | Disk3 | Disk4 | Disk5 | Disk6 | Disk7 |
|---|---|---|---|---|---|---|---|---|
| 1 | D0 | D1 | P0 | Q0 | D4 | D5 | P1 | Q1 |
| 2 | D2 | P2 | Q2 | D3 | D6 | P3 | Q3 | D7 |
每组4块盘,RAID0跨两组条带化,提升性能
上面三种方式和RAID0组合都是为了在高容错的基础上提高读写效率
RAID的实现模式
软件RAID
所有数据和校验运算都由CPU负责,成本低廉,无需额外硬件,但会占用CPU资源,影响系统性能
例如操作系统内置的RAID功能,或者主板芯片组提供的RAID功能,都是软件RAID
不过主板损坏后,可能难以找到同款主板来重建RAID
硬件RAID
通过一块专用的RAID控制器卡来实现,该卡上有自己的处理器(称作ROC, RAID-on-Chip)、缓存和BIOS,独立处理所有RAID运算,对主CPU透明
性能高,不占用主机CPU资源,通常有缓存和备用电池以防掉电数据丢失,可靠性高,易于迁移,但成本较高
RAID重组
选几个
2023美亚
检材给了三个镜像:
USF
这个工具强到离谱,速度快而且非常自动化,非常推荐使用
自动重组
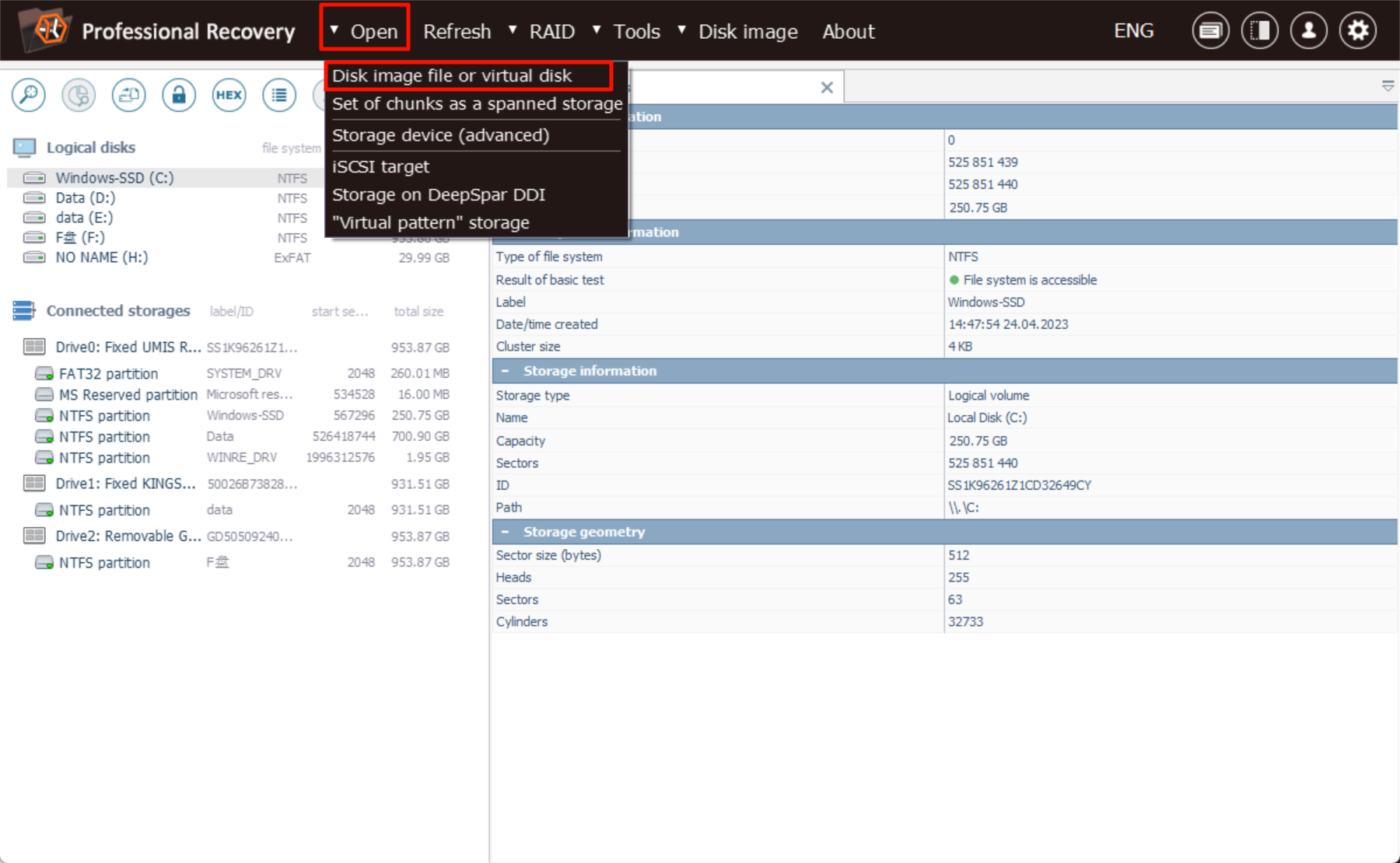
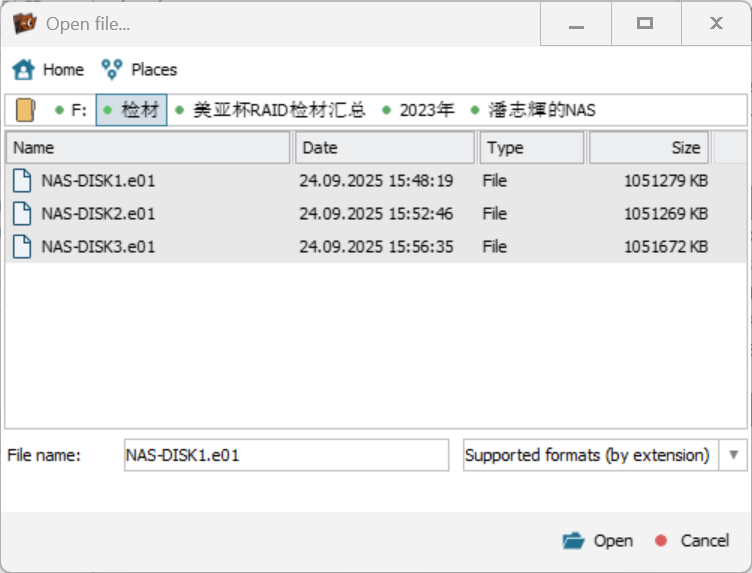
打开三个镜像:
在左侧显示已经添加后,点击reflash刷新,可以看已经自动重组完成了:

其中三个NAS磁盘都被划分成了一模一样的三个分区:
-
Mirror component (Ext2/3/4) partition
RAID1阵列的组件,用于存放NAS的操作系统
-
SWAP partition
用作Linux系统的交换分区(虚拟内存),在NAS中,这个分区通常也会被设置为一个RAID1阵列
-
RAID5 component partition
RAID5阵列的组件
这三块5.40GB硬盘组成的RAID5阵列,可用容量为(3-1) * 5.40 GB = 10.80 GB,也就是组好的SG7:2的大小
而下面重组完成的卷大小是10GB,非常合理
右键对应的RAID分区,选择查看信息,可以看到具体的RAID情况:
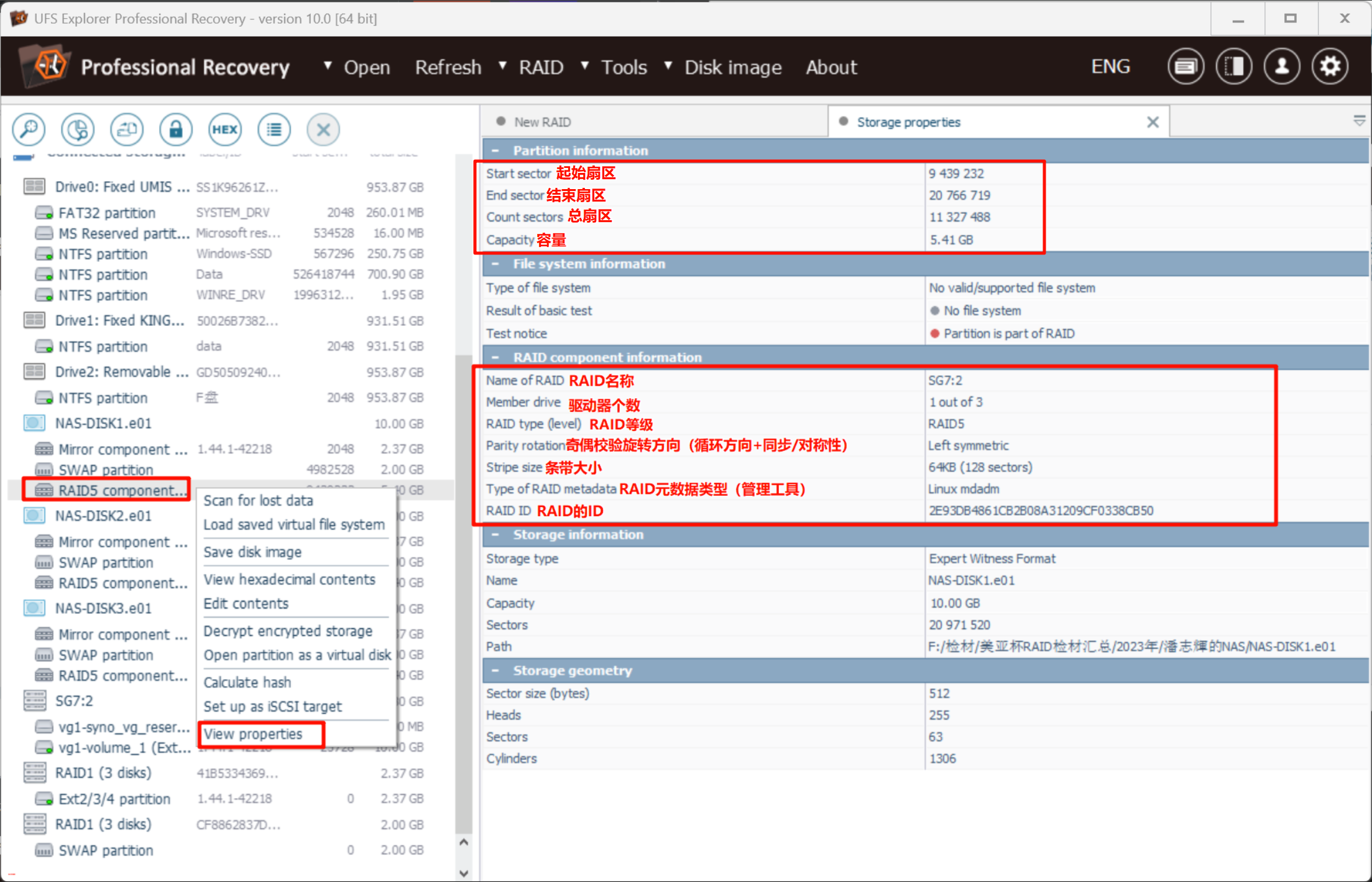
查看重组后的RAID5信息:
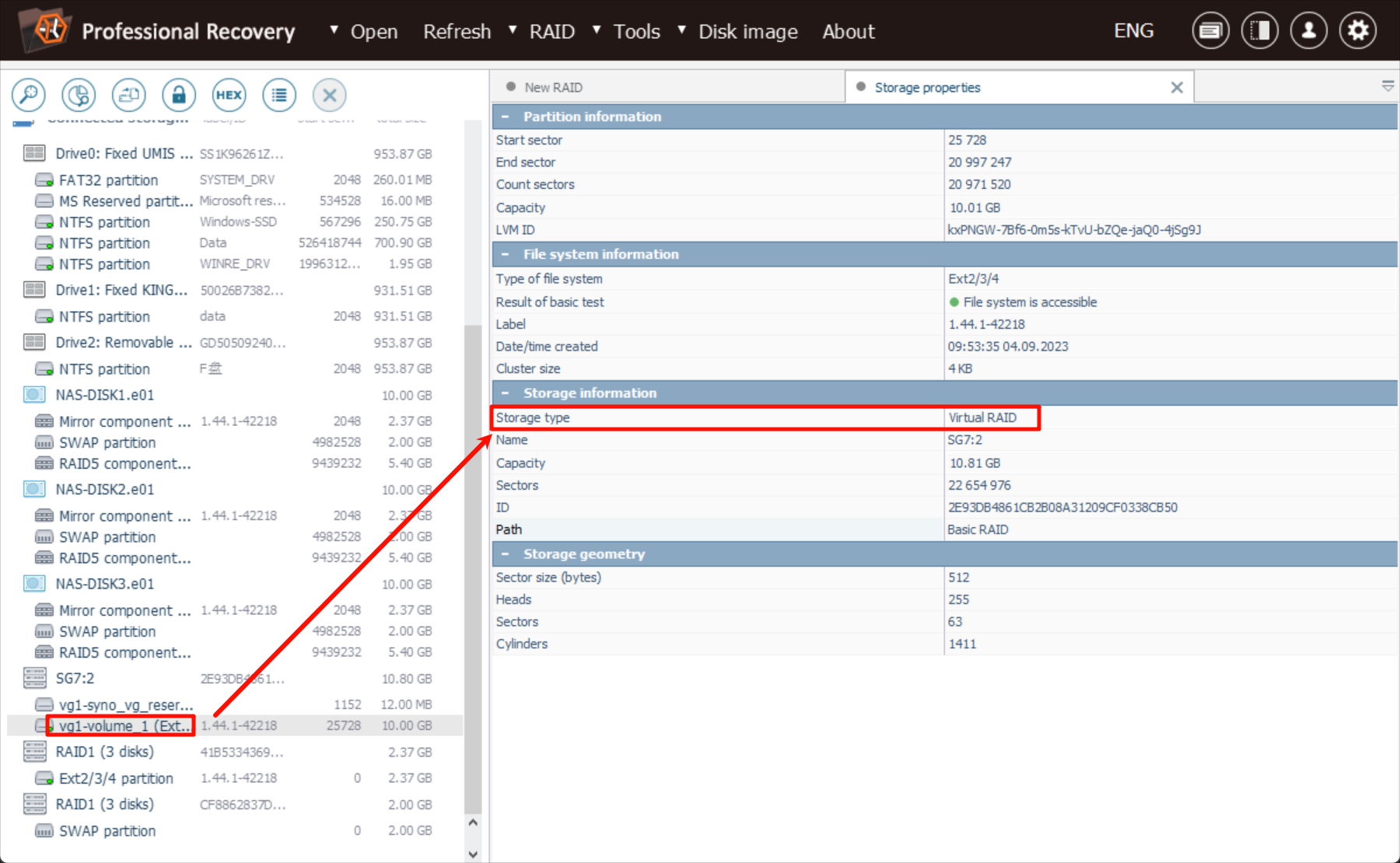
在USF里面也能直接查看文件系统:
手动重组
除了自动分析,也能使用手动分析重组功能:
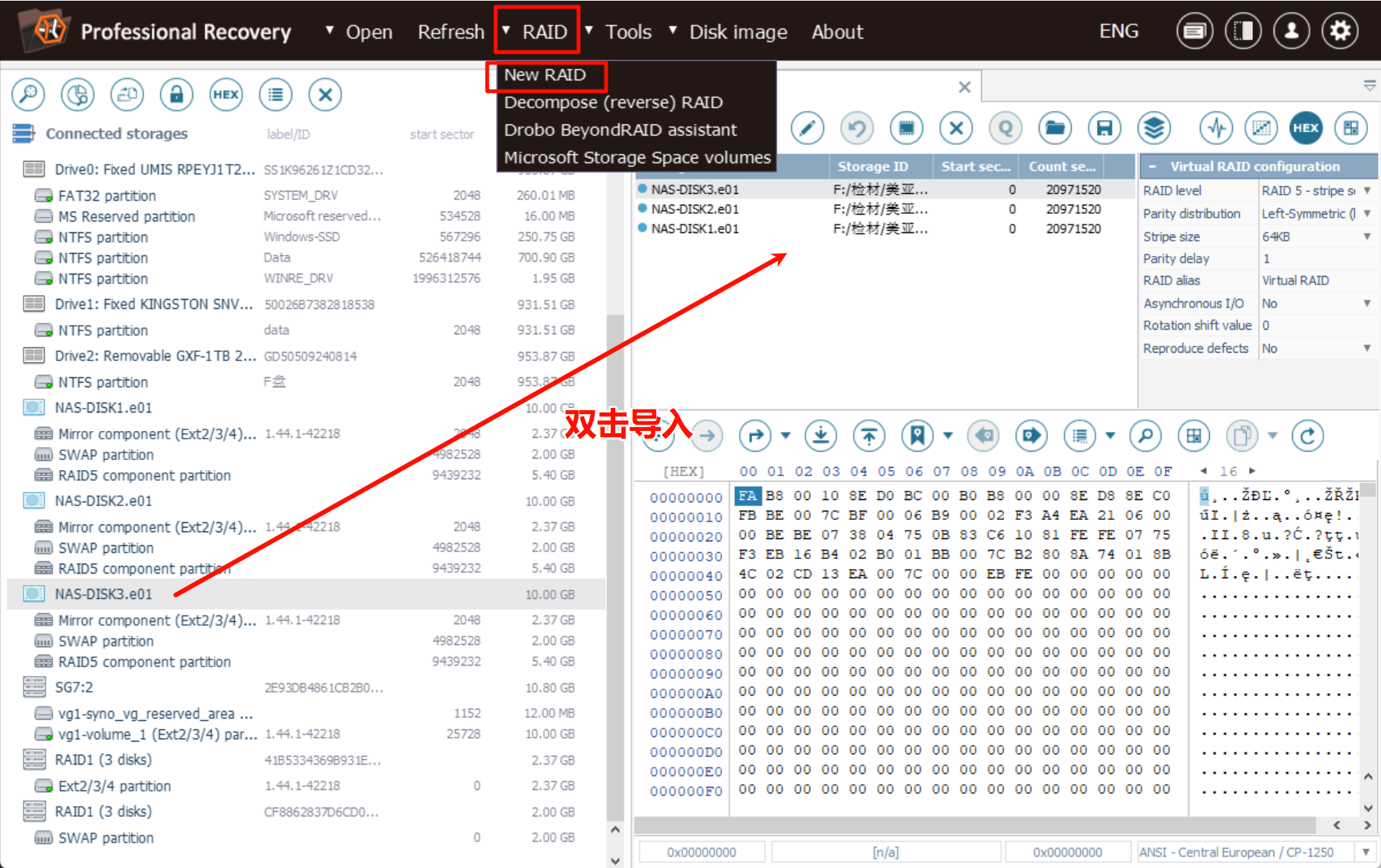
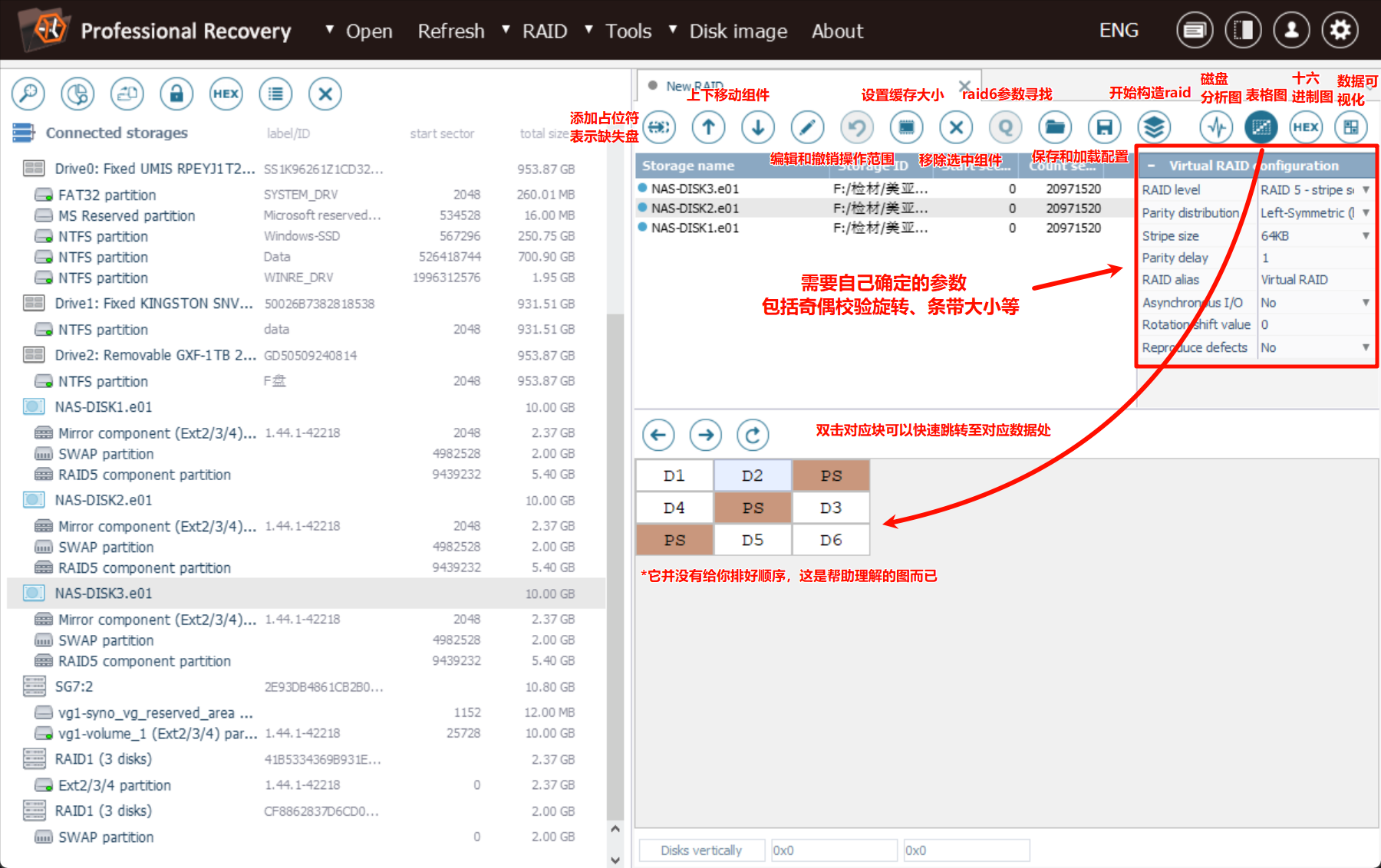
关于手动重组,看这篇文章:Raid重组复习–0xL4k1d
其中步骤有些许复杂,后文就不展开了
导出磁盘
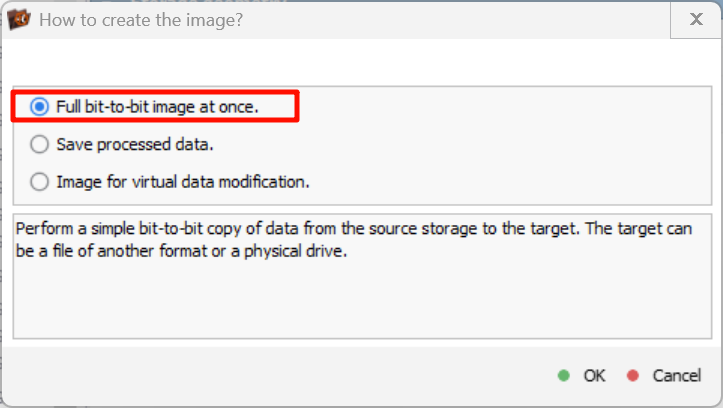
选择一比一复制:
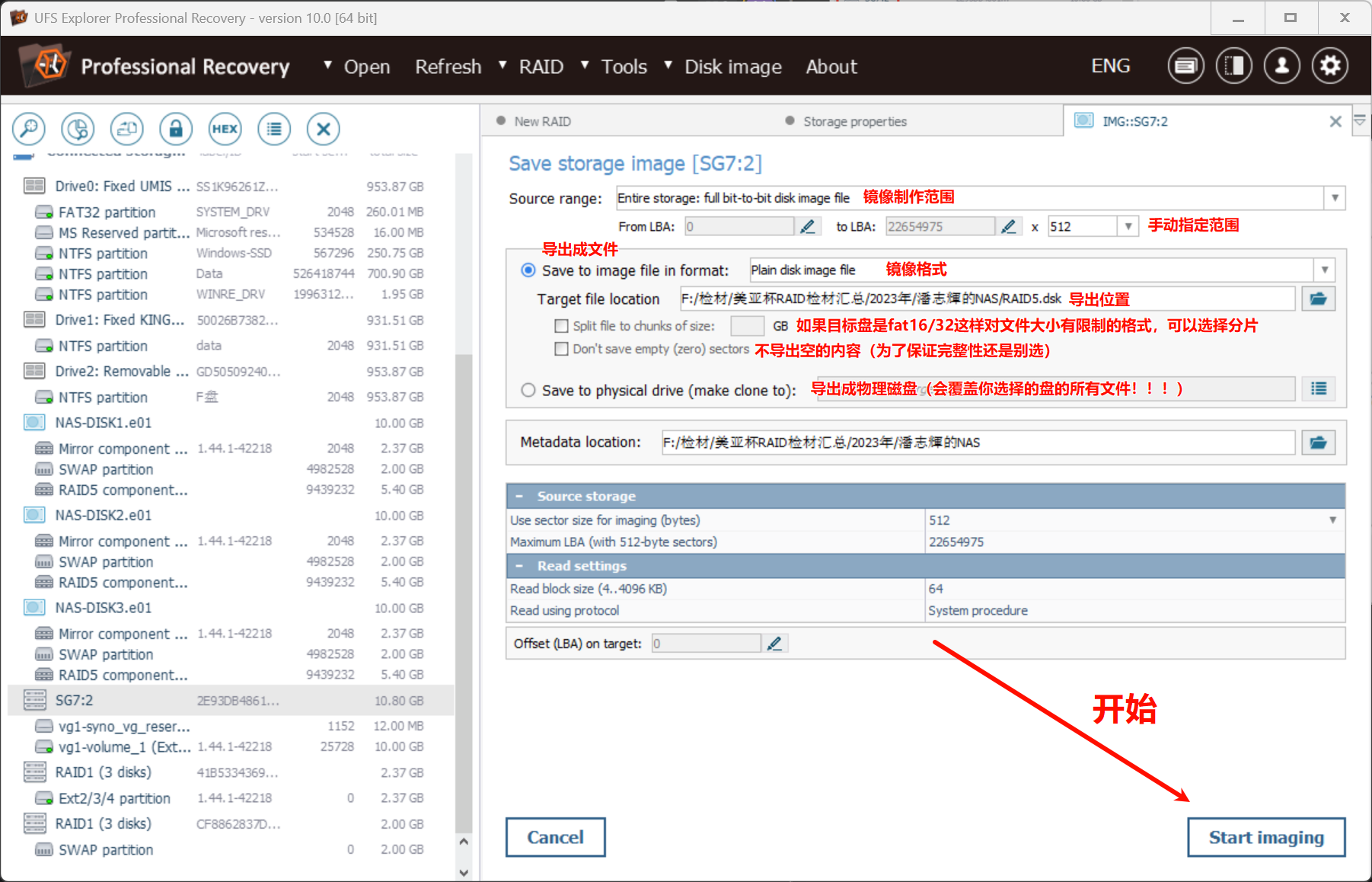
火眼可以正常解析:
但不知道为什么不能进行火眼仿真
美亚计算机取证大师
似乎没有手动的选项,不过能自动是最好了:p
自动重组
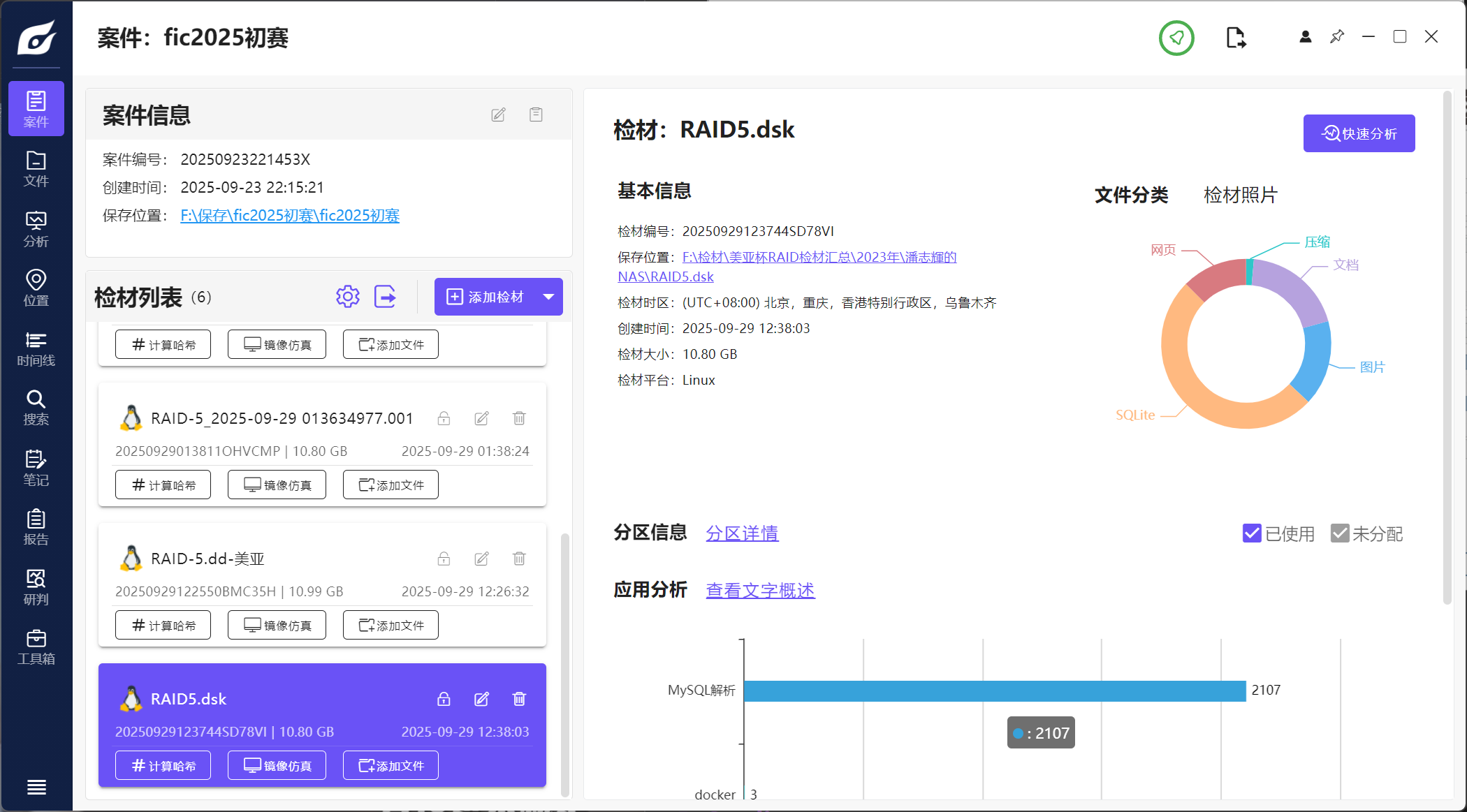
新建案例(注意这里选择添加磁盘镜像进行分析,而不是直接选择RAID重组):
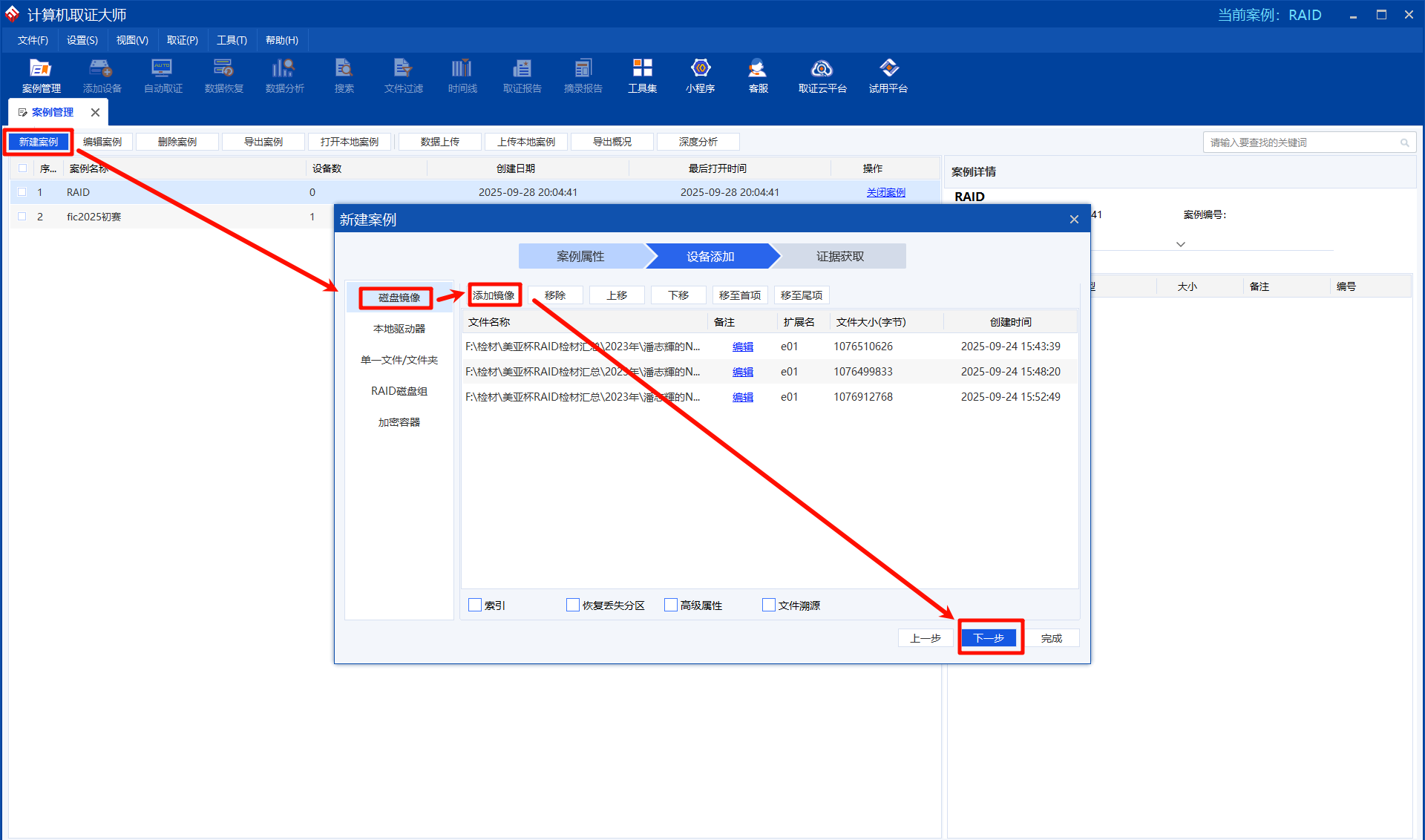
点击下一步后会自动识别出有动态磁盘,选择继续分析:

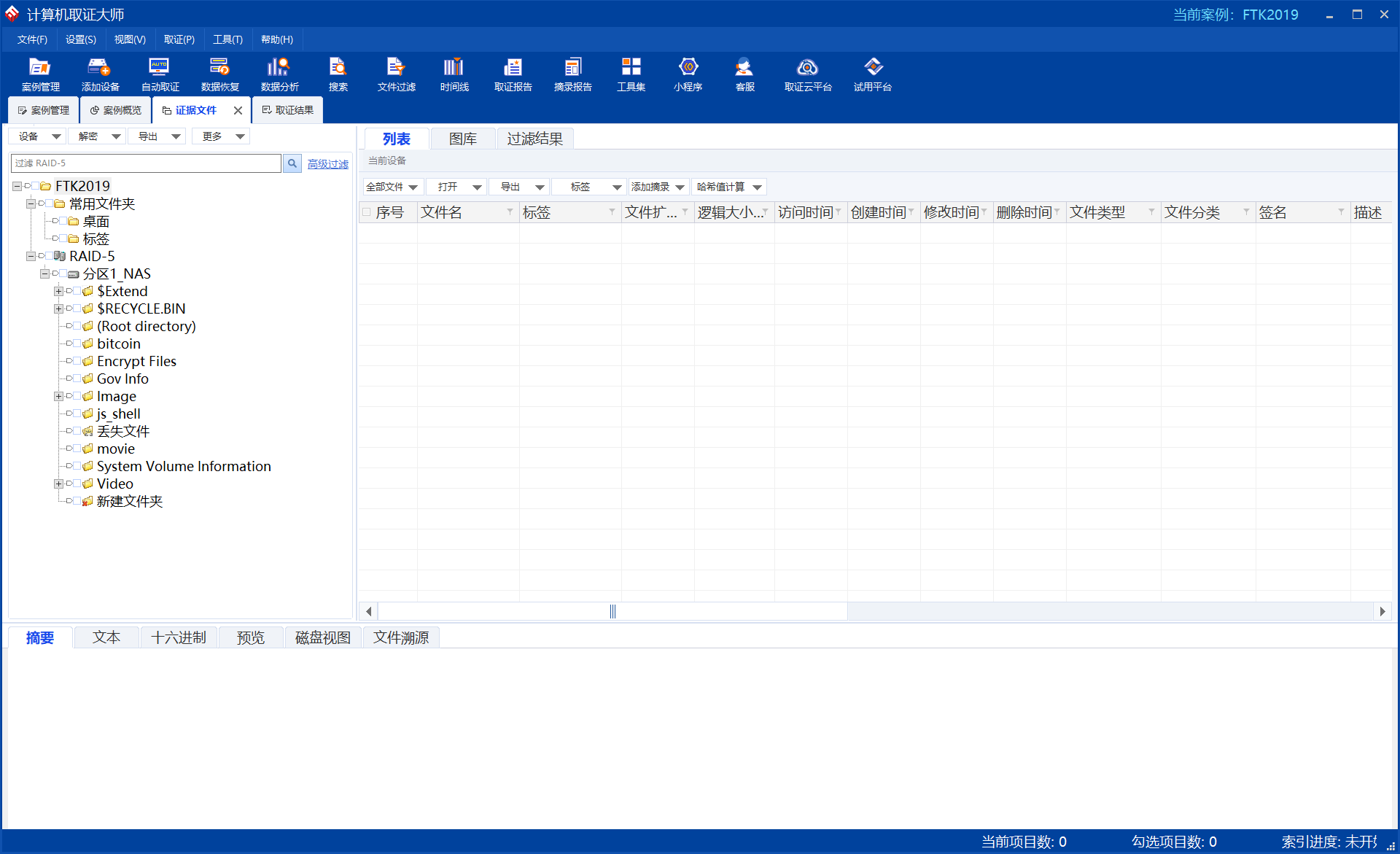
进入案件后,在证据文件这里找到RAID5,已经自动识别出来了:
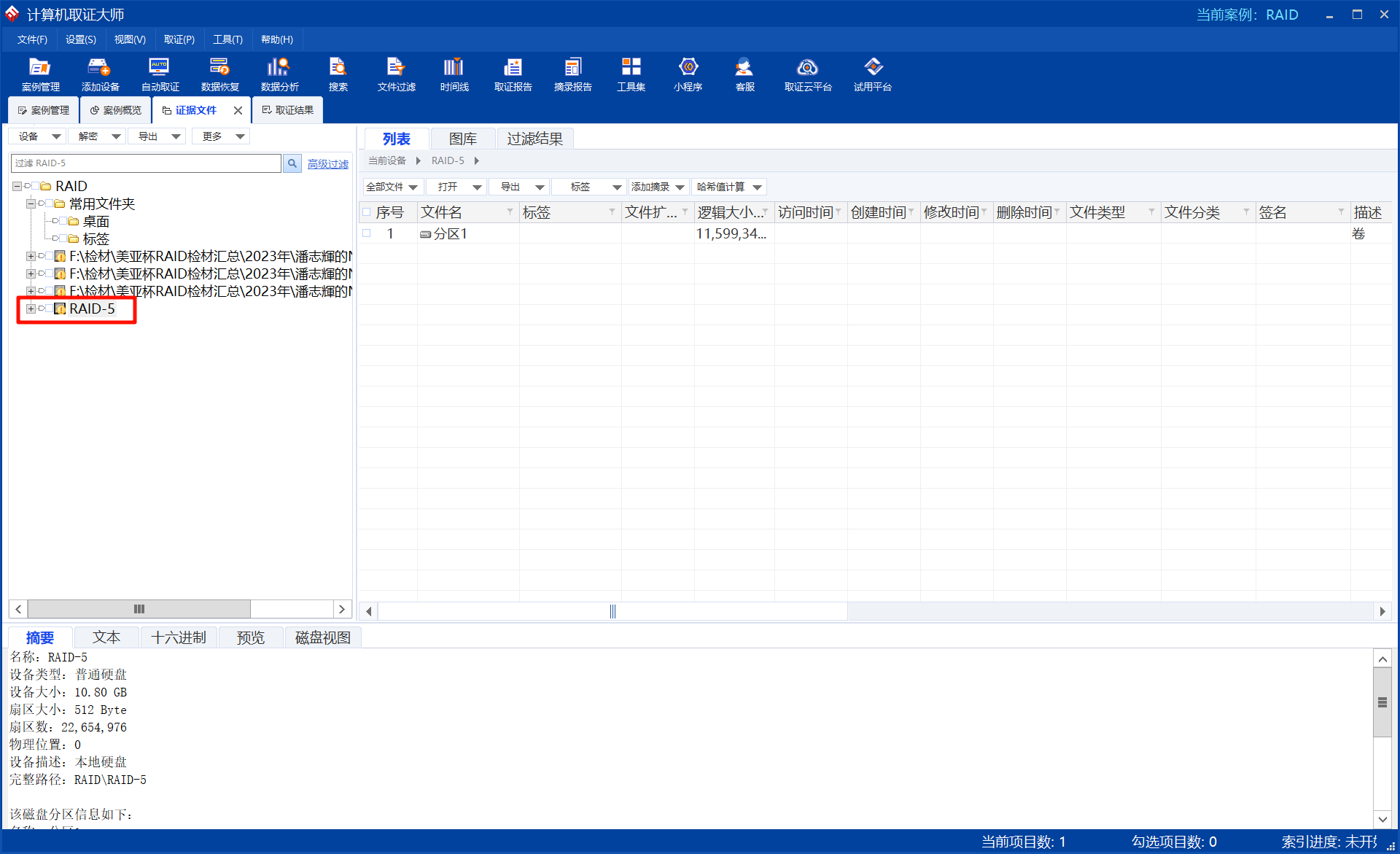
右键选择扫描磁盘结构:
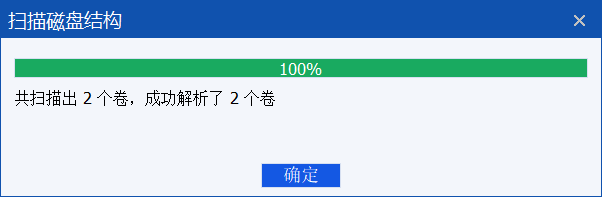
扫完之后会多出来两个卷,就是存储了内容的卷了:
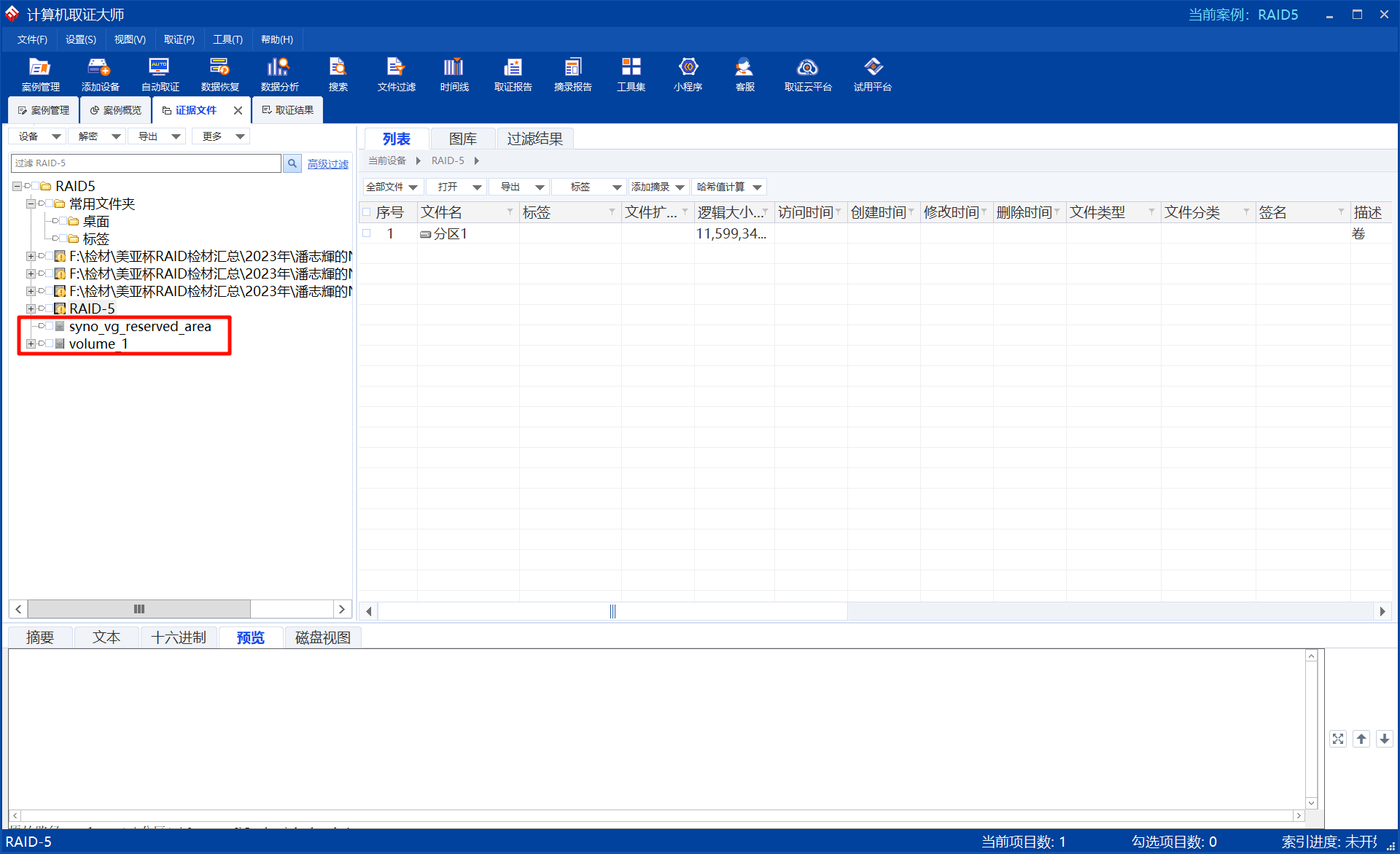
点击卷就能查看文件系统:

看别人说其实还需要右键RAID5,选择RAID重组:
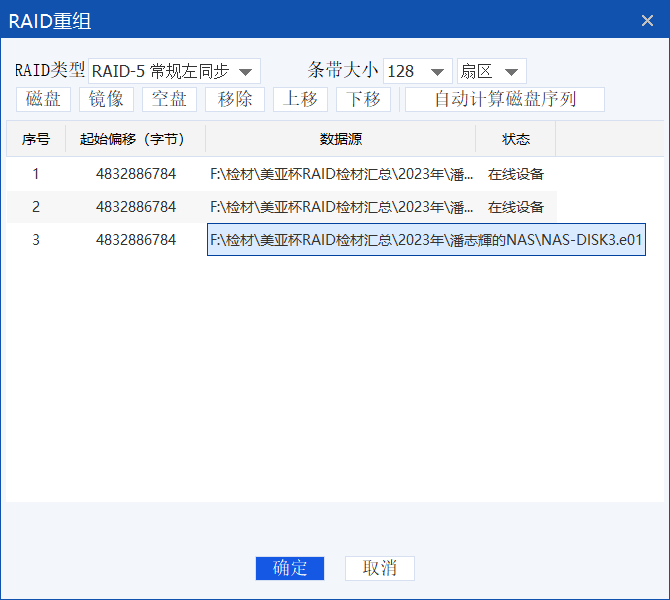
这里也能看见三个盘的起始的偏移量都是4832886784字节,条带大小是128扇区,符合RAID5的规范
但回顾之前使用USF的分析结果,那边说偏移量是9439232扇区,64KB
其实这里涉及到计算:一个扇区的大小是512字节
(以防你是跳着看的:扇区 )
由此能计算出他们其实是一样的:
偏移量 = 9439232扇区*512字节 = 4832886784字节
条带大小 = 128扇区*512字节 = 65536字节 = 64K字节
据说重组后才能看到文件系统,不过我做的过程里只需要扫描磁盘结构之后就能看到了,不知道这一步是什么意思,可能是方便之后导出镜像?
总之以后注意一下,遇到问题再重组一下
导出镜像
右键RAID5选择制作镜像文件:
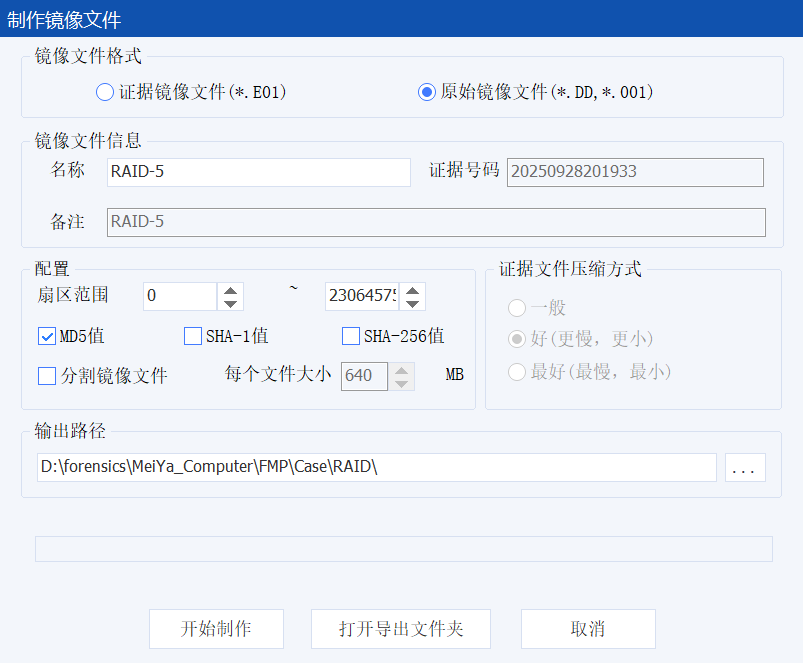
这里可以选择镜像文件的格式:
导出后还会附赠一个说明文档:
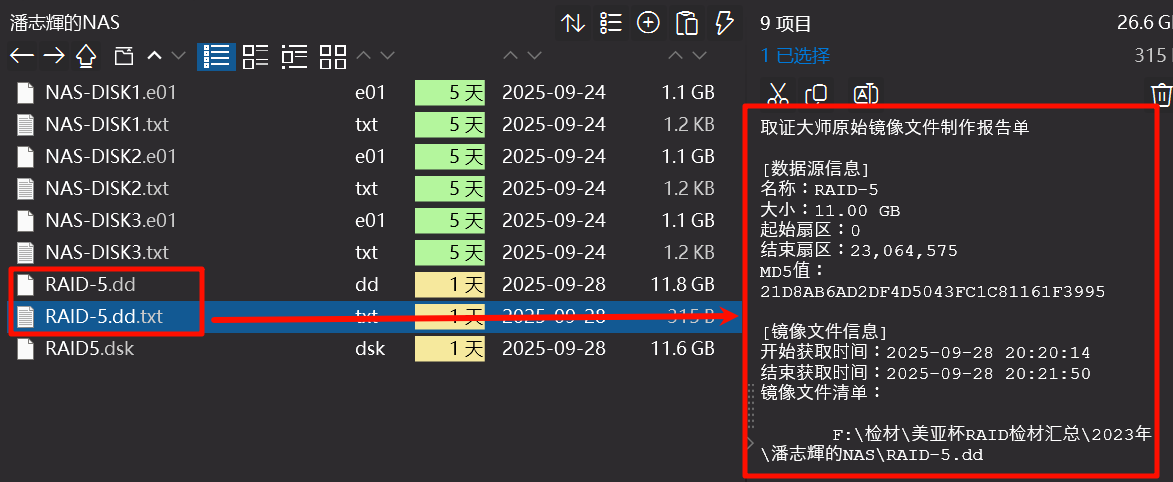
火眼能够正常解析:
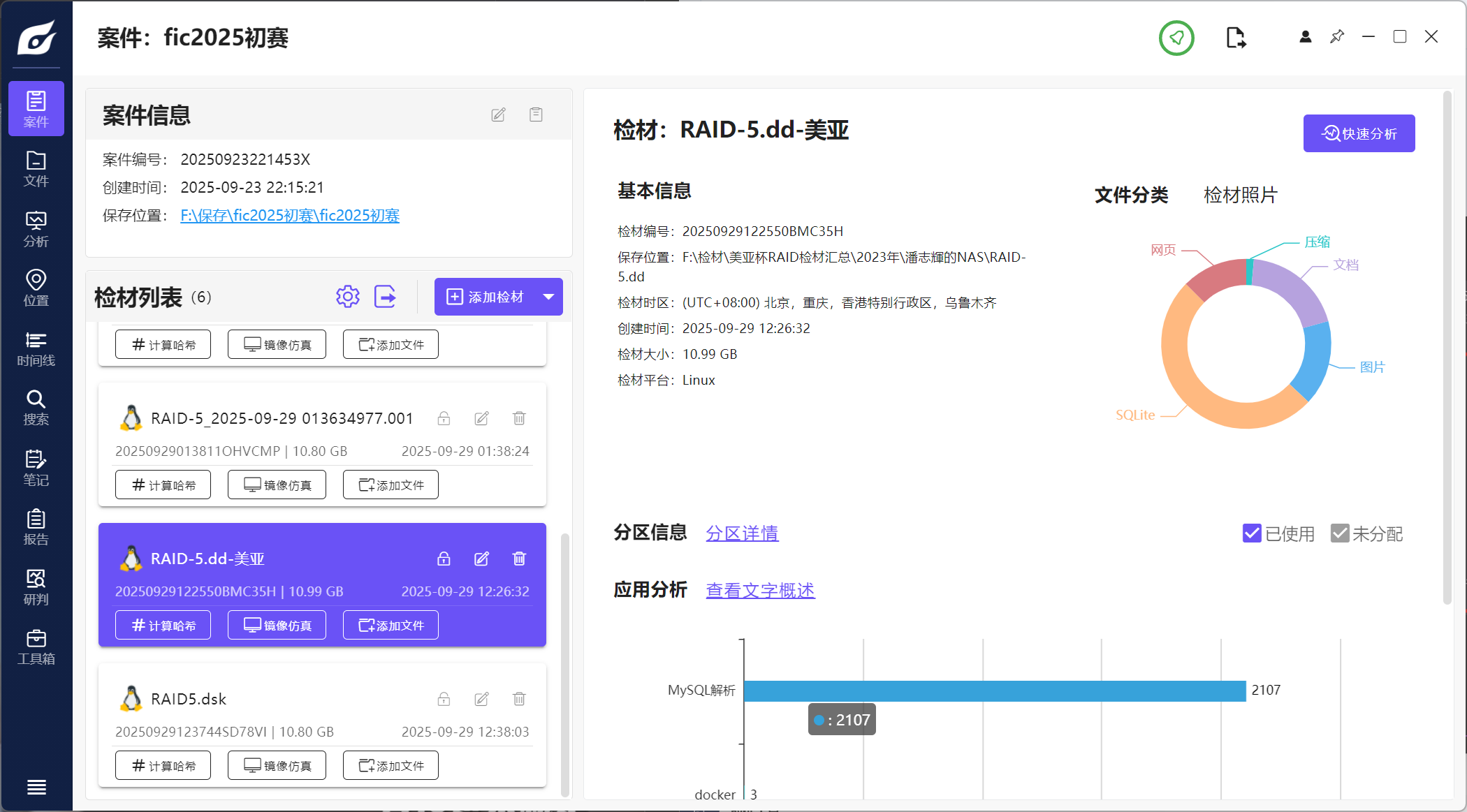
弘连火眼证据分析
自动重组 + 导出镜像
需要在工具箱里面下载使用:

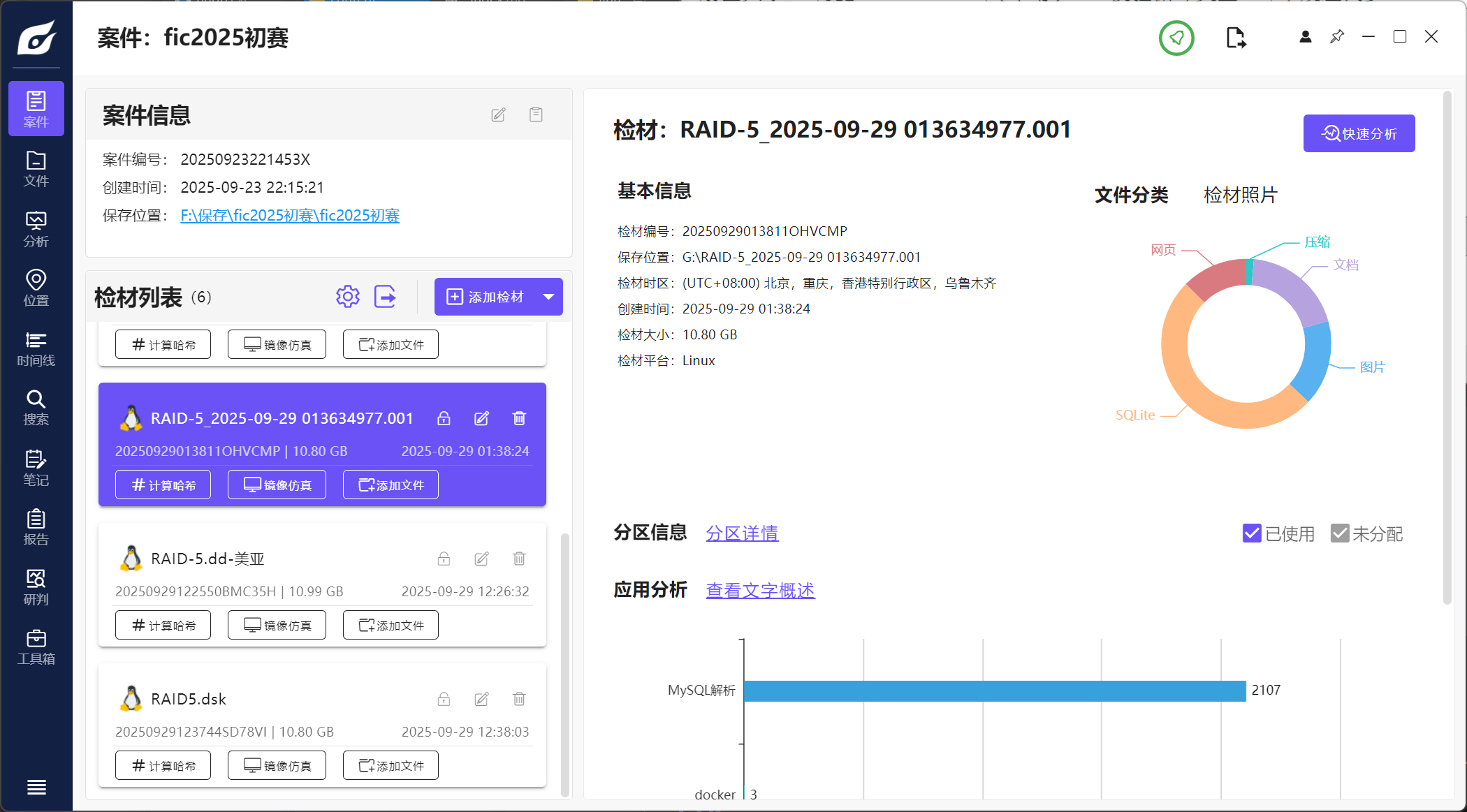
使用信息查询能快速分析RAID的各种信息:
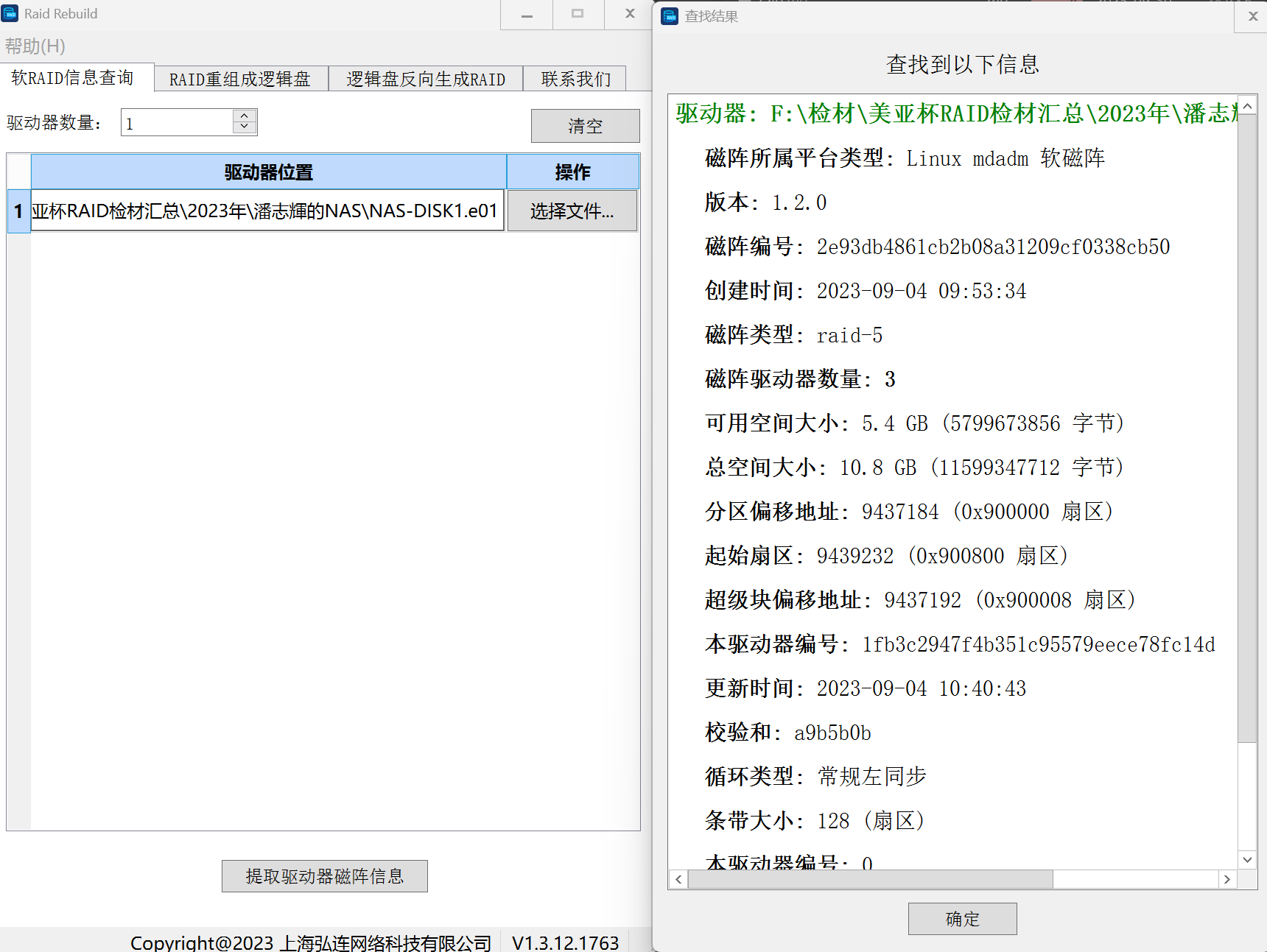
这里也是使用扇区来表示偏移量的
使用重组功能,勾选自动解析,就能自动重组了:

导出的文件是.001格式,会放在一个火眼生成的虚拟驱动器里:
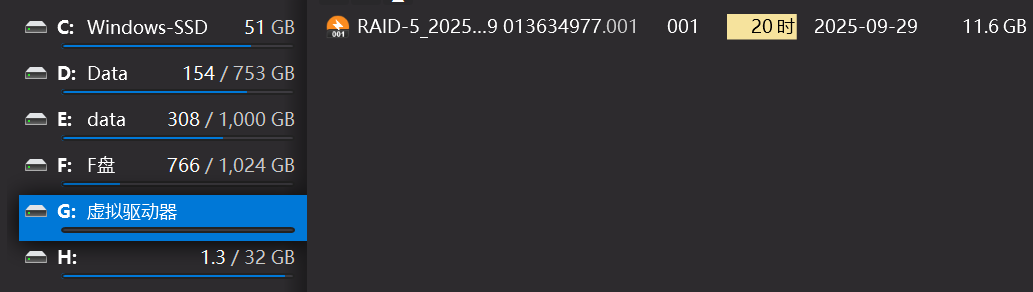
这个文件也是能被正常解析的:
比较坑的是生成的虚拟驱动器想要关掉很麻烦,火眼没有这个功能,windows的磁盘管理也看不见这个驱动器
试了好几次,我的步骤是:
1.手动删除生成的镜像(剪切也行,反正别让他在里面,让这个虚拟驱动器里面没有东西)
2.在重组页面点击“清空”,把拖进去重组的镜像都删除
3.再次点击生成文件,此时提示找不到信息,虚拟驱动器也随之消失了
据客服所说,关掉RAID重组工具页面就会自动卸载,不过我没试过
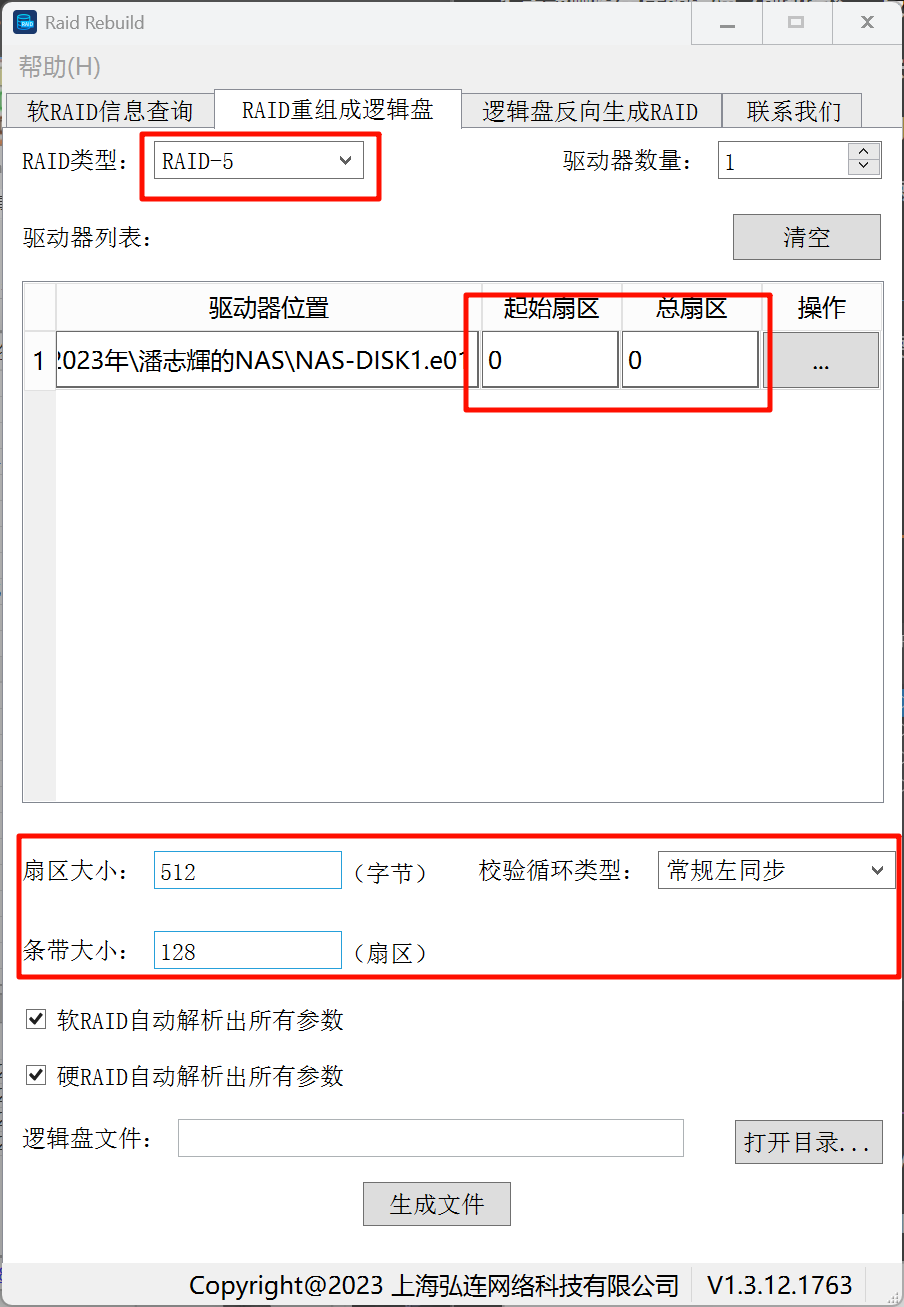
手动重组
没什么好说的,就是自己填写各个必要的数据:
R-Studio
一定要是Technician80+版本的才支持e01格式
为什么把它放最后呢,因为实在太慢了
自动重组
点击打开镜像,把三个镜像都导进去:
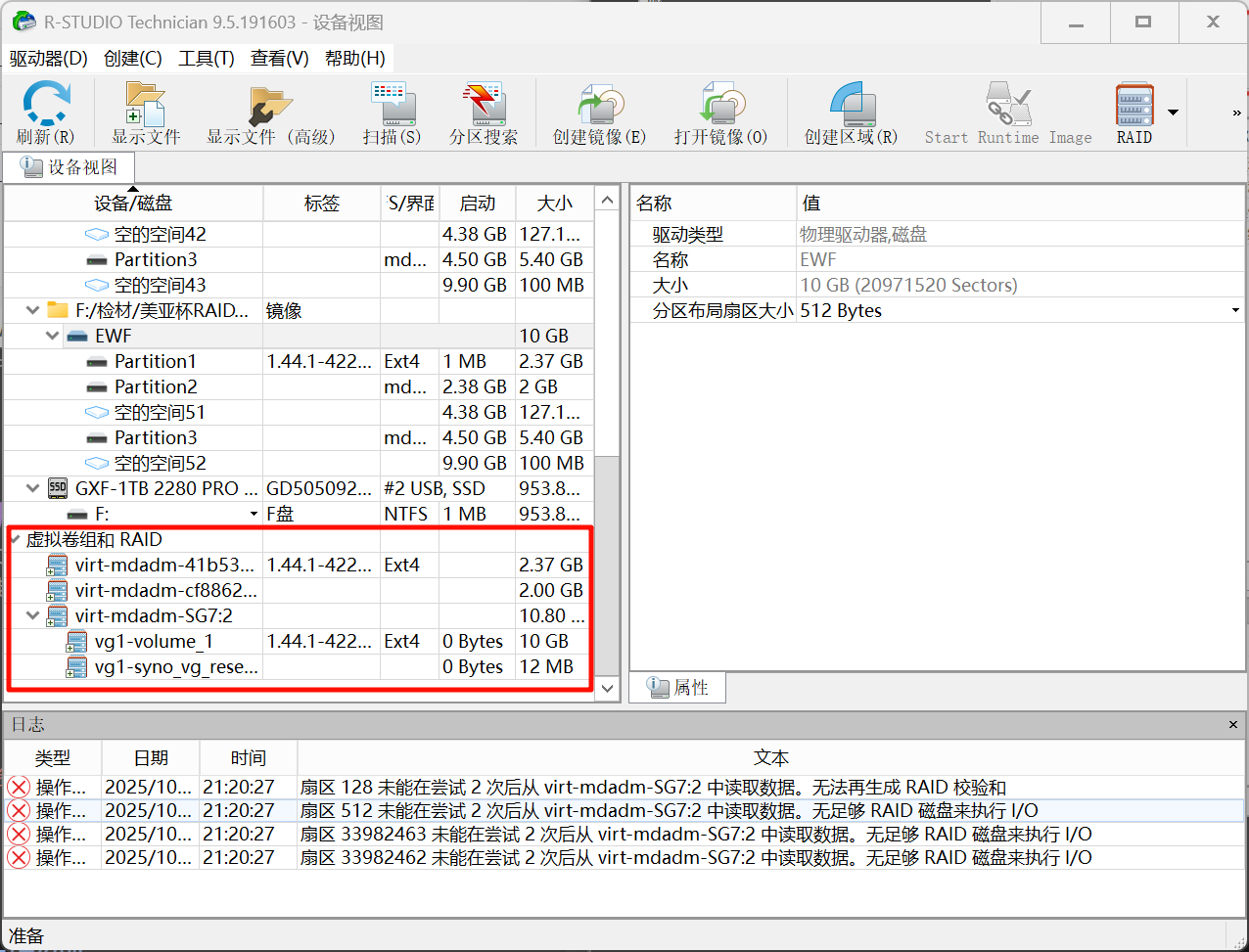
可以看见自动重组出来了:
手动重组
在RAID选择“创建虚拟块RAID和自动检测”
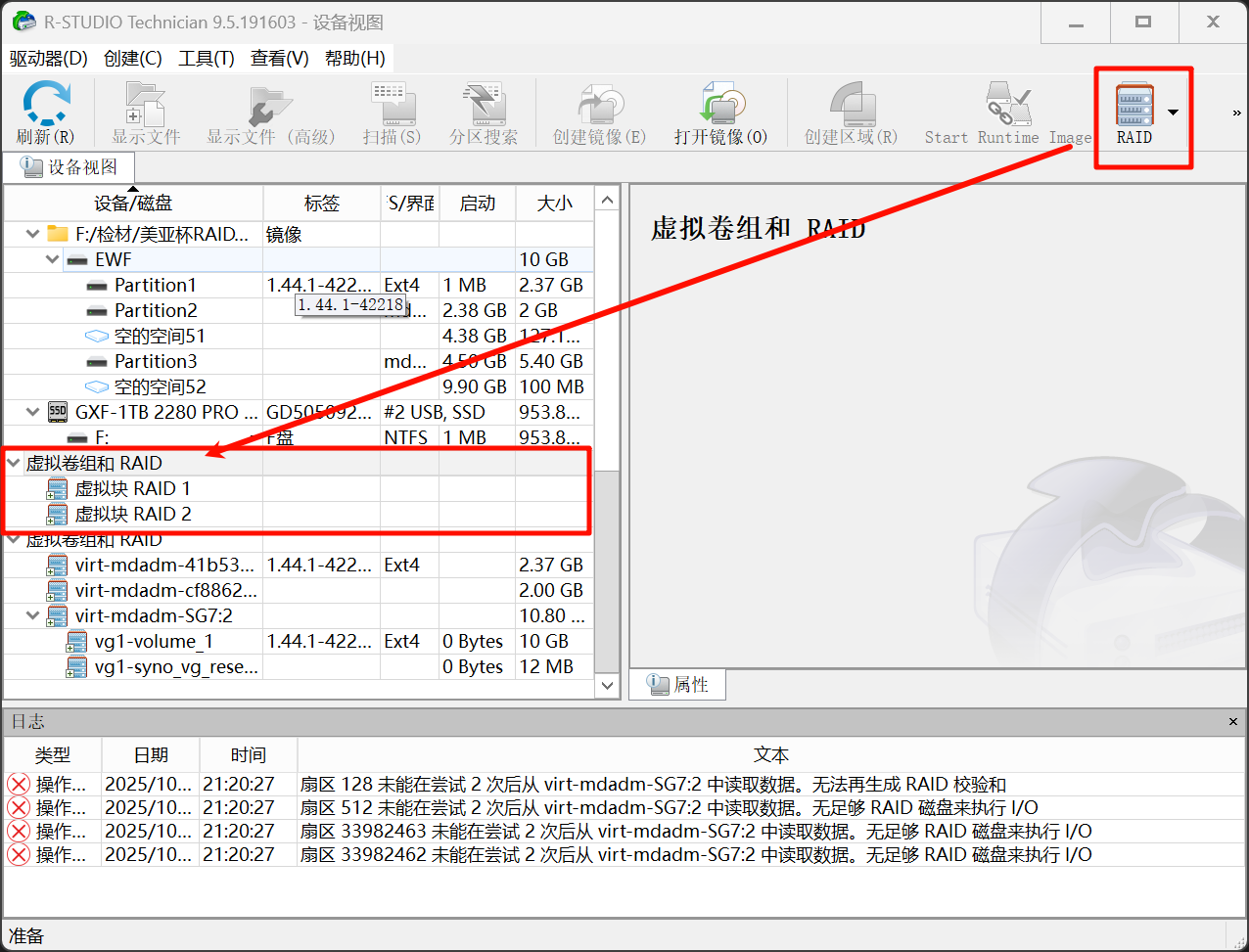
右键要重组的镜像,选择添加到RAID块
这里因为我上一步创建了两个,所以有两个选项,把他们都添加进同一个块就行:
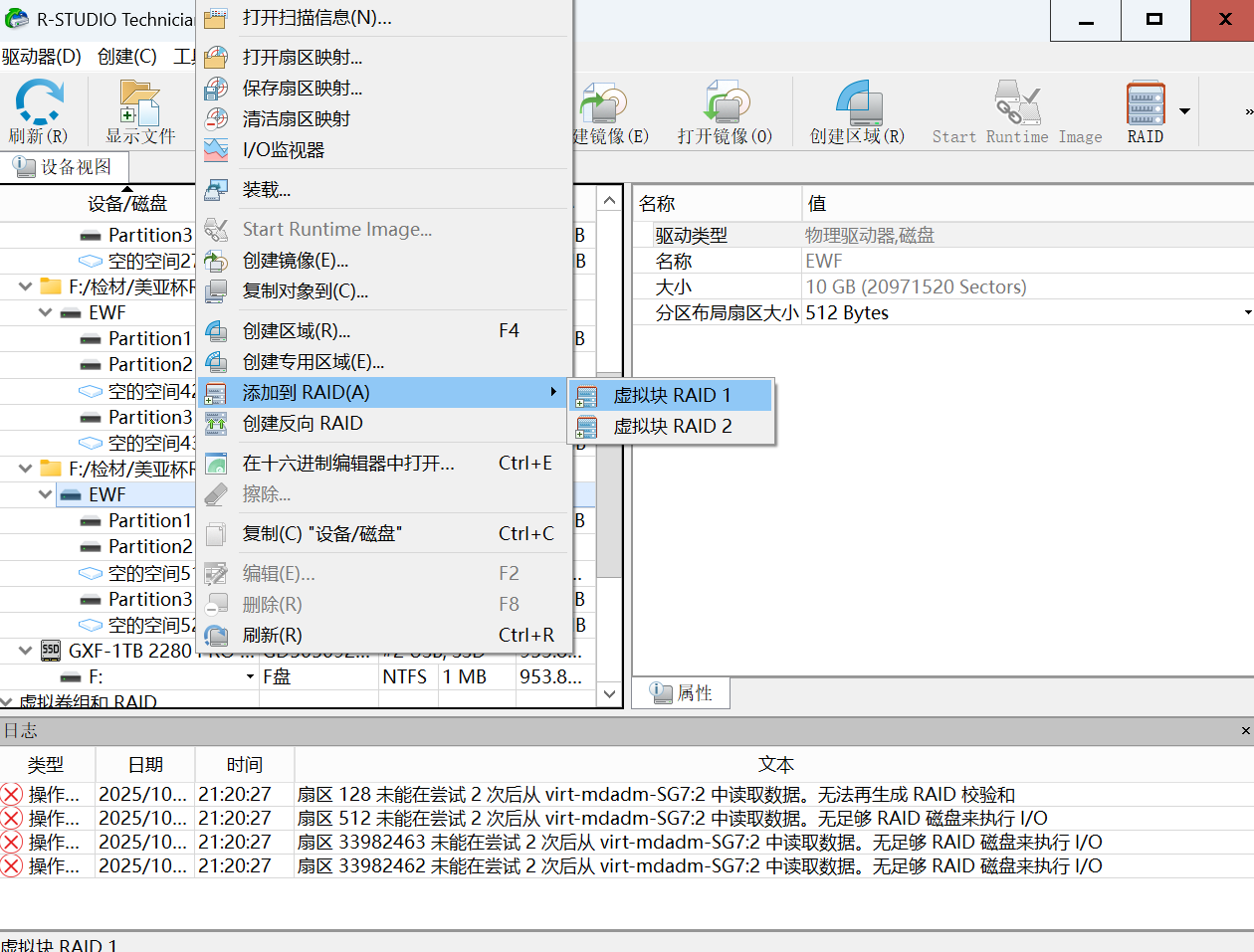
全部导入是这样的:

右侧就是需要我们编辑的东西:RAID类型、块顺序、行数、数据块大小、偏移
当然也可以点击自动检测(就在参数那儿呢),不过过程非常非常漫长,不知道为什么明明自动重组那么快的
导出镜像
右键重组好的镜像,选择创建镜像:
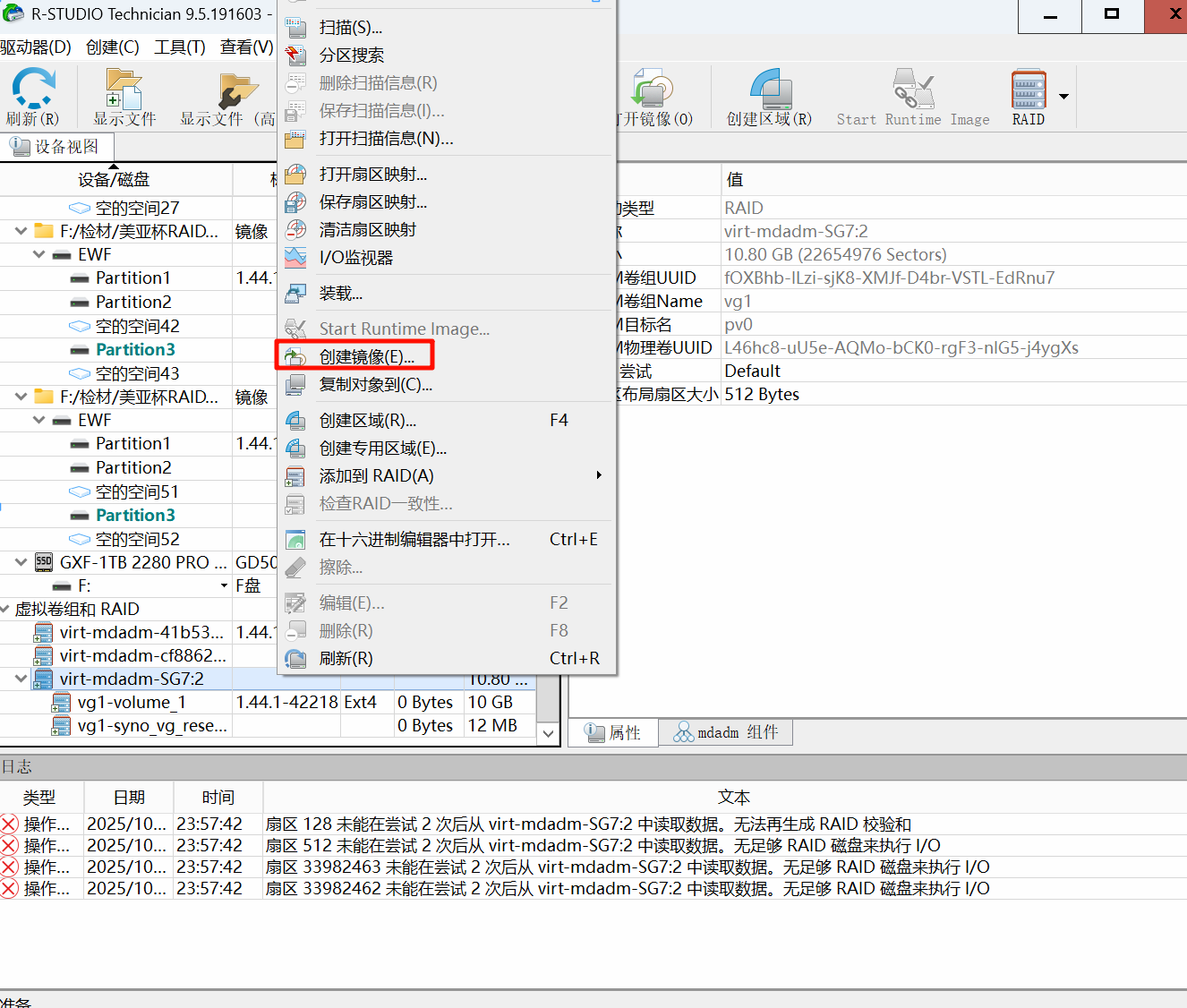
选择导出的类型以及位置,推荐btb类型的(默认是一个压缩文件形式):
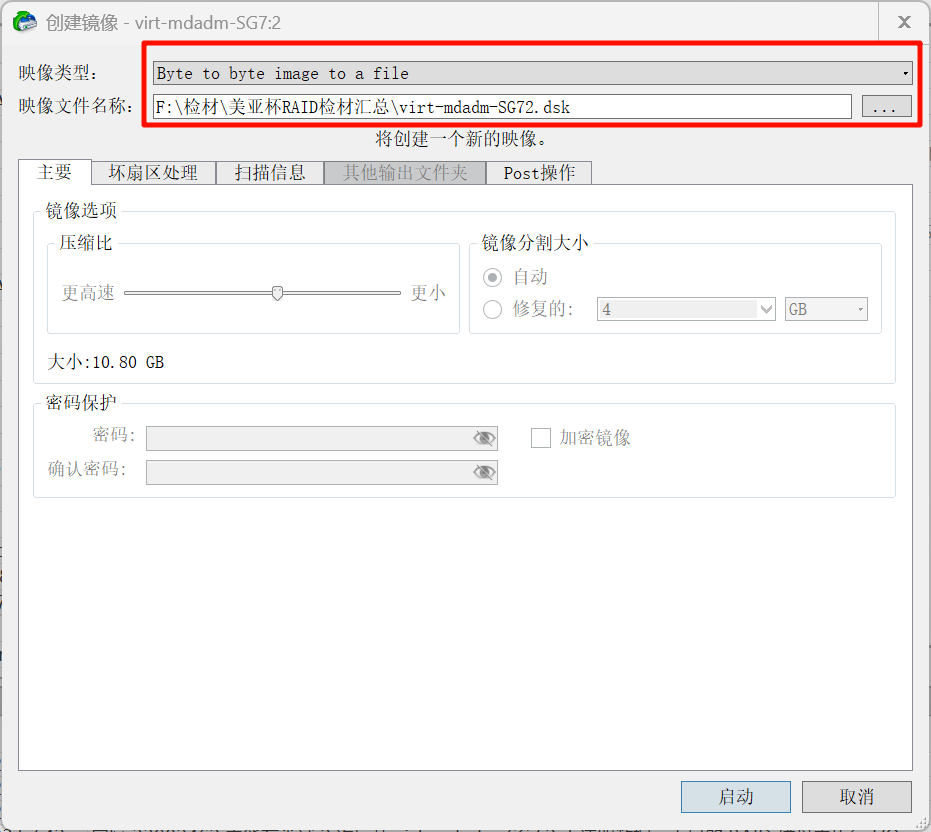
导出要花个几分钟,能被正常解析,没问题:
2019美亚
给出的是四个机械硬盘镜像

FTK + 美亚取证大师
没找到其他办法,可能是因为这是硬RAID?
使用FTK挂载这四个镜像(选择每个盘的.E01就可以,后面的会自动识别的):
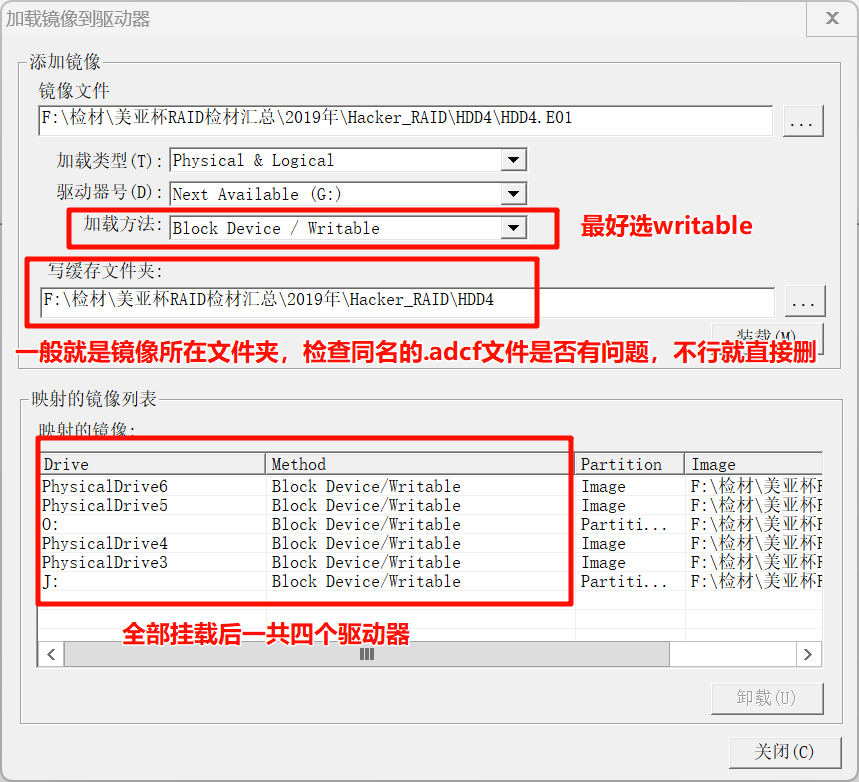
挂载完成后可以在检材目录下看见一个.adcf文件:
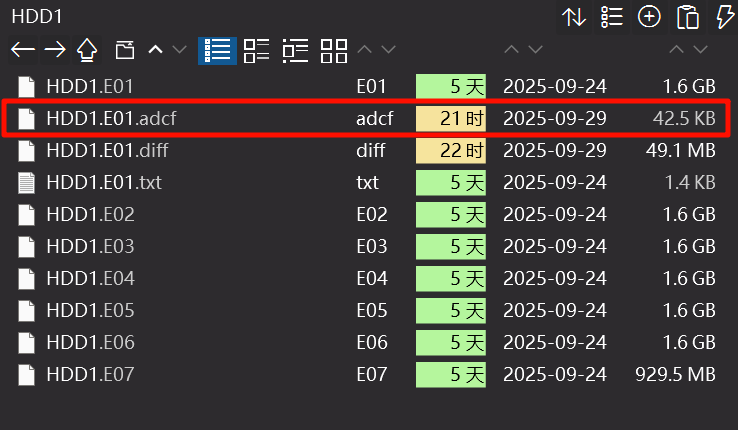
这个.adcf文件是FTK创建的缓存/差异文件
使用writable(可写入)模式时,为了保护原文件不被修改,FTK会把所有写入操作都记录在这个文件中
挂载过程里你可能可能看见这样的错误提示:
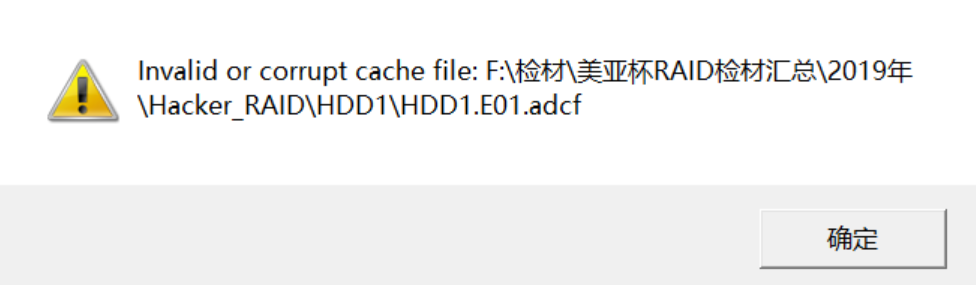
错误提示表明这个已经存在的HDD1.E01.adcf文件已经损坏,删掉再挂载即可,会生成一个新的
不知道为什么,挂载之后在文件管理器可以看见,但在磁盘管理看不见这两个驱动器:
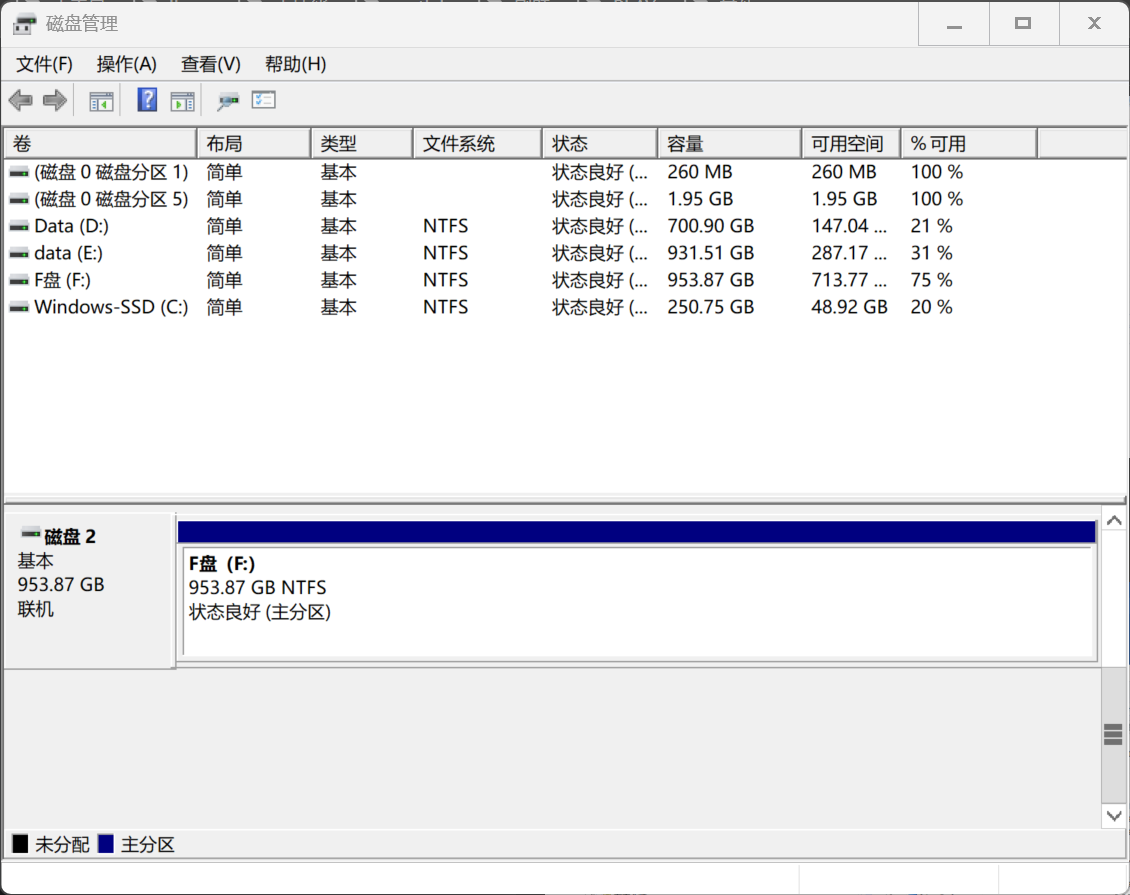
无伤大雅,美亚是可以识别到的:

全都勾选后,自动计算序列,要一点时间:
只有一种可能啊,那就是正确的了:
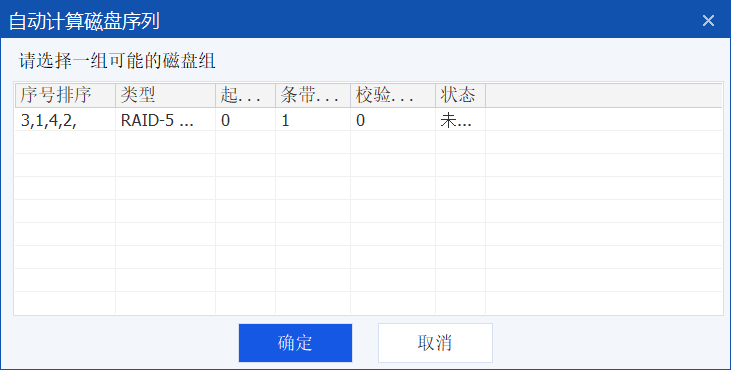
双击应用这个序列:

已经还原了:
这几个磁盘都很大,或许是挂载之后让美亚重组更方便了,才能如此迅速扫出来